2. metoda de simulare monte carlo
TRANSCRIPT

2. Metoda de simulare Monte Carlo 2.1. Introducere
2.2. Generarea fără calculator a valorilor variabilelor probabiliste
2.3. Ideea de bază a metodei Monte Carlo
2.4. Generatori de numere pseudoaleatoare
2.5. Utilizarea metodei Monte Carlo pentru generarea valorilor
variabilelor probabiliste
2.5.1. Distribuţii de probabilitate
2.5.2. Obţinerea de selecţii simulate în cazul variabilelor
probabiliste discrete
2.5.3. Obţinerea de selecţii simulate în cazul variabilelor
probabiliste continue
2.6. Concluzii

2. Metoda de simulare Monte Carlo
2.1. Introducere
În perioada de dezvoltare a energiei atomice de după cel de al doilea război mondial s-a ajuns la necesitatea rezolvării problemei de difuzie a neutronului sau a transportului neutronului într-un mediu izotrop (mediu care are aceleaşi proprietăţi în orice direcţie). Această problemă modelată ca un sistem de ecuaţii diferenţiale parţiale s-a dovedit foarte dificil de rezolvat prin ecuaţii cu diferenţe7.
Exista însă un rezultat prin care se stabilea analogia dintre ecuaţiile integro-diferenţiale şi procesele stochastice. În acest context, John von Neumann şi Stanislaw Ulam de la Los Alamos National Laboratory (S.U.A.) au sugerat că s-ar putea obţine o aproximaţie utilizabilă a soluţiei căutate prin realizarea de experimente bazate pe numere aleatoare efectuate pe calculatoare digitale. Ei au denumit această metodă Monte Carlo după cazinourile de la Monte Carlo ale căror rulete pot fi considerate instrumente de generare a numerelor aleatoare.
Această propunere a inversat modul de raţionament de până atunci. În locul utilizării ecuaţiilor cu diferenţe pentru a obţine soluţii ale problemelor probabiliste, se generează selecţii prin experimente cu numere aleatoare pentru a se obţine soluţii ale unor ecuaţii integro-diferenţiale, care nu sunt în mod necesar de natură probabilistă. Punerea în practică a metodei propuse de von Neumann şi Ulam a fost posibilă şi datorită progreselor obţinute în acea perioadă în domeniul calculatoarelor digitale.
Deşi decepţional de simplă în concept, metoda Monte Carlo furnizează soluţii aproximative pentru o mare varietate de probleme matematice. O caracteristică importantă a metodei Monte Carlo constă în faptul că dintre metodele numerice care se bazează pe evaluarea a n puncte într-un spaţiu m dimensional pentru a obţine o soluţie aproximativă, metoda
Monte Carlo permite estimaţii a căror eroare absolută descreşte cu n-1/2 pe
7 Fishman, S.G., Monte Carlo: concepts, algorithms, and applications. Springer-Verlag New York Berlin Heidelberg, 1997, pag. 1-4

Simulări în afaceri
când toate celelalte estimaţii au erori ce descresc cu n-1/m cel mult. În plus, timpul de lucru al metodei Monte Carlo creşte polinomial cu numărul de variabile m, pe când la alte metode timpul de lucru creşte exponenţial în raport cu m.
În prezent, metoda de simulare Monte Carlo se aplică din ce în ce mai mult în domeniul afacerilor, pentru analiza problemelor stochastice sau în condiţii de risc, atunci când aceeaşi direcţie de acţiune poate avea mai multe consecinţe, ale căror probabilităţi se pot estima.
Variabilele ale căror valori nu sunt cunoscute cu certitudine, dar pot fi descrise prin distribuţii de probabilitate se numesc variabile stochastice sau probabiliste. În simulare, pentru a imita variabilitatea unei astfel de variabile este necesară generarea valorilor posibile pe baza distribuţiei sale de probabilitate.
Probabilităţile au un rol important în modelarea situaţiilor în care intervin mărimi stochastice. În simulare, cunoştinţele despre probabilităţi sunt necesare atât în faza de construire a modelului de simulare cât în faza de analiză a rezultatelor simulării.
Probabilităţile pot fi obţinute în mai multe moduri. Cea mai simplă este metoda subiectivă, prin care experţii estimează pe o scară de la zero la unu probabilitatea ca un anumit eveniment să se realizeze [23, 39]. O altă metodă este metoda obiectivă sau metoda bazată pe frecvenţele relative care utilizează datele istorice sau obţinute prin măsurarea directă a valorilor unei mărimi stochastice.
Pentru construirea distribuţiei de probabilitate a unei variabile stochastice sau probabiliste pe baza datelor istorice sau obţinute prin măsurare directă se poate aplica o procedură formată din trei etape:
1. Colectarea datelor referitoare la valorile variabilei probabiliste.
2. Gruparea datelor pe intervale şi construirea histogramei frecvenţelor relative.
3. Analiza graficului histogramei frecvenţelor relative pentru a stabili dacă seamănă cu forma unei distribuţii teoretice cunoscute. Tipul distribuţiei de probabilitate poate fi apreciat prin teste de concordanţă (Kolmogorov, Smirnov, Pearson sau χ2) care măsoară apropierea dintre distribuţia teoretică şi distribuţia valorilor variabilei probabiliste obţinute din seriile de

Simulări în afaceri
date istorice sau prin măsurare. În final, se calculează parametri distribuţiei.
Testul Pearson (χ2) calculează pe baza distribuţiei frecvenţelor teoretice fti şi a distribuţiei frecvenţelor fsi obţinute prin simulare statistica:
χ2calculat = ∑=
−k
1i ft)fsft(
i
2ii .
Dacă χ2calculat < χ2α,ν, atunci se poate considera că există concordanţă între
cele două distribuţii comparate, pentru un nivel de semnificaţie α şi numărul de grade de libertate ν = k – c – 1, unde k este numărul intervalelor de valori pentru care s-au determinat frecvenţele fti şi fsi, iar c reprezintă numărul
parametrilor distribuţiei de probabilitate analizate. Valoarea lui χ2α,ν se citeşte
din tabele.
Testul χ2 nu se poate aplica dacă există frecvenţe fsi <5.
Testul Kolmogorov – Smirnov calculează pentru fiecare interval i de valori, diferenţele absolute dintre funcţia Fti teoretică de probabilitate cumulată şi funcţia Fsi de probabilitate cumulată obţinută prin n experimente de simulare şi dacă:
max {|Ft1 – Fs1|, |Ft2 – Fs2|, ...,|Ftk – Fsk|} < (1,36/√n),
atunci se poate considera că există concordanţă între cele două distribuţii comparate, pentru un nivel de semnificaţie α = 0,05 şi n >30.
Există două categorii de variabile probabiliste şi anume variabile probabiliste discrete şi variabile probabiliste continue.
Variabilele probabiliste discrete pot avea numai valori specifice (de exemplu numai valori întregi), iar variabilele probabiliste continue pot avea orice valoare reală într-un interval şi prin urmare numărul valorilor posibile este infinit.
Simulări în afaceri
2.2. Generarea fără calculator a valorilor variabilelor probabiliste
Generarea valorilor variabilelor probabiliste reprezintă „motorul” unui model de simulare. Prin extragerea la întâmplare a unui eşantion din distribuţia de probabilitate care descrie comportamentul unei variabile probabiliste se reproduce în modelul de simulare caracterul aleator al variabilei necontrolabile de decident. Pentru a ilustra modul în care se pot extrage la întâmplare valorile unei variabile probabiliste se va prezenta un exemplu de simulare a vânzărilor săptămânale de calculatoare PC într-un centru comercial. Acest exemplu nu se referă la o problemă de decizie, de aceea nu sunt definite variantele decizionale controlabile de decident. Exemplul 2.1. Tabelul 2.1 prezintă vânzările de calculatoare PC ale centrului comercial ALFA în ultimele 30 de săptămâni.
Tabelul 2.1
Număr curent i
Calculatoare vândute pe săptămână
xi
Număr de săptămâni fi
1 2 3 4 5
0 1 2 3 4
6 12 6 3 3
Pentru a simula cererea săptămânală de calculatoare se va determina distribuţia de probabilitate a cererii săptămânale utilizând frecvenţa relativă a cererii în cele 30 săptămâni, adică P(xi) = fi/30.
Tabelul 2.2
Număr curent i
Calculatoare vândute pe săptămână
xi
Probabilitatea cererii P(xi)
1 2 3 4 5
0 1 2 3 4
0,20 0,40 0,20 0,10 0,10

Simulări în afaceri O modalitate de a genera numărul de calculatoare care se vor vinde într-o anumită săptămână ar putea fi următoarea:
- Se pregătesc 100 de bilete de hârtie de aceeaşi culoare şi dimensiune.
- Pe 20 dintre ele se scrie numărul 0, pe 40 bilete se scrie numărul 1, pe alte 20 bilete se scrie numărul 2, pe 10 bilete se scrie numărul 3, iar pe alte 10 bilete se scrie numărul 4.
- Se împăturesc biletele cu partea scrisă spre interior şi se amestecă într-un bol.
- Se extrage un bilet şi se citeşte numărul de pe bilet. Evident, şansa cea mai mare de a fi extras îi aparţine numărului 1.
- Se introduce din nou în bol biletul împăturit şi extragerea se va repeta de mai multe ori pentru a se reproduce vânzările reale.
Altă modalitate de generare a vânzărilor dintr-o săptămână constă în folosirea ruletei (Figura 2.1). După punerea în mişcare, acul indicator se poate opri cu aceeaşi probabilitate în dreptul oricărui punct de pe circumferinţa ruletei.
- Se împarte circumferinţa discului în 100 diviziuni egale, numerotate de la 0 la 99.
- Se împarte discul ruletei în sectoare ale căror arii corespund probabilităţilor asociate diferitelor valori ale cererii săptămânale de calculatoare.
- Se pune în funcţiune acul indicator. Dacă acul se opreşte într-un anumit sector se va considera că s-a generat numărul de calculatoare asociat acelui sector.
- Acul indicator va fi acţionat de mai multe ori pentru a reproduce variabilitatea vânzărilor reale.
Se observă că pentru a genera numărul xi de calculatoare PC, a fost
necesar mai întâi să se asocieze fiecărei cantităţi un anumit număr de diviziuni: numărului x1 = 0 îi corespund diviziunile numerotate de la 0 la
19, adică 20% din numărul total de diviziuni; numărului x2 = 1 îi corespund
diviziunile numerotate de la 20 la 59, adică 40% din numărul total de diviziuni; numărului x3 = 2 îi corespund diviziunile numerotate de la 60 la

Simulări în afaceri
79, adică 20% din numărul total de diviziuni; numărului x4 = 3 îi corespund
diviziunile numerotate de la 80 la 89, adică 10% din numărul total de diviziuni; numărului x5 = 4 îi corespund diviziunile numerotate de la 90 la
99, adică 10% din numărul total de diviziuni. Rezultă că proporţia numerelor de diviziuni asociate fiecărei cantităţi xi este egală cu
probabilitatea de vânzare a cantităţii xi, adică modul de împărţire a discului
ruletei în sectoare corespunde distribuţiei de probabilitate care descrie vânzările săptămânale de calculatoare.
Figura 2.1
Deşi uşor de înţeles, metodele bazate pe bilete numerotate sau pe ruletă ar fi dificil de utilizat pentru generarea unui număr mare de valori
2 3 4 5 6 78 9
1011
1213
1415
1617
1819
20
2122
2324
25
2627
2829
30
3132
3334
3536
3738
3940
4142
434445464748495051525354555657
585960
6162
6364
6566
6768
69
70
7172
7374
75
7677
7879
80
8182
8384
8586
8788
8990
9192
93 9495 96 97 98 0 199
20%x1=0
40%x2=1
20%x3=2
10%x4=3
10%x5=4

Simulări în afaceri pentru x. De aceea, este necesară o altă metodă, care să poată fi implementată pe calculator şi care să selecteze, la întâmplare, valorile unei mărimi stochastice descrise printr-o distribuţie de probabilitate.
Biletele de aceeaşi culoare şi dimensiune au rolul de a acorda fiecărui bilet aceeaşi şansă de a fi extras, indiferent de numărul care îl conţine. Acul ruletei bine calibrat se poate opri cu aceeaşi probabilitate în dreptul oricărei diviziuni numerotate de la 0 la 99, indiferent de sectorul din care face parte acea diviziune.
Biletele de aceeaşi culoare şi dimensiune sau acul ruletei bine calibrat reproduc întâmplarea din sistemul real. Ele sunt înlocuite în programele de simulare pentru calculator cu generatoare de numere aleatoare.
2.3. Ideea de bază a metodei Monte Carlo
Procesul de generare aleatoare a valorilor unei variabile probabiliste este referit în literatura de specialitate ca metoda Monte Carlo şi constă în generarea mai întâi a unui număr aleator şi apoi utilizarea numărului obţinut pentru extragerea unei valori din distribuţia de probabilitate care descrie comportamentul variabilei probabiliste.
Metoda Monte Carlo generează artificial valorile unei variabile probabiliste, prin utilizarea unui generator de numere aleatoare uniform distribuite în intervalul [0, 1] şi a funcţiei distribuţiei cumulative asociată variabilei probabiliste respective.
Un număr aleator este orice număr care poate fi obţinut într-un asemenea mod încât valoarea lui nu poate fi prevăzută dinainte. Astfel, zarurile sau ruleta pot fi folosite pentru a construi tabele de numere aleatoare, dar utilizarea acestora nu este convenabilă pentru simularea pe calculator. De aceea, numerele aleatoare necesare simulării sunt obţinute prin proceduri aritmetice numite generatori.
În această lucrare, pentru numere aleatoare se va utiliza terminologia folosită de obicei de practicienii în domeniul simulării şi anume că numerele aleatoare sunt numere uniform distribuite între 0 şi 1.

Simulări în afaceri
Cei mai mulţi generatori de numere aleatoare implementaţi pe calculatoare sunt de fapt generatori de numere pseudoaleatoare care se comportă ca şi numerele aleatoare în sensul că numere pseudoaleatoare satisfac testul statistic al caracterului aleator, dar sunt predictibile şi reproductibile.
În secţiunea 2.4 va fi prezentat unul din cei mai utilizaţi generatori şi anume generatorul congruenţial liniar.
2.4. Generatori de numere pseudoaleatoare
În secţiunea 2.3 s-a arătat că numerele aleatoare sunt numere uniform distribuite în intervalul [0, 1] şi că, pentru simularea la calculator, este convenabil să se utilizeze proceduri aritmetice numite generatori. Numerele generate de calculator pe baza unor proceduri aritmetice se numesc numere pseudoaleatoare deoarece, deşi şirul de numere obţinut verifică testul caracterului aleator, aceste numere sunt predictibile şi reproductibile. Calitatea rezultatelor simulării depinde calitatea generatorului de numere aleatoare utilizat. Se consideră, [46, 52], că un generator de numere aleatoare este bun dacă îndeplineşte următoarele condiţii:
1) Numerele generate au o perioadă lungă de repetiţie.
2) Numerele generate pot fi reproduse.
3) Şirul de numere nu este degenerat, adică nu conţine unul sau mai multe numere care se repetă. Numerele generate sunt uniform distribuite în intervalul [0, 1].
4) Procedura este rapidă şi nu necesită multă memorie internă de calcul.
5) Produce numere care verifică testul caracterului aleator adică numerele sunt stochastic independente.
Reproductibilitatea este importantă pentru realizarea experimentelor de simulare deoarece permite controlul condiţiilor experimentale. Prin utilizarea aceluiaşi şir de numere aleatoare pentru analiza a două sau mai multe variante decizionale, se va elimina variabilitatea produsă de numerele aleatoare şi se vor putea observa mai uşor diferenţele dintre rezultatele aplicării diferitelor variante. Există un număr mare de metode aritmetice care pot fi utilizate

Simulări în afaceri pentru generarea de numere pseudoaleatoare [3, 52, 61].
Dintre metodele aritmetice de generare a numerelor aleatoare, cele mai studiate din punct de vedere teoretic şi cu bune rezultate practice sunt metodele congruenţiale liniare care se bazează pe clase de resturi. Acest tip de metode utilizează proceduri recursive prin care se generează în numere întregi cuprinse între 0 şi (m-1) care apoi, prin normalizare, se transformă numere uniform distribuite în intervalul [0, 1]. Procedura recursivă constă din trei paşi:
Pasul 1. Alege o valoare iniţială x0
Pasul 2. xi+1 = (axi + c) modulo m
ui+1 = m
1ix +
Pasul 3. Repetă Pasul 2.
Valoarea iniţială x0 se numeşte sămânţă (seed).
xi+1 = (axi + c) modulo m înseamnă că valoarea lui xi+1 este egală
cu restul împărţirii lui (axi + c) la m.
Exemplul 2.2. Se consideră a = 2, c = 3, m = 5 şi x0 = 3. Să se
genereze primele 6 numere pseudoaleatoare.
Rezolvare În Tabelul 2.3 sunt prezentate numerele generate prin metoda congruenţială.
Tabelul 2.3
Nr.crt. xi 2xi + 3 xi+1 = (2xi + 3) modulo 5 ui+1 = m
1ix +
0 3 9 9:5 = 1 rest 4 0,8 1 4 11 1 0,2 2 1 5 0 0 3 0 3 3 0,6 4 3 9 4 0,8 5 4 11 1 0,2
Se observă că şirul de numere se repetă după 4 valori, deci lungimea perioadei în acest caz este (m-1) = 5-1 = 4.

Simulări în afaceri
Pentru a obţine un generator bun este necesar să se aleagă cu atenţie valorile a, c şi m. De exemplu, pentru a = 513, c = 0, m =(231 –1) şi sămânţa 1 ≤ x0 ≤
2147483647, şirul de numere pseudoaleatoare va avea o perioadă cu lungimea de 2147483646 numere, în care fiecare număr apare numai o singură dată. Toate limbajele de programare generale si speciale şi programele comerciale de tip foi de calcul (LOTUS 1-2-3, EXCEL etc.) conţin generatori de numere aleatoare foarte bine verificaţi şi testaţi. Limbajul de programare BASIC are funcţia RANDOMIZE cu sau fără argument pentru a se obţine valoarea iniţială sau sămânţa şi funcţia RND cu sau fără argument pentru o genera un număr aleator între 0 şi 1. În [52] sunt prezentaţi mai mulţi generatori construiţi în limbaj BASIC. În EXCEL, numerele aleatoare uniform distribuite în intervalul [0. 1] se pot obţine cu =RAND().
2.5. Utilizarea metodei Monte Carlo pentru generarea valorilor variabilelor probabiliste
2.5.1. Obţinerea de selecţii simulate în cazul variabilelor probabiliste discrete
Distribuţii discrete de probabilitate În cazul variabilelor discrete de probabilitate, lista valorilor posibile şi a probabilităţilor corespunzătore formează o distribuţie discretă de probabilitate.
În terminologia teoriei probabilităţilor, se poate nota cu X variabila probabilistă cu mai multe valori posibile şi cu xi o anumită valoare
particulară a variabilei X.
Probabilitatea ca valoarea unei variabilei probabiliste X să fie egală cu o anumită valoare xi se notează P(X = xi) = P(xi).

Simulări în afaceri Probabilitatea ca valoarea unei variabilei probabiliste X să fie mai mică sau egală cu o anumită valoare xi se numeşte funcţie de distribuţie
cumulativă şi se notează F(xi):
F(xi) = P(X ≤ xi) = ∑≤ ixv
)v(P pentru -∞ ≤ xi ≤ ∞,
cu proprietatea F(xi) ≤ 1.
Funcţia distribuţiei cumulative F(xi) este suma probabilităţilor
asociate valorilor mai mici sau egale cu xi.
În cazul distribuţiilor empirice, construite pe baza datelor istorice sau prin măsurarea directă a valorilor variabilei probabiliste, valorile variabilelor probabiliste pot fi prezentate sub forma Tabelului 2.4.
Tabelul 2.4
Valoarea variabilei probabiliste xi
Frecvenţa de apariţie fi
x1 x2 ...
xm
f1 f2 ... fm
Frecvenţele relative vor fi folosite pentru a calcula probabilităţile
P(X=xi) = P(xi) = fi/ ∑=
m
1kkf , pentru i=1,...,m, iar funcţia de distribuţie
cumulativă F(xi) = P(X ≤ xi) se obţine prin cumularea probabilităţilor.
Uneori, este posibil ca distribuţiile discrete de probabilitate să fie descrise prin funcţii matematice numite funcţii de masă de probabilitate [46].
Cele mai utilizate distribuţii teoretice discrete de probabilitate sunt distribuţia uniformă discreta, distribuţia binomială şi distribuţia Poisson
Distribuţia uniformă discretă descrie variabilele cu un număr mic de valori posibile, fiecare cu aceeaşi probabilitate de realizare.
Dacă numărul valorilor posibile este n, iar mulţimea valorilor posibile este {x1, x2, ..., xn}, atunci funcţia de masă de probabilitate este

Simulări în afaceri
P(X=xi) = P(xi) = 1/n pentru orice valoare xi,
iar funcţia distribuţiei cumulative este F(xi) = P(X ≤ xi) = i/n, pentru i = 1, 2, ..., n.
Distribuţia binomială este o distribuţie discretă de probabilitate care se aplică atunci când există numai două rezultate posibile: succes sau eşec, admis sau respins, promovat sau nepromovat etc. De exemplu, variabila probabilistă este numărul experimentelor cu „succes”. Dacă probabilitatea p a „succesului” este aceeaşi pentru fiecare din cele n experimente, iar experimentele sunt independente, atunci funcţia de masă de probabilitate este definită prin probabilitatea ca numărul experimentelor de succes să fie egal cu o anumită valoare xi şi poate fi calculată cu expresia:
P(X=xi) = P(xi) = ixnC pxi(1-p)n-xi pentru xi = 0, 1, 2, ..., n,
unde n este numărul total de experimente.
Funcţia distribuţiei cumulative este:
F(xi) = P(X ≤ xi) = ∑=
ix
0v)v(P pentru xi = 0, 1, 2, ..., n
Media µ = np
Dispersia σ2 = np(1-p) Distribuţia Poisson este o distribuţie discretă de probabilitate care se aplică în cazul unor evenimente întâmplătoare independente. Variabila probabilistă este numărul de evenimente care pot avea loc într-o perioadă de timp. Astfel, numărul persoanelor care sosesc într-o staţie de servire într-un interval de o oră pentru a solicita un serviciu (clienţi la un ghişeu de bancă, autoturisme la o staţie de benzină etc.) este o variabilă probabilistă al cărui comportament poate fi descris de o distribuţie Poisson. Funcţia de masă de probabilitate pentru această distribuţie este probabilitatea ca numărul evenimentelor care au loc într-un interval de timp specificat să fie egal cu o anumită valoare xi şi poate fi calculată cu
expresia:
P(X = xi) = P(xi) = !ix
exi λ−λ

Simulări în afaceri unde λ este numărul mediu al evenimentelor dintr-un interval de timp specificat, iar e = 2,7182818. Funcţia distribuţiei cumulative este:
F(xi) = P(X ≤ xi) = ∑=
ix
0v)v(P pentru xi = 0, 1, 2, ..., N
Media µ = λ
Dispersia σ2 = λ
Procedura pentru aplicarea metodei Monte Carlo în cazul variabilelor probabiliste discrete
Pentru obţinerea de selecţii simulate cu metoda Monte Carlo se poate aplica următoarea procedură:
Pasul 1. Se calculează probabilităţile P(X=xi) = P(xi) şi funcţia de distribuţie cumulativă F(xi) = P(X ≤ xi) = ∑
≤ ixv)v(P , pentru xi ∈ {x1, x2, ..., xm}.
În cazul distribuţiilor discrete teoretice, se vor folosi funcţiile matematice corespunzătoare care definesc funcţiile de masă de probabilitate pentru calculul probabilităţilor P(X=xi) = P(xi) şi funcţiile F(x) de distribuţie cumulativă.
Pasul 2. Se asociază intervale de numere aleatoare fiecărei valori a variabilei discrete. Acest lucru se poate realiza grafic sau tabelar.
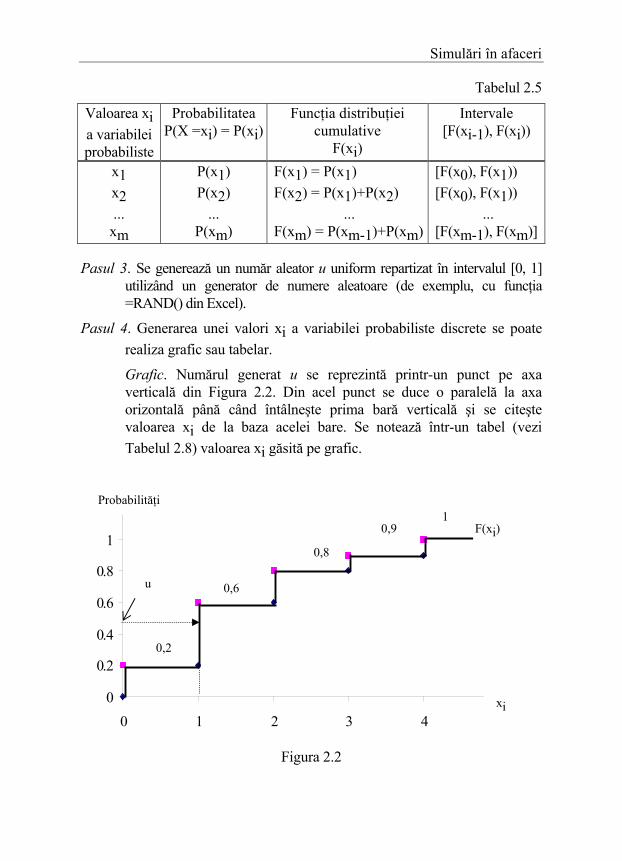
Grafic. Se reprezintă funcţia de distribuţie cumulativă a variabilei discrete analizate. În Figura 2.2, se observă că în cazul variabilelor probabiliste discrete, funcţia F(xi) are forma unor trepte. Înălţimea fiecărei trepte faţă de treapta precedentă este egală probabilitatea P(xi) şi cu lungimea intervalului de numere aleatoare asociat valorii xi.
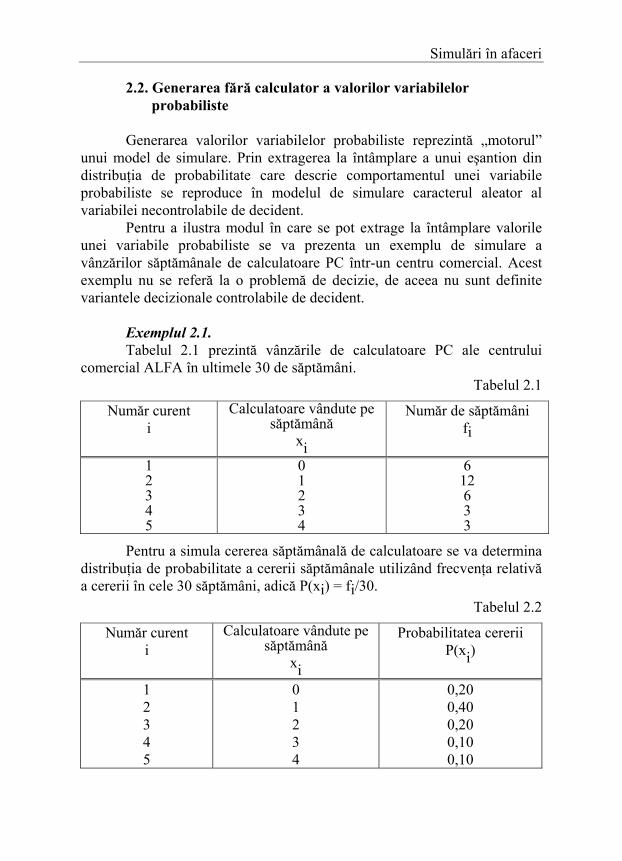
Tabelar. In Tabelul 2.5, fiecărei valori xi se asociază intervalul [F(xi-1), F(xi)) cu F(x0) = 0.
Simulări în afaceri
Tabelul 2.5
Valoarea xi a variabilei probabiliste
Probabilitatea P(X =xi) = P(xi)
Funcţia distribuţiei cumulative
F(xi)
Intervale [F(xi-1), F(xi))
x1 x2 ...
xm
P(x1) P(x2)
... P(xm)
F(x1) = P(x1) F(x2) = P(x1)+P(x2)
... F(xm) = P(xm-1)+P(xm)
[F(x0), F(x1)) [F(x0), F(x1))
... [F(xm-1), F(xm)]
Pasul 3. Se generează un număr aleator u uniform repartizat în intervalul [0, 1] utilizând un generator de numere aleatoare (de exemplu, cu funcţia =RAND() din Excel).
Pasul 4. Generarea unei valori xi a variabilei probabiliste discrete se poate realiza grafic sau tabelar.
Grafic. Numărul generat u se reprezintă printr-un punct pe axa verticală din Figura 2.2. Din acel punct se duce o paralelă la axa orizontală până când întâlneşte prima bară verticală şi se citeşte valoarea xi de la baza acelei bare. Se notează într-un tabel (vezi Tabelul 2.8) valoarea xi găsită pe grafic.
Figura 2.2
0
0.2
0.4
0.6
0.8
1
1.2
0 1 2 3 4 5
Probabilităţi
xi
u
F(xi)
0,2
0,6
0,8
0,9 1

Simulări în afaceri Tabelar. Se caută în Tabelul 2.5, intervalul [F(xi-1), F(xi)) căruia îi
aparţine numărul aleator u. Se scrie, într-un tabel (vezi Tabelul 2.8), în dreptul numărului aleator utilizat, valoarea xi identificată.
Pasul 5. Se reia procedura de la Pasul 3 până când se obţine volumul dorit al
selecţiei simulate.
Datele selecţiei simulate pot fi folosite ca date exogene pentru calculul unui alt indicator economic sau pot fi utilizate pentru calculul caracteristicilor distribuţiei de probabilitate a variabilei probabiliste cercetate: media, abaterea standard, coeficientul de variaţie şi intervalul de încredere pentru medie. Aplicaţii numerice
Exemplul 2.3. Se vor simula vânzările de calculatoare pentru 10 săptămâni utilizând distribuţia vânzărilor săptămânale de PC din Exemplul 2.1 prezentat din secţiunea 2.2.
Rezolvare
Pasul 1. În Tabelul 2.6 sunt prezentate valorile funcţiei distribuţiei cumulative F(xi) pentru vânzările săptămânale de calculatoare PC
determinate pe baza distribuţiei discrete din Tabelul 2.2.
Tabelul 2.6
Calculatoare vândute pe săptămână
xi
Probabilitatea cererii P(xi)
Funcţia distribuţiei cumulative
F(xi) = P(X ≤ xi)
0 1 2 3 4
0,20 0,40 0,20 0,10 0,10
0,20 0,60 0,80 0,90
1

Simulări în afaceri
Media determinată pe baza datelor reale referitoare la vânzările săptămânale de PC = µ = 0×0,2 + 1×0,4 + 2×0,2+ 3×0,1+ 4×0,1 = 1,5 calculatoare
Dispersia σ2 = 0×0,2 + 1×0,4 + 22×0,2+ 32×0,1+ 42×0,1 - 1,52 = 1,45, iar abaterea standard σ = 1,204 calculatoare. Pasul 2. Tabelul 2.7 conţine valorile numerice pentru cazul vânzărilor săptămânale de calculatoare PC
Tabelul 2.7
Valoarea variabilei
probabiliste xi
Probabilitatea P(X =xi) = P(xi)
Funcţia distribuţiei cumulative
F(xi)
Intervale [F(xi-1), F(xi))
x1 = 0
x2 = 1
x3 = 2
x4 = 3
x5 = 4
0,2
0,4
0,2
0,1
0,1
0,2
0,6
0,8
0,9
1,0
[0 0,2)
[0,2 0,6)
[0,6 0,8)
[0,8 0,9)
[0,9 1,0] Rezultatele efectuării Pasului 3, Pasului 4 şi Pasului 5 sunt prezentate în Tabelul 2.8.
Tabelul 2.8
Nr. aleator u
Valoarea xi a variabilei probabiliste
Număr calculatoare (bucăţi/săptămână)
0,486281 x2 1 0,928927 x5 4 0,205136 x2 1 0,852845 x4 3 0,005645 x1 0 0,651622 x3 2 0,799931 x3 2 0,333693 x2 1 0,416841 x2 1 0,011913 x1 0

Simulări în afaceri Media determinată pe baza selecţiei simulate = 1,5 calculatoare pe săptămână, iar abaterea standard = 1,269 calculatoare. Exemplul 2.4. Numărul de costume de haine bărbăteşti vândute zilnic în cadrul unui mare magazin de confecţii este o variabilă probabilistă discretă uniform repartizată în intervalul [6, 10]. Se cere simularea vânzărilor pentru 10 zile.
Rezolvare
În Tabelul 2.9 sunt prezentate probabilităţile P(X = xi) şi P(X ≤ xi) şi
intervalele de numere aleatoare asociate fiecărei valori in intervalul [6, 10].
Tabelul 2.9 Numărul de
costume de haine bărbăteşti vândute
zilnic xi
Probabilitatea P(X = xi)=1/5
Funcţia distribuţiei cumulative
F(xi) = P(X ≤ xi) = i/5
Intervale [F(xi-1), F(xi))
6 0,2 0,2 [0 0,2) 7 0,2 0,4 [0,2 0,4) 8 0,2 0,6 [0,4 0,6) 9 0,2 0,8 [0,6 0,8) 10 0,2 1,0 [0,8 1]
În Tabelul 2.10 sunt simulate vânzările din 10 zile.
Tabelul 2.10
Ziua Numărul aleator u Numărul de costume de haine bărbăteşti
1 0,709084 9 2 0,149934 6 3 0,294974 7 4 0,200192 7 5 0,189083 6 6 0,900415 10 7 0,940097 10 8 0,291185 7 9 0,002452 6 10 0,469177 8

Simulări în afaceri
Observaţie: În cazul variabilelor cu distribuţie uniformă discretă în intervalul [a, b], se poate genera direct o anumită valoare xi cu ajutorul relaţiei:
xi = partea întreagă din [a + (b-a+1)u]
De exemplu, dacă la Pasul 3 s-a generat u = 0,709084, atunci pentru variabila probabilistă cu distribuţie uniformă discretă în intervalul [6, 10], numărul de costume bărbăteşti vândute într-o zi oarecare este: xi = partea întreagă din [6 + (10-6+1)* 0,709084] = 9 costume Exemplul 2.5. O firmă de software doreşte să organizeze trimestrial concursuri pentru ocuparea unor posturi de programatori. Procesul de selectare a angajaţilor presupune participarea candidaţilor la un test de programare. Se estimează că se pot înscrie maxim 10 candidaţi.
Pe baza experienţei de la testele anterioare s-a stabilit că probabilitatea ca un candidat să treacă testul este de 0,30.
Managerul firmei doreşte să determine prin simulare câţi candidaţi vor promova testul la următoarele trei concursuri.
Rezolvare
Variabila probabilistă este numărul candidaţilor care vor reuşi la test. Distribuţia de probabilitate care caracterizează această variabilă probabilistă este binomială deoarece candidaţii sunt independenţi unul faţă de altul, iar după efectuarea testului există numai două categorii de candidaţi: promovaţi şi nepromovaţi.
În Tabelul 2.11 sunt prezentate valorile funcţiei de masă de probabilitate, valorile funcţiei distribuţiei cumulative şi intervalele de numere aleatoare.
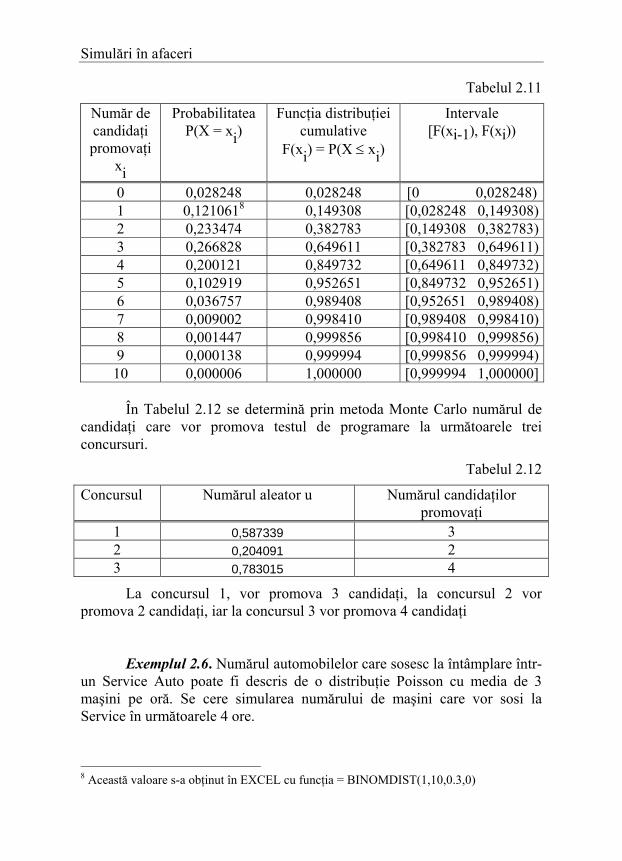
Simulări în afaceri
Tabelul 2.11
Număr de candidaţi promovaţi
xi
Probabilitatea P(X = xi)
Funcţia distribuţiei cumulative
F(xi) = P(X ≤ xi)
Intervale [F(xi-1), F(xi))
0 0,028248 0,028248 [0 0,028248) 1 0,1210618 0,149308 [0,028248 0,149308) 2 0,233474 0,382783 [0,149308 0,382783) 3 0,266828 0,649611 [0,382783 0,649611) 4 0,200121 0,849732 [0,649611 0,849732) 5 0,102919 0,952651 [0,849732 0,952651) 6 0,036757 0,989408 [0,952651 0,989408) 7 0,009002 0,998410 [0,989408 0,998410) 8 0,001447 0,999856 [0,998410 0,999856) 9 0,000138 0,999994 [0,999856 0,999994) 10 0,000006 1,000000 [0,999994 1,000000]
În Tabelul 2.12 se determină prin metoda Monte Carlo numărul de
candidaţi care vor promova testul de programare la următoarele trei concursuri.
Tabelul 2.12
Concursul Numărul aleator u Numărul candidaţilor promovaţi
1 0,587339 3 2 0,204091 2 3 0,783015 4
La concursul 1, vor promova 3 candidaţi, la concursul 2 vor promova 2 candidaţi, iar la concursul 3 vor promova 4 candidaţi Exemplul 2.6. Numărul automobilelor care sosesc la întâmplare într-un Service Auto poate fi descris de o distribuţie Poisson cu media de 3 maşini pe oră. Se cere simularea numărului de maşini care vor sosi la Service în următoarele 4 ore.
8 Această valoare s-a obţinut în EXCEL cu funcţia = BINOMDIST(1,10,0.3,0)

Simulări în afaceri
Rezolvare. În Tabelul 2.13 sunt prezentate valorile funcţiei de masă de probabilitate, valorile funcţiei distribuţiei Poisson cumulative şi intervalele de numere aleatoare.
Tabelul 2.13
Număr de maşini în
decurs de o oră xi
ProbabilitateaP(X = xi)
Funcţia distribuţiei cumulative
F(xi) = P(X ≤ xi)
Intervale [F(xi-1), F(xi))
0 0,049787 0,049787 [0, 0,049787) 1 0,1493619 0,199148 [0,049787 0,199148) 2 0,224042 0,42319 [0,199148 0,42319) 3 0,224042 0,647232 [0,42319 0,647232) 4 0,168031 0,815263 [0,647232 0,815263) 5 0,100819 0,916082 [0,815263 0,916082) 6 0,050409 0,966491 [0,916082 0,966491) 7 0,021604 0,988095 [0,966491 0,988095) 8 0,008102 0,996197 [0,988095 0,996197) 9 0,002701 0,998898 [0,996197 0,998898) 10 0,000810 0,999708 [0,998898 0,999708) 11 0,000221 0,999929 [0,999708 0,999929) 12 0,000055 0,999984 [0,999929 0,999984) 13 0,000013 0,999997 [0,999984 0,999997) 14 0,000003 0,999999 [0,999997 0,999999) 15 0,000001 1 [0,999999 1]
În Tabelul 2.14 sunt simulate sosirile din 4 ore.
Tabelul 2.14
Ora Numărul aleator u Număr maşini 1 0,105643 1 2 0,091935 1 3 0,917206 6 4 0,690022 4
9 Această valoare s-a obţinut în EXCEL cu funcţia = POISSON(1,3,0)

Simulări în afaceri Toate aplicaţiile numerice pentru simularea valorilor variabilelor probabiliste discrete se pot realiza în EXCEL prin utilizarea funcţiei VLOOKUP(număr aleator, zonă tabel cu probabilităţile cumulate, coloana din tabel unde se află valorile variabilei probabiliste).
2.5.2. Obţinerea de selecţii simulate în cazul variabilelor probabiliste continue
Distribuţii continue de probabilitate
Spre deosebire de distribuţia discretă de probabilitate, nu se poate defini o distribuţie continuă de probabilitate care să determine probabilitatea pentru o anumită valoare particulară a variabilei probabiliste. Deoarece o variabilă probabilistă continuă este o variabilă care poate avea orice valoare într-un interval specificat, ea are un număr infinit de valori posibile în acel interval şi deci probabilitatea ca o variabilă probabilistă continuă să aibă o anumită valoare particulară este zero. Pentru o variabilă probabilistă continuă se poate defini probabilitatea ca valoarea variabilei să fie cuprinsă într-un interval specificat. În acest scop, distribuţia este reprezentată printr-o curbă, iar probabilitatea se determină prin evaluarea ariei de sub curbă între limitele intervalului de pe axa x. Funcţia f(x) prin care se calculează această arie se numeşte funcţie de densitate de probabilitate şi trebuie să îndeplinească următoarele condiţii:
a) f(x) ≥ 0 pentru toate valorile x
b) dx)x(f∫∞
∞−= 1, adică aria de sub curbă până la axa valorilor x să
fie egală cu 1
c) P(a ≤ x ≤ b) = ∫b
adx)x(f
Funcţia distribuţiei cumulative este:
F(x) = P(X ≤ x) = ∫∞−
xdv)v(f
În unele cazuri funcţia de densitate de probabilitate este destul de dificil de calculat, dar există tabele cu valori sau programe de calcul pentru toate distribuţiile teoretice continue. Dintre acestea vor fi prezentate pe scurt

Simulări în afaceri
cele mai cunoscute: distribuţia uniformă continuă, distribuţia triunghiulară, distribuţia normală şi distribuţia exponenţială. Distribuţia uniformă continuă Distribuţia este uniformă dacă toate valorile variabilei probabiliste au aceeaşi probabilitate de apariţie. În simularea Monte Carlo, un rol deosebit îl are distribuţia uniformă continuă în intervalul [0, 1]. Funcţia f(x) de densitate de probabilitate este: f(x) = 0 pentru x < 0
= 1 pentru 0 ≤ x ≤ 1 = 0 pentru x > 1
Funcţia F(x) a distribuţiei cumulative este:
F(x) = ∫∞−
xdv)v(f
= 0 pentru x < 0 = x pentru 0 ≤ x ≤ 1 = 0 pentru x > 1
În cazul unei variabile probabiliste uniform repartizate în intervalul [a, b], funcţia f(x) de densitate de probabilitate este: f(x) = 0 pentru x < a
= 1/(b-a) pentru a ≤ x ≤ b = 0 pentru x > b,
iar funcţia distribuţiei cumulative F(x) = 0 pentru x < a = (x-a)/(b-a) pentru a ≤ x ≤ b = 1 pentru x > b
Media µ = (a+b)/2, iar dispersia σ2 = (b-a)2/12 Distribuţia triunghiulară descrie valorile unei variabile probabiliste prin trei valori: valoarea minimă (a), valoarea cea mai probabilă (b) şi valoarea maximă (c). Se presupune că, atât probabilitatea de realizare a valorii minime cât şi probabilitatea de realizare a valorii maxime sunt zero. Distribuţia triunghiulară se utilizează atunci când nu există date istorice referitoare la valorile variabilei analizate, aşa cum sunt, de exemplu, veniturile anuale estimate a se realiza după punerea în funcţiune a unui obiectiv de investiţii. Funcţia f(x) de densitate de probabilitate este: f(x) = 2(x-a)/((b-a)(c-a)) pentru a ≤ x ≤ b
= 2(c-x)/((c-a)(c-b)) pentru b < x ≤ c

Simulări în afaceri Funcţia F(x) a distribuţiei cumulative este:
F(x) = P(X ≤ x) = 0 pentru x<a
= ((x-a)2)/((b-a)(c-a)) pentru a ≤ x ≤ b
= 1 – ((c-x)2)/((c-a)(c-b)) pentru b < x ≤ c = 1 pentru x>c
Media µ = (a+b+c)/3
Dispersia σ2 = (a2 + b2 + c2 – ab – ac – bc)/18 Distribuţia normală
Distribuţia normală sau distribuţia Gaussiană are un rol fundamental în teoria probabilităţilor şi în statistică. Acest tip de distribuţie descrie caracteristici ale populaţiei (înălţimea, greutatea) sau distribuţiile unor mărimi care sunt sume de alte mărimi (conform teoremei limitei centrale). Astfel, durata totală de realizare a unui proiect, ca sumă a duratelor probabiliste ale activităţilor de pe drumul critic, este o variabilă cu distribuţie normală. Distribuţia normală este o distribuţie simetrică sub formă de clopot. Funcţia f(x) de densitate de probabilitate este o funcţie cu doi parametri,
media µ şi dispersia σ2, de forma:
f(x) = ⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
σ
µ−−
πσ22
2)x(exp22
1
Deoarece, funcţia f(x) de densitate de probabilitate a distribuţiei normale nu poate fi integrată exact, ea nu se foloseşte direct. Calculul ariilor necesare pentru determinarea probabilităţilor P(a ≤ x ≤ b) şi a funcţiei distribuţiei cumulative se bazează pe tabelele distribuţiei normale standard de probabilitate care este distribuţia normală a unei variabile probabiliste cu
media µ = 0, dispersia σ2 = 1 şi abaterea standard σ = 1. Pentru a transforma o variabilă probabilistă X cu distribuţia normală într-o variabilă probabilistă Z cu distribuţia normală standard se poate utiliza formula: Z = (x - µ)/σ
În tabelele distribuţiei normale standard (Anexa 1) se găsesc probabilităţile P(0 ≤ Z ≤ z), care reprezintă (Figura 2.3) valoarea ariei de sub curba funcţiei de densitate de probabilitate f(z), cuprinsă între media µ = 0 şi valoarea z specificată.
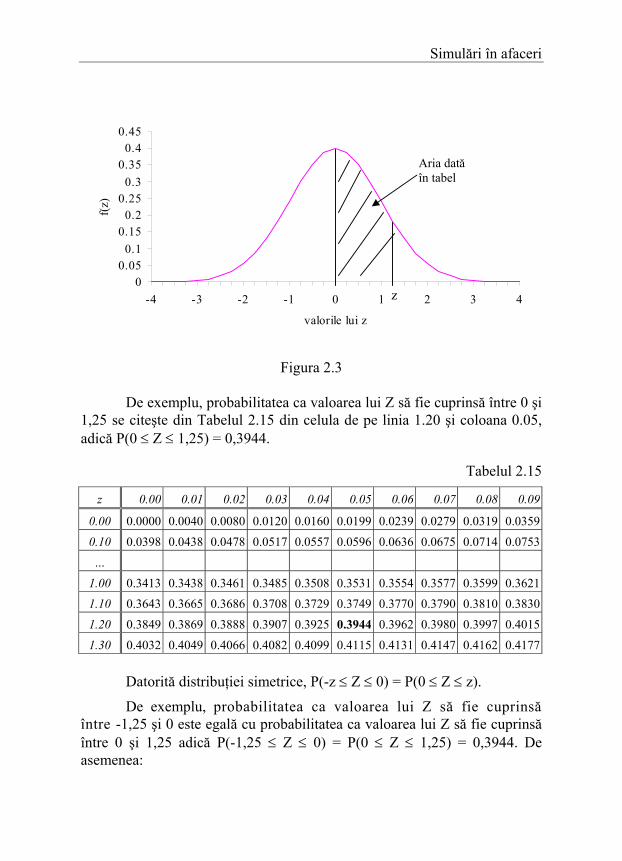
Simulări în afaceri
Figura 2.3
De exemplu, probabilitatea ca valoarea lui Z să fie cuprinsă între 0 şi 1,25 se citeşte din Tabelul 2.15 din celula de pe linia 1.20 şi coloana 0.05, adică P(0 ≤ Z ≤ 1,25) = 0,3944.
Tabelul 2.15
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.00 0.0000 0.0040 0.0080 0.0120 0.0160 0.0199 0.0239 0.0279 0.0319 0.0359
0.10 0.0398 0.0438 0.0478 0.0517 0.0557 0.0596 0.0636 0.0675 0.0714 0.0753
…
1.00 0.3413 0.3438 0.3461 0.3485 0.3508 0.3531 0.3554 0.3577 0.3599 0.3621
1.10 0.3643 0.3665 0.3686 0.3708 0.3729 0.3749 0.3770 0.3790 0.3810 0.3830
1.20 0.3849 0.3869 0.3888 0.3907 0.3925 0.3944 0.3962 0.3980 0.3997 0.4015
1.30 0.4032 0.4049 0.4066 0.4082 0.4099 0.4115 0.4131 0.4147 0.4162 0.4177 Datorită distribuţiei simetrice, P(-z ≤ Z ≤ 0) = P(0 ≤ Z ≤ z).
De exemplu, probabilitatea ca valoarea lui Z să fie cuprinsă între -1,25 şi 0 este egală cu probabilitatea ca valoarea lui Z să fie cuprinsă între 0 şi 1,25 adică P(-1,25 ≤ Z ≤ 0) = P(0 ≤ Z ≤ 1,25) = 0,3944. De asemenea:
00.05
0.10.15
0.20.25
0.30.35
0.40.45
-4 -3 -2 -1 0 1 2 3 4
valorile lui z
f(z)
z
Aria dată în tabel

Simulări în afaceri Valoarea funcţiei distribuţiei normale standard cumulative este:
F(z) = P(Z ≤ z) = 0,5 + P(0 ≤ Z ≤ z) şi F(z) = P(Z ≤ -z) = 0,5 - P(0 ≤ Z ≤ z) Pentru variabilele probabiliste cu distribuţiei normală având media µ şi abaterea standard σ, valoarea funcţiei distribuţiei cumulative se poate determina astfel: F(x) = P(X ≤ x) = P(Z ≤ (x - µ)/σ)
Probabilitatea ca valoarea x a unei variabile probabiliste să fie cuprinsă în intervalul [a, b] este:
P(a ≤ X ≤ b) = P(X ≤ b) - P(X ≤ a) = P(Z ≤ (b - µ)/σ) - P(Z ≤ (a - µ)/σ)
Distribuţia exponenţială
Distribuţia exponenţială este utilizată pentru a descrie timpul dintre diferite evenimente cum sunt, de exemplu, intervalele de timp dintre sosirile clienţilor într-un sistem de aşteptare. Se poate arăta că dacă numărul sosirilor poate fi descris de o distribuţie Poisson, atunci intervalul dintre sosiri urmează o distribuţie exponenţială.
Dacă X este o variabilă probabilistă cu media µ şi abaterea standard µ atunci funcţia f(x) de densitate de probabilitate este:
f(x) = µ1 e-x/µ
iar funcţia F(x) de distribuţie cumulativă este:
F(x) = P(X ≤ x) = 1 - e-x/µ
Rezultă că P(X > x) = e-x/µ
Valoarea ariei de sub curba funcţiei de densitate de probabilitate f(z), aflată la stânga lui 0
Valoarea ariei de sub curba funcţiei de densitate de probabilitate f(z), aflată la dreapta lui 0
= =0,5
Simulări în afaceri
Procedura pentru aplicarea metodei Monte Carlo în cazul variabilelor probabiliste continue
S-a arătat că, pentru o variabilă probabilistă continuă se poate defini numai probabilitatea ca valoarea variabilei să fie cuprinsă într-un interval specificat. Această probabilitate se calculează cu o funcţie f(x) de densitate de probabilitate a cărui valoare reprezintă aria de sub curba f(x) corespunzătoare intervalului specificat. Probabilitatea P(X ≤ x) ca valoarea variabilei probabiliste X să fie mai mică decât o anumită valoare particulară x se calculează cu funcţia de distribuţie cumulativă F(x) = P(X≤x) =
∫∞−
xdv)v(f .
Aplicarea metodei Monte Carlo pentru obţinerea de selecţii simulate în cazul variabilelor probabiliste continue se poate face pe baza următoarei proceduri:
Pasul 1. Se construiesc funcţiile f(x) de densitate de probabilitate şi F(x) de distribuţie cumulativă.
În cazul distribuţiilor empirice, după organizarea şi gruparea pe intervale, valorile variabilei probabiliste continue se pot prezenta conform Tabelului 2.16. Graficul funcţiei F(x) al distribuţiei empirice cumulative va fi o curbă liniară pe porţiuni, obţinută prin unirea punctelor ale căror coordonate sunt limitele superioare ale intervalelor [xi-1, xi] şi respectiv [F(xi-1), F(xi)].
Tabelul 2.16 Intervale de valori ale variabilei probabiliste [xi-1, xi)
Frecvenţa fi
Frecvenţa relativă
fi/ ∑=
m
1kkf
Frecvenţa cumulativă
F(xi)
Intervale [F(xi-1), F(xi))
[x0, x1) f1 f1/ ∑=
m
1kkf F(x1)=f1/ ∑
=
m
1kkf [F(x0), F(x1))
[x1, x2) f2 f2/ ∑=
m
1kkf F(x2)=(f1+f2)/ ∑
=
m
1kkf [F(x1), F(x2))
... ... ... ... ...
[xm-1, xm] fm fm/ ∑=
m
1kkf F(xm) = 1 [F(xm-1), F(xm)]
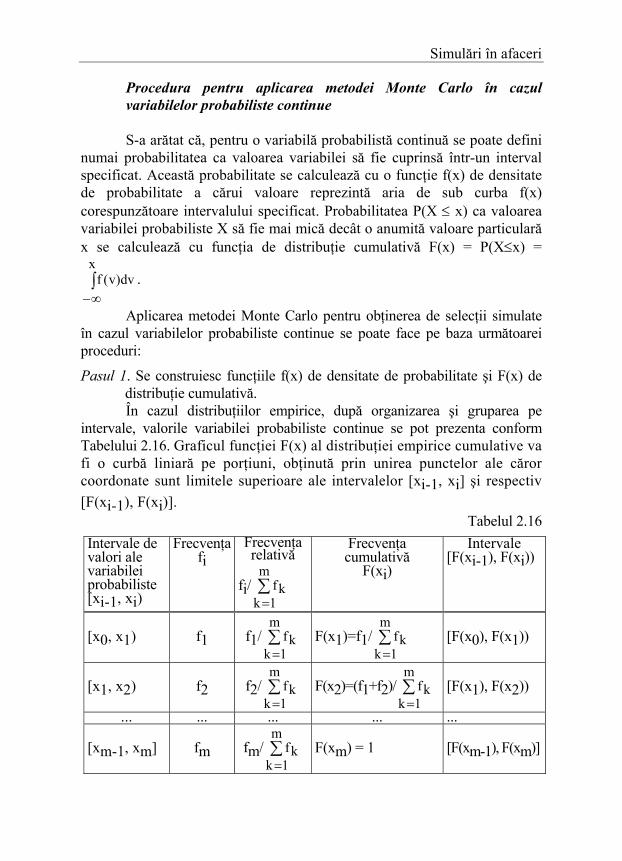
Simulări în afaceri Exemplul 2.7. Datele rezultate în urma observării timpului de servire a 100 clienţi care au solicitat efectuarea unor operaţiuni la un ghişeu de bancă sunt prezentate în Tabelul 2.17.
Tabelul 2.17 Timpul
individual de servire (minute) [xi-1, xi)
Numărul clienţilor
fi
Frecvenţa relativă
fi/ ∑=
m
1kkf
Frecvenţa cumulativă
F(xi)
Intervale [F(xi-1), F(xi))
[5, 10) 15 0,15 0,15 [0,00 0,15) [10, 15) 26 0,26 0,41 [0,15 0,41) [15, 20) 23 0,23 0,64 [0,41 0,64) [20, 25) 18 0,18 0,82 [0,64 0,82) [25, 30) 10 0,10 0,92 [0,82 0,92) [30, 35) 8 0,08 1,00 [0,92 1,00]
Pasul 2. Se generează un număr aleator u uniform repartizat în intervalul [0, 1] utilizând un generator de numere aleatoare (de exemplu, cu funcţia =RAND() din Excel).
Pasul 3. Se generează o valoare x a variabilei probabiliste continue prin rezolvarea ecuaţiei F(x) = u.
Figura 2.4
00.10.20.30.40.50.60.70.80.9
1
5 10 15 20 25 30 35
Timpul de servire
Prob
abili
tat
u=0,38
x=14,423
F(x)

Simulări în afaceri
În Figura 2.4 este reprezentată funcţia F(x) a distribuţiei cumulative pentru timpul de servire a clienţilor la un ghişeu bancar, obţinută prin unirea punctelor ale căror coordonate sunt limitele superioare ale intervalelor [xi-1, xi] şi respectiv [F(xi-1), F(xi)].
Dacă la Pasul 2 s-a generat numărul aleator u = 0,38, ca şi în cazul variabilelor probabiliste discrete, se reprezintă numărul u pe axa verticală şi se proiectează pe orizontală până când întâlneşte curba F(x) şi, apoi, se citeşte valoarea x de pe axa orizontală, dacă pentru reprezentarea grafică s-a folosit hârtie milimetrică. Această procedură grafică poate fi înlocuită cu o procedură algebrică echivalentă de rezolvare a ecuaţiei F(x) = u. Dacă soluţia poate fi obţinută cu relaţia x= F-1(u), atunci metoda de extragere a unei valori a variabilei probabiliste se numeşte metoda inversei. Dacă nu se poate construi inversa explicită a funcţiei F(x), ecuaţia F(x)=u se poate rezolva cu metoda interpolării. Astfel, deoarece u = 0,38 aparţine intervalului de numere aleatoare [0,15 0,14) corespunzător intervalului [10 15) al timpului de servire, rezultă că
x = 10 + (0,38 – 0,15)(15 - 10)/(0,41 – 0,15) = 14,423 minute În general, dacă numărul aleator u aparţine intervalului de numere aleatoare [F(xi-1), F(xi)) asociat valorilor [xi-1, xi), atunci se va genera valoarea x cu relaţia de interpolare:
x = xi-1 + (u - F(xi-1))(xi - xi-1)/(F(xi) - F(xi-1))
• Pentru distribuţia uniformă continuă în intervalul [a, b], ecuaţia F(x)=u este de forma
(x-a)/(b-a) = u de unde
x = a + u(b-a). Exemplul 2.8. Timpul necesar pentru servirea unui client este o variabilă aleatoare uniform distribuită cu valori între 5 minute şi 15 minute.
Dacă la Pasul 2 s-a generat numărul aleator u=0,72, atunci timpul de servire extras din distribuţia de probabilitate uniformă continuă este
x = 5 + 0,72 × (15 – 5) = 12,2 minute
• În cazul distribuţiei triunghiulare descrisă prin trei valori (a<b<c), dacă u ≤ (b-a)/(c-a), atunci din ecuaţia F(x)=u de forma:
Simulări în afaceri
((x-a)2)/((b-a)(c-a)) = u rezultă
x = a + (u(b-a)(c-a))½ şi dacă u > (b-a)/(c-a), atunci din ecuaţia
1 – ((c-x)2)/((c-a)(c-b)) = u rezultă
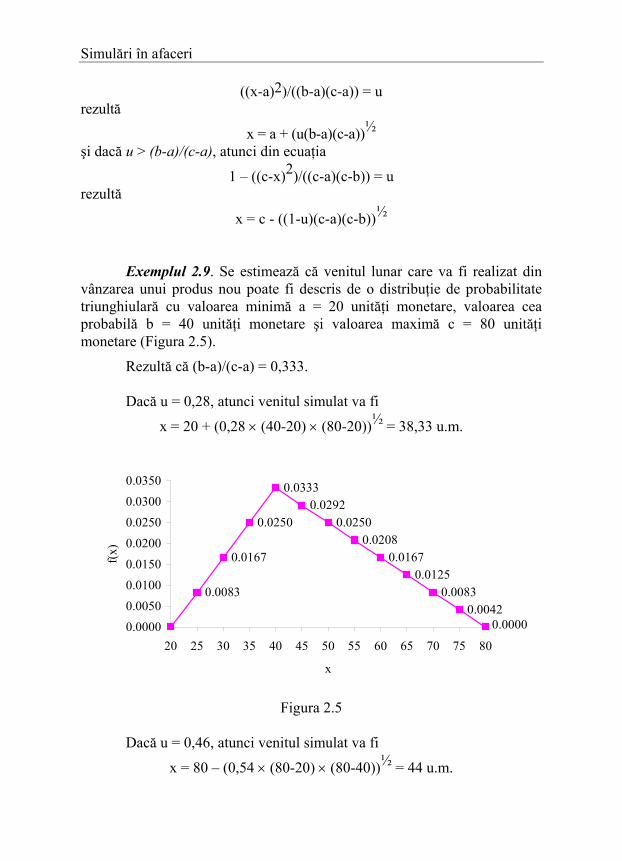
x = c - ((1-u)(c-a)(c-b))½ Exemplul 2.9. Se estimează că venitul lunar care va fi realizat din vânzarea unui produs nou poate fi descris de o distribuţie de probabilitate triunghiulară cu valoarea minimă a = 20 unităţi monetare, valoarea cea probabilă b = 40 unităţi monetare şi valoarea maximă c = 80 unităţi monetare (Figura 2.5).
Rezultă că (b-a)/(c-a) = 0,333.
Dacă u = 0,28, atunci venitul simulat va fi
x = 20 + (0,28 × (40-20) × (80-20))½ = 38,33 u.m.
Figura 2.5 Dacă u = 0,46, atunci venitul simulat va fi
x = 80 – (0,54 × (80-20) × (80-40))½ = 44 u.m.
0.0083
0.0167
0.0250
0.03330.0292
0.02500.0208
0.01670.0125
0.00830.0042
0.00000.00000.00500.01000.0150
0.02000.02500.03000.0350
20 25 30 35 40 45 50 55 60 65 70 75 80
x
f(x)

Simulări în afaceri
• Deoarece distribuţia normală este descrisă de o funcţie de
densitate de probabilitate care nu poate fi integrată exact, nici inversa F-1 a funcţiei distribuţiei cumulative nu poate fi obţinută. Pentru generarea valorilor unei variabile cu distribuţie normală se pot folosi metode aproximative cum sunt: metoda Box-Muller, metoda teoremei limitei centrale, metoda respingerii [3, 46]. Programul EXCEL, prin funcţia „=NORMINV(RAND(), media µ, abaterea standard σ)” determină o valoare x a unei variabile normal distribuite cu media µ şi abaterea standard σ, prin aproximări succesive ale lui x, astfel încât diferenţa (u-F(x)), dintre numărul aleator u generat de RAND() şi valoarea funcţiei F(x) de distribuţie cumulativă, să fie mai mică decât ±3×10-7.
Exemplul 2.10. Se cunoaşte că, greutatea unui cozonac realizat de firma „Extra” este o variabilă probabilistă normal distribuită cu media de 500 grame şi abaterea standard de 50 grame.
Dacă u = 0,548, pentru a extrage o valoare pentru greutatea unui cozonac cu distribuţia normală, media µ=500 grame şi abaterea standard σ = 50 grame, se va introduce într-o celulă EXCEL funcţia
=NORMINV(0.548,500,50) Greutatea obţinută va fi 506,0305 grame.
• În cazul distribuţiei exponenţiale cu media µ, soluţia ecuaţiei F(x)=u este de forma
x = - µln(1-u) unde ln este logaritmul natural.
Exemplul 2.11. Durata dintre sosirile clienţilor într-un magazin alimentar este o variabilă aleatoare cu distribuţie exponenţială cu media de 5 minute. Dacă numărul aleator u = 0,852, atunci se obţine durata intervalului între sosiri x = -5×ln(1-0,852) = 9,553 minute.
Înainte de a trece la Pasul 4 al procedurii de generare a selecţiilor artificiale, trebuie menţionat faptul că pentru majoritatea distribuţiilor de probabilitate teoretice au fost elaborate metode de rezolvare a ecuaţiei F(x)=u. Pasul 4. Se reia procedura de la Pasul 2 până când se obţine volumul dorit al selecţiei simulate.

Simulări în afaceri 2.6. Concluzii
În simulare, pentru a imita sau reproduce ceea ce se întâmplă într-un sistem stochastic este necesar să se genereze în mod întâmplător valorile variabilelor probabiliste care intervin în problema decizională.
Procesul de generare aleatoare a valorilor unei variabile probabiliste este referit în literatura de specialitate ca metoda Monte Carlo şi constă în utilizarea unui generator de numere aleatoare uniform distribuite în intervalul [0, 1] şi a funcţiei distribuţiei cumulative asociată variabilei probabiliste respective.
Toate limbajele de programare generale şi limbajele speciale de simulare conţin generatori de numere aleatoare bine verificaţi şi testaţi.
Numărul aleator furnizat de un generator este apoi utilizat pentru extragerea unei valori din distribuţia de probabilitate care descrie comportamentul variabilei probabiliste.
Obţinerea sau generarea valorilor unei variabile descrisă de o distribuţie de probabilitate se poate face grafic, tabelar, prin metoda inversei funcţiei de distribuţie cumulativă sau prin alte metode implementate în diferite programe comerciale.