lucrarea practică 8 - seria 7 · numai cu epi info, dar şi cu dbase, foxpro, excel etc. aceste...
TRANSCRIPT

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 92 -
Lucrarea practică 8
Indicaţii generale:
Un prim scop al lucrării practice este crearea de fişiere de tip chestionar (sau view-
uri) pentru introducerea datelor în fişierele create în EpiInfo 2005. Acesta este un soft
specific unor prelucrări statistice de date, utilizat în special în epidemiologie.
Avantajul principal al acestui soft constă în faptul că nu impune cheltuieli majore,
în condiţiile în care, cu ajutorul său, se pot obţine majoritatea rezultatelor prelucrărilor de
date cu care ne întâlnim în cercetarea medicală.
Punctul său forte, pentru care este recomandată folosirea sa, este posibilitatea
creării unor chestionare care să nu permită, din start, introducerea de date eronate flagrant.
Punctul său slab îl constituie slaba calitate a diagramelor pe care le poate crea.
Afirmaţii de tipul „fumatul este asociat cu decesul timpuriu, după un prim atac de
cord”, făcute în urma comparării unor proporţii calculate cu date obţinute din eşantioane
„reprezentative”, pot fi confirmate statistic prin teste hi pătrat (care în asemenea situaţii
sunt considerate ca teste de semnificaţie statistică, şi nu ca teste de bonitate).
Aplicaţiile statistice (SPSS, Epi Info, …) au evident implementate module pentru
efectuarea directă a calculelor necesare. Dar rezultatele pot fi obţinute şi cu ajutorul
aplicaţiei Excel, controlând în mod corespunzător desfăşurarea calculelor.
În această lucrare practică:
a) veţi crea fişiere de tip baze de date, chestionare în interiorul lor, apoi veţi
introduce înregistrări;
b) veţi începe prelucrarea statistică a înregistrărilor, pe exemple simple.
c) veţi exersa modul de obţinere a tabelelor de contingenţă din datele primare,
atât în Excel, cât şi în FoxPro;
d) veţi aplica teste Z şi hi pătrat pe tabele de contingenţă simple;
e) veţi începe să folosiţi modulul Analyze Data al aplicaţiei Epi Info;
f) veţi învăţa să lucraţi cu comanda TABLES din acest modul, comandă dedicată
obţinerii tabelelor de contingenţă şi a rezultatelor conexe.
Teme 34: crearea chestionarelor în Epi Info
35: introducerea datelor în Epi Info
36: analiza statistică primară a datelor din fişiere
37: tabele de contingenţă în Excel
38: testul hi pătrat în Excel
39: comanda TABLES în Epi Info
Softul ce va fi utilizat în lucrarea practică:
EpiInfo 2005, Excel, FoxPro

UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 93 -
Tema 34: crearea chestionarelor în Epi Info
Epi Info este un pachet de programe destinat prelucrării de date organizate sub formă de
chestionare şi sistematizării rezultatelor studiilor pentru a fi incluse în comunicări şi
rapoarte. Conceput în primul rând pentru aplicaţii în epidemiologie, Epi Info poate fi folosit
cu succes în prelucrarea datelor din domeniul medical şi din afara acestuia, pachetul
incluzând facilităţi de gestiune a datelor şi de statistică de tipul celor oferite de programele
SAS, SPSS, etc. facilităţi cuprinse întrun singur sistem al cărui avantaj principal este faptul
că este permisă copierea şi libera distribuire. La lansare, pagina de întâmpinare este
următoarea:
Principalele componente ale programului Epi Info sunt următoarele:
Make View, care este un editor de text folosit pentru a defini câmpurile utilizate în
introducerea datelor pe una sau mai multe pagini ale unui chestionar (View).
Enter Data, care afişează chestionarele construite cu Make View, controlează procesul
de introducere a datelor utilizând setările şi codurile specificate în Make View; are şi
posibilităţi de căutare a înregistrărilor.
Analyze Data, care este folosit pentru analizarea datelor înregistrate în fişierele create nu
numai cu Epi Info, dar şi cu dBase, FoxPro, Excel etc. Aceste fişiere pot conţine liste,
frecvenţe, tabele, diagrame, date specifice studiilor epidemiologice.
Create Maps, care este un instrument folosit pentru crearea hărţilor epidemiologice.
Create Reports, care este folosit pentru generarea rapoartelor.
Alte componente sau utilitare ale softului, utile în diverse activităţi, sunt următoarele:
NutStat, care este folosit pentru înregistrarea şi evaluarea măsurătorilor referitoare la
înălţime, greutate, circumferinţa capului şi a toracelui pentru copii şi adolescenţi.

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 94 -
StatCalc, care este folosit pentru efectuarea de calcule statistice cu date plasate în tabele.
Data Compare, care este folosit pentru identificarea diferenţelor între două tabele.
Table to View, care se foloseşte pentru a genera un chestionar (view) pe baza unui tabel
de date existent.
VisData, utilizat pentru citirea fişierelor de date şi schimbarea proprietăţilor.
Epi Lock, care furnizează o criptare pentru a se proteja accesul la date şi pentru a facilita
atât transmisia dar şi crearea còpiilor de rezervă (backup).
Compact, care este folosit la compactarea bazelor de date de tip (MS)Access.
Aplicaţia Epi Info cuprinde şi
– un sistem de ajutorare a utilizatorului (help), care conţine informaţii despre
facilităţile oferite,
– un manual de utilizare, precum şi
– un program de îndrumare interactivă în crearea fişierelor folosite în epidemiologie.
Pentru crearea unui fişier-chestionar se va folosi modulul Make View, anume comanda:
FileNewFile name (numele bazei de date: nume_EPI)OpenName the View
(„Chest1” ca nume dat chestionarului)
În pagina din partea stângă găsiţi trei opţiuni referitoare la gestiunea paginilor din
chestionar (Add Page – adăugarea unei noi pagini la sfârşitul celor deja existente, Insert
Page – adăugarea unei pagini noi între două deja existente, Delete Page – eliminarea paginii
curente) precum şi comanda Program care face posibilă programarea anumitor operaţii de
verificare, ducând astfel la evitarea erorilor care pot apărea la introducerea datelor.
Introducerea de câmpuri în pagina curentă a chestionarului, conform indicaţiei afişate, se
efectuează cu un clic pe butonul din dreapta la mausului, în poziţia în care se doreşte apariţia
câmpului respectiv (pentru fixarea poziţiei este utilă grila). Ca urmare, va apărea caseta de
dialog Field Definition în care se vor introduce caracteristicile câmpului: numele, tipul,
dimensiunea, limitările valorilor, codificări, valorile legale etc.
UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 95 -
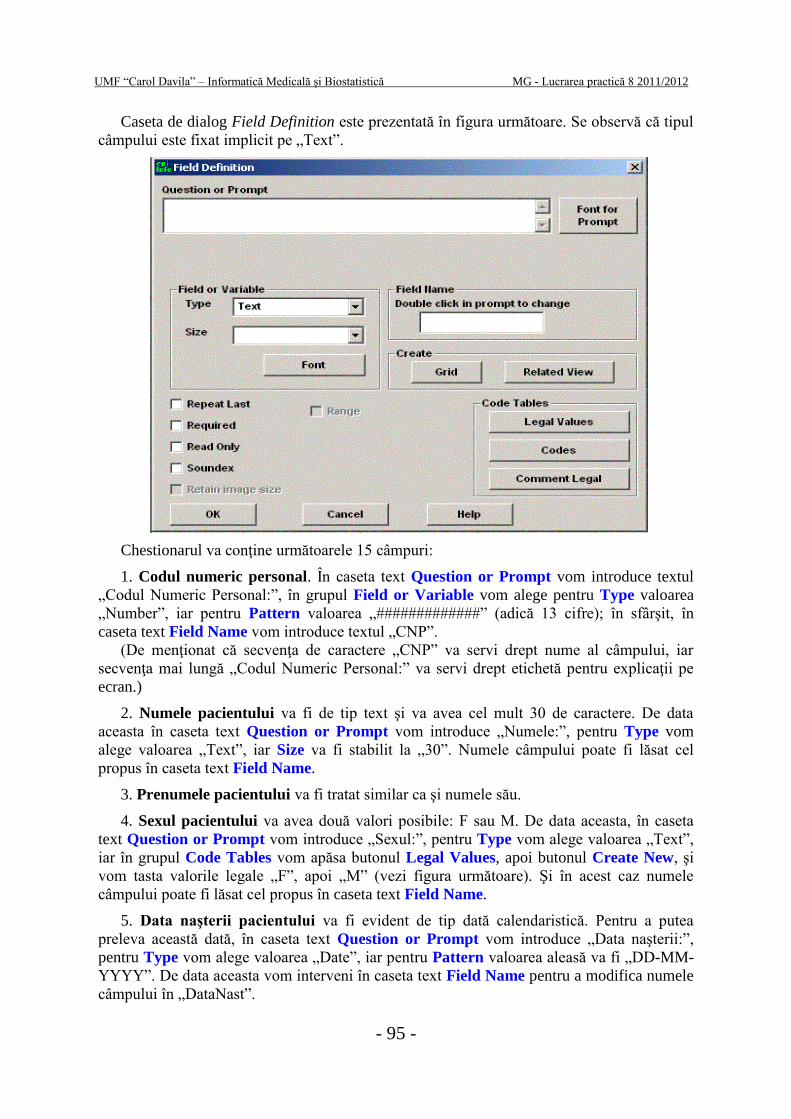
Caseta de dialog Field Definition este prezentată în figura următoare. Se observă că tipul
câmpului este fixat implicit pe „Text”.
Chestionarul va conţine următoarele 15 câmpuri:
1. Codul numeric personal. În caseta text Question or Prompt vom introduce textul
„Codul Numeric Personal:”, în grupul Field or Variable vom alege pentru Type valoarea
„Number”, iar pentru Pattern valoarea „#############” (adică 13 cifre); în sfârşit, în
caseta text Field Name vom introduce textul „CNP”.
(De menţionat că secvenţa de caractere „CNP” va servi drept nume al câmpului, iar
secvenţa mai lungă „Codul Numeric Personal:” va servi drept etichetă pentru explicaţii pe
ecran.)
2. Numele pacientului va fi de tip text şi va avea cel mult 30 de caractere. De data
aceasta în caseta text Question or Prompt vom introduce „Numele:”, pentru Type vom
alege valoarea „Text”, iar Size va fi stabilit la „30”. Numele câmpului poate fi lăsat cel
propus în caseta text Field Name.
3. Prenumele pacientului va fi tratat similar ca şi numele său.
4. Sexul pacientului va avea două valori posibile: F sau M. De data aceasta, în caseta
text Question or Prompt vom introduce „Sexul:”, pentru Type vom alege valoarea „Text”,
iar în grupul Code Tables vom apăsa butonul Legal Values, apoi butonul Create New, şi
vom tasta valorile legale „F”, apoi „M” (vezi figura următoare). Şi în acest caz numele
câmpului poate fi lăsat cel propus în caseta text Field Name.
5. Data naşterii pacientului va fi evident de tip dată calendaristică. Pentru a putea
preleva această dată, în caseta text Question or Prompt vom introduce „Data naşterii:”,
pentru Type vom alege valoarea „Date”, iar pentru Pattern valoarea aleasă va fi „DD-MM-
YYYY”. De data aceasta vom interveni în caseta text Field Name pentru a modifica numele
câmpului în „DataNast”.

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 96 -
6. Data internării pacientului va fi tratată similar ca şi data naşterii.
7. Edeme va fi o variabilă cu două valori posibile Yes/No. De data aceasta, în caseta text
Question or Prompt vom introduce „Edeme?”, pentru Type vom alege valoarea „Yes/No”.
În acest caz numele câmpului, în caseta text Field Name, va fi modificat în „Edeme”.
În mod asemănător se procedează pentru următoarele 3 câmpuri:
8. Pleurezie.
9. Palpitaţii (numele câmpului „Palpitatii”).
10. Tuse.
11. Temperatura va fi o variabilă de tip numeric şi va lua valori numai între 35 şi 43.
Pentru stabilirea valorilor limită se bifează caseta de validare Range şi se aleg pentru Lower
şi Upper valorile „35”, respectiv „43”.
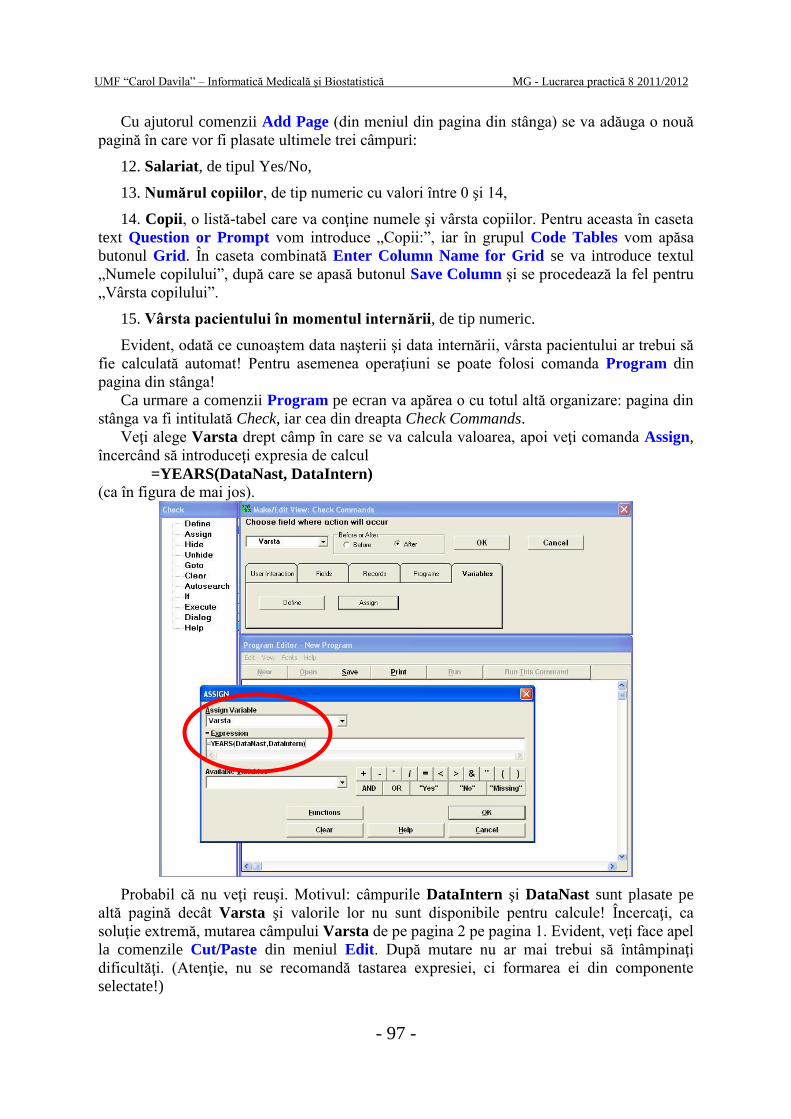
Ultimele 5 câmpuri (Edeme, Pleurezie, Palpitatii, Tuse şi Temperatura) vor fi grupate
întrun grup numit Manifestari. Pentru crearea unui grup se procedează în felul următor: se
selectează câmpurile prin tragere cu mausul deasupra, apoi din meniul Insert se alege
comanda Group.
Pagina construită poate să aibă următoarea formă:
UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 97 -
Cu ajutorul comenzii Add Page (din meniul din pagina din stânga) se va adăuga o nouă
pagină în care vor fi plasate ultimele trei câmpuri:
12. Salariat, de tipul Yes/No,
13. Numărul copiilor, de tip numeric cu valori între 0 şi 14,
14. Copii, o listă-tabel care va conţine numele şi vârsta copiilor. Pentru aceasta în caseta
text Question or Prompt vom introduce „Copii:”, iar în grupul Code Tables vom apăsa
butonul Grid. În caseta combinată Enter Column Name for Grid se va introduce textul
„Numele copilului”, după care se apasă butonul Save Column şi se procedează la fel pentru
„Vârsta copilului”.
15. Vârsta pacientului în momentul internării, de tip numeric.
Evident, odată ce cunoaştem data naşterii şi data internării, vârsta pacientului ar trebui să
fie calculată automat! Pentru asemenea operaţiuni se poate folosi comanda Program din
pagina din stânga!
Ca urmare a comenzii Program pe ecran va apărea o cu totul altă organizare: pagina din
stânga va fi intitulată Check, iar cea din dreapta Check Commands.
Veţi alege Varsta drept câmp în care se va calcula valoarea, apoi veţi comanda Assign,
încercând să introduceţi expresia de calcul
=YEARS(DataNast, DataIntern)
(ca în figura de mai jos).
Probabil că nu veţi reuşi. Motivul: câmpurile DataIntern şi DataNast sunt plasate pe
altă pagină decât Varsta şi valorile lor nu sunt disponibile pentru calcule! Încercaţi, ca
soluţie extremă, mutarea câmpului Varsta de pe pagina 2 pe pagina 1. Evident, veţi face apel
la comenzile Cut/Paste din meniul Edit. După mutare nu ar mai trebui să întâmpinaţi
dificultăţi. (Atenţie, nu se recomandă tastarea expresiei, ci formarea ei din componente
selectate!)

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 98 -
Tema 35: introducerea datelor în Epi Info
Se poate realiza direct din meniul File, comandând Enter Data. Alte posibilităţi, după
părăsirea modulului Make View, din pagina principală Epi Info fie se alege direct modulul
Enter Data, fie se comandă Enter Data din meniul Programs. În acest caz se deschide
chestionarul creat, alegându-se proiectul şi view-ul corespunzător.
Se vor introduce cel puţin 4 înregistrări (adică se completează câmpurile cu date pentru
cel puţin 4 persoane, pe ambele pagini!). După care salvaţi fişierul nume_EPI.mdb şi
transferaţi-l în căminul d-voastră.
În figura de mai jos este prezentat momentul completării datei internării, pe pagina 1
pentru înregistrarea a 3-a. De menţionat că pentru toate inscripţiile legate de valorile
câmpurilor a fost ales un font standard de afişare (MS Sans Serif) de mărime 14 p.t.
Se impune o observaţie. În datele pe care le introducem apar redundante sexul şi data
naşterii. Este posibil ca valoarea din câmpul DataNast să fie „calculată” automat odată ce a
fost introdus codul numeric personal, la fel valoarea din câmpul Sexul. Puteţi realiza
aceasta?
Tema 36: analiza statistică primară a datelor din fişiere
Pentru a efectua calcule statistice vom folosi modului Analyze Data. În cadrul acestui
modul vom folosi mai multe comenzi pe care le putem alege din fereastra de comenzi din
partea stângă. Rezultatele execuţiei comenzilor sunt afişate în fereastra din dreapta sus
(intitulată Analysis Output). În fereastra din dreapta jos (intitulată Program Editor) se vor
afişa comenzile/seturile de comenzi care au fost executate anterior; de asemenea, se pot
introduce noi comenzi, în regim de linie de comandă.
Comenzile pe care le putem alege sunt grupate, în fereastra din stânga, în câteva grupe.
Distingem astfel comenzile de lucru cu datele (grupate în „Data”), cele ce operează asupra
variabilelor (grupate evident în „Variables”), comenzile de selecţie (grupate în „Select/If”),
comenzile de analiză statistică primară (grupate în „Statistics”) etc.
Read (Import) este comanda utilizată la începutul oricărei sesiuni de lucru în modulul
Analysis. Este folosită pentru preluarea datelor dintr-un fişier, date ce vor fi folosite pentru
prelucrările ulterioare (până la o nouă comandă Read (Import).). Formatul implicit al

UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 99 -
datelor este Epi 2000, dar acesta poate fi schimbat astfel încât este posibil să se preia date şi
din alte tipuri de fişiere (de exemplu diverse versiuni de Excel, diverse versiuni de Fox Pro,
Paradox sau chiar documente hipertext).
Softul Epi Info este însoţit de mai multe „proiecte” pentru exemplificare şi auto-învăţare,
dintre care cel mai simplu este Sample.mdb.
Lansaţi în execuţie comanda:
Read (Import)Data Formats: „Epi 2000”
Data Source: „Sample.mdb”
Show: Views
Views: „viewBabyBloodPressure”
Veţi constata că aceasta este de fapt comanda:
READ 'C:\...\Epi_Info\Sample.mdb':viewBabyBloodPressure
List, din grupul „Statistics”, este comanda de afişare sub formă tabelară (Grid sau HTML)
a valorilor unor variabile din fişierul activ de date. Implicit, pentru valoarea „*” în lista
Variables, vor fi afişate valorile pentru toate variabilele. Dacă însă vor fi selectate doar unele
variabile, afişarea valorilor se va efectua doar pentru aceste variabile. Această comandă
permite şi modificarea valorilor variabilelor din fişierul activ de date (Allow Updates).
Ca exemplu, vom afişa doar valorile variabilelor (câmpurilor) Birthweight,
SystolicBlood, AgeInDays sub formă tabelară (Display Mode: „Grid”) după ce aceste
câmpuri au fost selectate din lista derulantă Variables.
Comanda efectivă este:
LIST Birthweight SystolicBlood AgeInDays GRIDTABLE
Frequencies, din grupul „Statistics”, este comanda cu care de obicei se începe analiza
unui nou set de date, pentru că înainte de a face prelucrări statistice mai complicate, vrem să
aflăm câteva informaţii de bază, legate de distribuiţia datelor. Comanda se poate folosi atât
pentru variabile calitative, cât şi pentru variabile cantitative, şi conduce la obţinerea unui
tabel-sinteză care conţine toate valorile variabilelor specificate în lista Frequency of:,

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 100 -
împreună cu frecvenţele absolute (numărul de apariţii), procentele şi procentele cumulate
pentru fiecare valoare a variabilei.
De asemenea, în tabel este trecută şi o schiţă de reprezentare grafică de tip „cu bare”.
În figura de mai jos este prezentat efectul comenzii
FREQ Birthweight
Birthweight in Oz (X1) Frequency Percent Cum Percent
90 1 6.3% 6.3%
95 1 6.3% 12.5%
100 1 6.3% 18.8%
105 2 12.5% 31.3%
120 4 25.0% 56.3%
125 3 18.8% 75.0%
130 1 6.3% 81.3%
135 1 6.3% 87.5%
150 1 6.3% 93.8%
160 1 6.3% 100.0%
Total 16 100.0% 100.0%
95% Conf Limits
90 0.2% 30.2%
95 0.2% 30.2%
100 0.2% 30.2%
105 1.6% 38.3%
120 7.3% 52.4%
125 4.0% 45.6%
130 0.2% 30.2%
135 0.2% 30.2%
150 0.2% 30.2%
160 0.2% 30.2%
Se observă că sunt afişate şi intervalele de încredere 95% (95% Confidence Limits)
pentru fiecare valoare a variabilei. Ele trebuie citite în felul următor: avem încredere 95% că
procentul celor care la naştere cântăresc 90 oz se situează undeva între 0.2% şi 30.2%. Acest
rezultat este bazat pe înregistrarea unui caz din 16! La cursurile de biostatistică din anul al II-
lea se va explica modul în care se obţin aceste evaluări.
În cazul în care se specifică o variabilă de stratificare, se obţin mai multe tabele de
frecvenţă, câte unul pentru fiecare valoare a variabilei de stratificare.
Comanda Means conduce, în plus faţă de datele pe care le-am obţinut deja cu comanda
Frequencies, la obţinerea unor indicatori statistici de centrare şi împrăştiere: media (Mean),
mediana (Median), cuartilele (de 25% şi de 75%), valoarea minimă (Minimum) şi maximă
(Maximum), modul = valoarea având frecvenţa maximă (Mode), varianţa (Variance) şi
abaterea standard (Std Dev). Evident, Obs este numărul total de valori ale variabilei, iar Total
este suma tuturor valorilor variabilei.
În figura de mai jos este prezentat efectul comenzii
UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 101 -
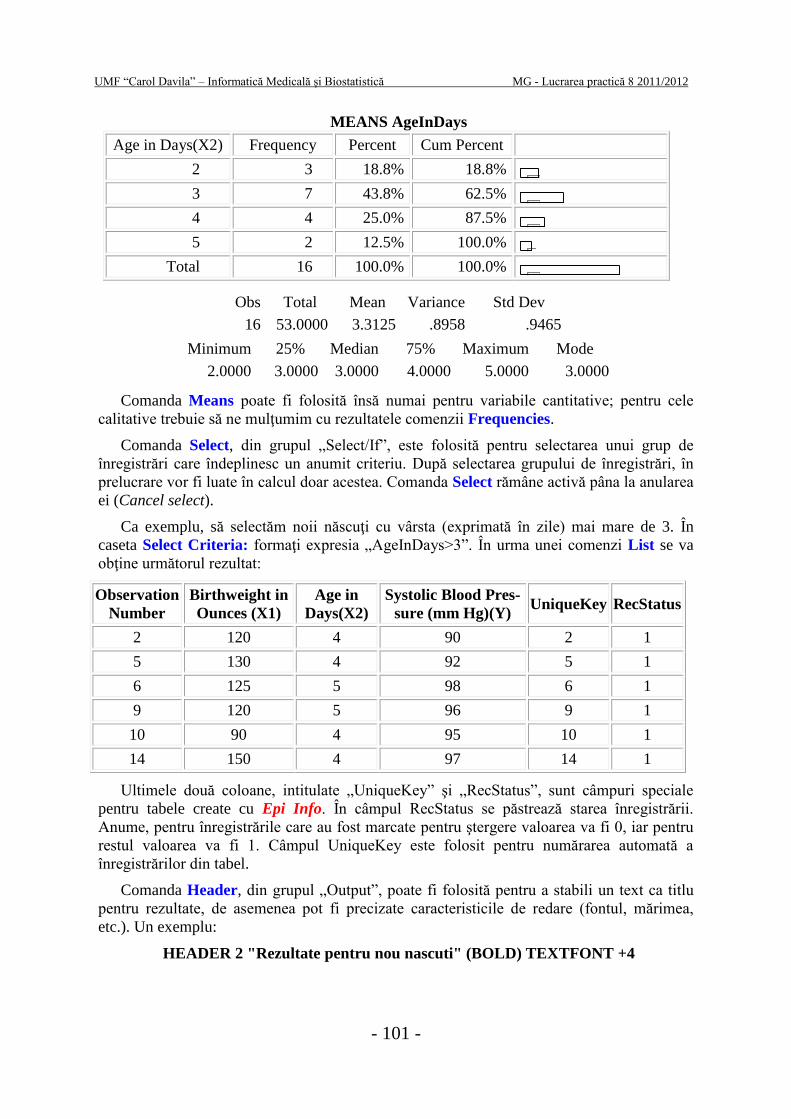
MEANS AgeInDays
Age in Days(X2) Frequency Percent Cum Percent
2 3 18.8% 18.8%
3 7 43.8% 62.5%
4 4 25.0% 87.5%
5 2 12.5% 100.0%
Total 16 100.0% 100.0%
Obs Total Mean Variance Std Dev
16 53.0000 3.3125 .8958 .9465
Minimum 25% Median 75% Maximum Mode
2.0000 3.0000 3.0000 4.0000 5.0000 3.0000
Comanda Means poate fi folosită însă numai pentru variabile cantitative; pentru cele
calitative trebuie să ne mulţumim cu rezultatele comenzii Frequencies.
Comanda Select, din grupul „Select/If”, este folosită pentru selectarea unui grup de
înregistrări care îndeplinesc un anumit criteriu. După selectarea grupului de înregistrări, în
prelucrare vor fi luate în calcul doar acestea. Comanda Select rămâne activă pâna la anularea
ei (Cancel select).
Ca exemplu, să selectăm noii născuţi cu vârsta (exprimată în zile) mai mare de 3. În
caseta Select Criteria: formaţi expresia „AgeInDays>3”. În urma unei comenzi List se va
obţine următorul rezultat:
Ultimele două coloane, intitulate „UniqueKey” şi „RecStatus”, sunt câmpuri speciale
pentru tabele create cu Epi Info. În câmpul RecStatus se păstrează starea înregistrării.
Anume, pentru înregistrările care au fost marcate pentru ştergere valoarea va fi 0, iar pentru
restul valoarea va fi 1. Câmpul UniqueKey este folosit pentru numărarea automată a
înregistrărilor din tabel.
Comanda Header, din grupul „Output”, poate fi folosită pentru a stabili un text ca titlu
pentru rezultate, de asemenea pot fi precizate caracteristicile de redare (fontul, mărimea,
etc.). Un exemplu:
HEADER 2 "Rezultate pentru nou nascuti" (BOLD) TEXTFONT +4
Observation
Number
Birthweight in
Ounces (X1)
Age in
Days(X2)
Systolic Blood Pres-
sure (mm Hg)(Y) UniqueKey RecStatus
2 120 4 90 2 1
5 130 4 92 5 1
6 125 5 98 6 1
9 120 5 96 9 1
10 90 4 95 10 1
14 150 4 97 14 1

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 102 -
Comanda Type, din acelaşi grup „Output”, este analoagă celei anterioare; evident, este
folosită pentru inserarea unei secvenţe de caractere sau a conţinutului unui fişier-text în
fluxul de ieşire (fie cel implicit – monitorul –, sau cel specificat cu comanda RouteOut).
Comanda RouteOut redirectează ieşirea (fluxul de rezultate) către conţinutul unui fişier
cu numele specificat; acest proces va fi terminat prin comanda CloseOut. Rezultatele
obţinute în urma unor comenzi precum Frequencies, List etc. vor fi inserate în conţinutul
fişierului cu numele specificat prin RouteOut.
Deschideţi (din Sample.mdb) cu ajutorul comenzii Read (Import) tabelul
viewEstriolAndBirthweight. Folosiţi comanda RouteOut pentru a redirecţiona rezultatele
obţinute spre fişierul cu numele nume_EBW (evident, în folderul C:\Anul_1). Ce extensie
va avea acest fişier?
Introduceţi titlul „Estriolul şi greutatea la naştere” cu ajutorul comenzii Header bifând
opţiunile „Bold” şi „Italic” şi alegând mărimea fontului de „7”. Introduceţi apoi textul
„Conţinutul fişierului” cu ajutorul comenzii Type bifând şi acum opţiunile „Bold” şi „Italic”,
însă alegând mărimea fontului de 5. Folosiţi comanda List pentru a lista valorile celor două
variabile Birthweight şi Estriol, alegând modul de afişare „Web (HTML)”. Introduceţi un
nou text: „Prelucrări statistice” păstrând parametrii de la textul anterior. Cu ajutorul
comenzii Means calculaţi indicatorii statistici pentru variabila Birthweight, apoi pentru
Estriol. Închideţi fişierul de rezultate cu ajutorul comenzii CloseOut.
Probabil că suntem de acord cu toţii că informaţia prezentată grafic este mai uşor de
„înţeles”. Cele mai utilizate moduri de prezentare grafică sunt diagramele cu dreptunghiuri
(Bar sau Rotated Bar), diagramele de tip rozetă (Pie) şi histogramele (Histogram). Primele
două tipuri sunt potrivite pentru „afişarea” informaţiei despre variabilele care au un număr
„mic” de valori (în special variabile calitative). Ultimul tip este adecvat prezentării
sumarizate a variabilelor care au un număr mare de valori numerice (aşa cum este cazul
greutăţii exprimată în grame, sau a înălţimii exprimată în centimetri), bineînţeles după ce se
realizează gruparea valorilor în câteva intervale de valori.
Comanda Graph, din grupul „Statistics”, este folosită pentru a realiza reprezentări
grafice ale variabilelor din fişierul activ de date. Ca un exemplu, să deschidem (din „sursa”
Sample.mdb) cu ajutorul comenzii Read (Import) tabelul viewSmoke. Cu ajutorul
comenzii Graph vom prezenta valorile variabilei Sex întro diagramă cu bare
(dreptunghiuri). Pentru aceasta în fereastra obţinută prin lansarea comenzii, alegem „Bar” în
lista Graph Type: şi „Sex” în X-AXIS Main_Variable(s):. În Y-AXIS Show values of: va
fi păstrată valoarea implicită „Count”. Titlul diagramei va fi: „Repartitia pe sexe a
persoanelor fumatoare | creat de ... (numele d-voastră)”. După afişare, diagrama obţinută va
fi „exportată” (FileExport...) în format jpg după care va fi redenumită nume_DISX.jpg
alegând şi calea de acces prin opţiunea Export Destination: File Browse.
În mod asemănător se procedează pentru variabila Race pentru care vom alege tipul de
diagramă „Rotated Bar”, apoi pentru variabila Marital pentru care alegem tipul de grafic
„Pie”. Salvaţi cele două diagrame, după ce aţi ales titluri adecvate, în fişiere cu denumirile
nume_DIRACE.jpg respectiv nume_DIMAR.jpg. Pentru variabila cantitativă Age tipul de
diagramă adecvat va fi „Histogram”, pentru care veţi stabili lungimea intervalului de grupare
la 10, iar prima valoare va fi 0. Diagrama obţinută va fi salvată în fişierul
nume_DIAGE.jpg. Ce titlu i-aţi stabili?
În continuare, dorim să reprezentăm grafic variabila Weight separat pentru fiecare
valoare a variabilei Sex. Pentru aceasta, alegem tipul de diagramă „Histogram”, variabila
principală Main_Variable(s): va fi aleasă „Weight”, lungimea intervalului de grupare va fi

UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 103 -
15, titlul principal va fi: „Repartitia greutatii in functie de sex | creat de ... (numele d-
voastră)”, la opţiunea One Graph for Each Value of alegem variabila „Sex”, vom bifa
opţiunea Multiple Graph per Page şi vom introduce valorile 2 pentru No
Across/Horizontal respectiv 1 pentru No Down/Vertical. Vom salva diagramele obţinute
sub numele nume_DIAGESX1.jpg respectiv nume_DIAGESX2.jpg.
Ca un exerciţiu de control, deschideţi tabelul viewOswego din proiectul Sample.mdb.
Redirectaţi rezultatele prelucrărilor următoare spre fişierul nume_OSW. Fiecare comandă va
fi însoţită de un text explicativ, în care veţi specifica ce se obţine cu comanda respectivă.
Listaţi conţinutul fişierului. Pentru variabila Age veţi calcula media pentru persoanele
sănătoase (criteriul „ill=No”) şi separat pentru persoanele bolnave („ill=Yes”).
Reprezentaţi grafic adecvat variabilele Age, Sex, Ill, salvaţi diagramele obţinute în
format JPG şi inseraţi-le, însoţite de comentariile d-voastră referitoare la ceea ce doriţi să
prezentaţi în diagramele respective, într-un document denumit nume_DIOSWEGO.doc.
Tema 37: tabele de contingenţă în Excel
Riscul apariţiei unei maladii (sau riscul de deces) este raportul între numărul de
„evenimente” ce apar întro perioadă de timp specificată (de obicei un an) şi numărul de
indivizi luaţi în considerare (respectiv aflaţi în viaţă) la începutul perioadei.
Tabelul următor, întocmit pentru compararea riscurilor, conţine date privind mortalitatea
la doi ani după primul atac de cord suferit de fumători. (Sursa: Daly, Bourke and McGilvray,
pag. 184.)
Supravieţuirea la 2 ani
Total decedaţi în viaţă
au continuat să fumeze 19 135 154
n-au mai fumat 15 199 214
Total 34 334 368
Acesta este un exemplu tipic de tabel de contingenţă (de tipul 2 2, adică două linii, două
coloane), bordat cu o linie şi o coloană a totalurilor.
Datele primare nu se prezintă însă în acest fel. Preluaţi fişierul LP08_1.xls pentru a vedea
cum sunt înregistrate datele primare. Dacă deschidem fişierul cu Excel, atunci vom folosi de
patru ori (pe patru coloane) însumarea rezultatelor date de funcţia logică IF, condiţiile
logice fiind de forma AND(C2=FALSE,D2=TRUE) şi analoagele.
Preluaţi cele 368 de înregistrări pe o primă foaie de calcul a fişierului nume_CALCULE,
foaie pe care o veţi denumi „Primare”.
Creaţi tabelul de mai sus pe a doua foaie de calcul, de exemplu în domeniul A1:D5
(având grijă să denumiţi această foaie de calcul „Conting”)
Calculaţi în coloana E rata deceselor. (Astfel, pentru întreg lotul de pacienţi, în celula E5
vom plasa formula „=B5/D5” şi vom obţine rata de 9.24%; pentru cei ce au continuat să
fumeze, în celula E3 vom plasa formula „=B3/D3” şi vom obţine rata de 12.34%, iar pentru
cei ce n-au mai fumat, în celula E4 vom obţine rata 7.01%. Evident, ar fi de dorit să plasaţi
în celula E2 un text explicativ, ca de exemplu „Rata deceselor”)
Se va observa o creştere a ratei deceselor în cazul celor ce au continuat să fumeze,
comparativ cu cazul celor care n-au mai fumat. Oare această creştere este „semnificativă”?
Pentru a răspunde la întrebări de acest fel va fi obligatoriu să precizăm „nivelul de
semnificaţie”, altfel răspunsurile sunt lipsite de conţinut.
Să alegem nivelul de semnificaţie uzual 05.0 . Afirmaţia că „fumatul este ASOCIAT
CU decesul timpuriu, după un prim atac de cord” poate fi confirmată (dar nu respinsă!) cu

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 104 -
ajutorul unui test de semnificaţie bazat pe acest nivel de semnificaţie şi pe o anumită
distribuţie hi-pătrat (anume cea cu un singur grad de libertate). Pragul ce trebuie depăşit
pentru a putea confirma afirmaţia este obţinut în Excel cu ajutorul formulei =CHIINV(0.05, 1)
şi va avea valoarea aproximativ 3.84. Oare este el depăşit?
Atenţie, apelând funcţia CHIINV ni se oferă explicaţii detaliate în caseta de folosire a
funcţiei. (Întrebare: este confirmată afirmaţia?)
Afirmaţia că „fumatul este O CAUZĂ A decesului timpuriu, după un prim atac de cord”
poate fi confirmată cu ajutorul unui alt test de semnificaţie bazat pe nivelul de semnificaţie
ales şi pe o anumită distribuţie, normală standard de data aceasta. Pragul ce trebuie depăşit
pentru a putea confirma afirmaţia este obţinut în Excel cu ajutorul formulei =NORMSINV(1–0.05)
şi va avea valoarea aproximativ 1.64. Oare este el depăşit?
Vom încerca să confirmăm ultima afirmaţie („este cauză”) prin efectuarea unui test de
semnificaţie. Compararea celor două populaţii, anume a celor care „n-au mai fumat”,
respectiv a celor care „au continuat să fumeze” se va face la nivelul proporţiilor riscurilor de
deces.
„Ipoteza nulă”, pe care încercăm să o „respingem” în urma efectuării testului de
semnificaţie, este următoarea
21
şi ea exprimă faptul că cele două proporţii „nu diferă semnificativ” una de alta. Ipoteza
alternativă, pe care o vom accepta dacă vom reuşi respingerea ipotezei nule, este următoarea:
21 .
Evident, ea exprimă faptul că riscul de deces este mai mare pentru cei care „continuă să
fumeze”.
Proporţiile riscurilor de deces sunt estimate prin frecvenţele relative observate,
1234.01 p , 0701.02 p , calculate pe baza datelor din eşantioane. Ele sunt în concordanţă
cu ipoteza alternativă!
(Este important să facem această observaţie! Căci în cazul în care frecvenţele relative
observate nu erau în concordanţă cu ipoteza alternativă, am fi confirmat o altă afirmaţie!)
Avem nevoie şi de riscul de deces pentru întreaga populaţie, uşor de calculat
%24.9368
34p . De asemenea, trebuie să reţinem şi „volumele eşantioanelor”, 1541 n ,
2142 n .
Statistica pe care o folosim este
21
12
11)1(
nnpp
ppz iar valoarea obţinută o vom
compara cu valoarea prag z corespunzătoare nivelului de semnificaţie ales. Mai precis,
vom putea respinge ipoteza nulă doar dacă vom constata că zz .
Să ne alegem un nivel de semnificaţie 01.0 . Valoarea prag z va fi obţinută în Excel
prin formula =NORMSINV(0.99)
plasată întro celulă oarecare. (Atenţie, 0.99 este 1 .) Ar trebui să o găsim 2.326.

UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 105 -
Copiaţi întreaga foaie de calcul „Conting” întro foaie nouă, denumită „ZTest”. Plasaţi aici
în celula E2 inscripţia „Frecvenţe relative” iar dedesubt afişaţi conţinutul celulelor cu 4
zecimale (numeric, nu în procente).
Plasaţi în celula A7 inscripţia „Nivelul de semnificaţie”, iar în celula B7 numărul 0.01. În
continuare, plasaţi în celula C7 inscripţia „Valoarea prag”, iar în celula D7 formula =NORMSINV(1-B7)
De asemenea, plasaţi în celula E7 inscripţia „Valoarea statisticii”, iar în celula F7
formula de calcul: =(E3-E4)/SQRT(E5*(1-E5)*(1/D3+1/D4))
În sfârşit, în celula A8 plasaţi, aliniată la stânga, formula logică: =IF(F7>D7,"respingem H0","nu putem respinge H0")
Care este rezultatul?
Modificaţi acum nivelul de semnificaţie, în celula B7, la 0.05. Ce se întâmplă?
Ar trebui, cu nivelul de semnificaţie de 5%, să trageţi concluzia că fumatul în continuare
are efect negativ asupra ratei de supravieţuire a pacienţilor ce au suferit un atac de cord.
Totuşi, cu nivelul de semnificaţie mai mic, de doar 1%, această concluzie nu mai este
susţinută de datele din eşantioane.
Putem afla oare nivelul de semnificaţie „limită” pentru care concluzia este susţinută de
datele din eşantioane?
Plasaţi în celula A9 inscripţia „Valoarea p (riscul acceptării ipotezei alternative)”, iar în
celula B9 formula
=1-NORMSDIST(F7)
Ar trebui să obţineţi 4.08%.
Copiaţi acum întreg conţinutul foii de calcul „ZTest” în altă foaie de calcul, pe care o veţi
redenumi „Gripa”.
Modificaţi aici conţinutul tabelului din A2:D5, aşa încât să apară astfel:
S-au îmbolnăvit de gripă Nu s-au îmbolnăvit de gripă Total
Vaccinaţi 80 420 ?
Nevaccinaţi 150 535 ?
Total ? ? ?
Este vorba despre rezultatul unui studiu organizat de o companie farmaceutică, pentru a
testa eficacitatea unui vaccin nou împotriva gripei. În acest studiu, au fost selectaţi în mod
aleatoriu o serie de locuitori ai unui oraş mare (câţi anume?), care au fost urmăriţi din
noiembrie până în februarie. Dintre aceştia, unii (câţi anume?) au fost vaccinaţi, ceilalţi nu.
Se poate afirma că vaccinul este eficient în combaterea gripei? (Se va alege ca nivel de
semnificaţie 05.0 .) Care este „valoarea p” a acestei afirmaţii?
Tema 38: testul hi pătrat în Excel
Să reluăm afirmaţia „fumatul este ASOCIAT CU decesul timpuriu, după un prim atac de
cord”. Ea poate fi confirmată cu ajutorul unui test hi-pătrat DE SEMNIFICAŢIE.
În Excel calculele necesare confirmării vor exploata tabelul de contingenţă (din domeniul
B3:C4 (care, reamintim, conţine „datele observate”). Acest tabel are două rânduri şi două
coloane. Prin urmare, numărul gradelor de libertate este (2–1)(2–1) = 1.
Copiați tabelul de pe foaia „ZTest” pe o foaie nouă, unica foaie de calcul din fişierul
nume_HIPATRAT.xls. Redenumiți „ChisqTest” această foaie.

MG - Lucrarea practică 8 2011/2012 UMF “Carol Davila” – Informatică Medicală şi Biostatistică
- 106 -
Preluaţi, de asemenea, o copie a rândurilor 7:8 de pe foaia „ZTest” pe foaia „ChisqTest”.
Aceste rânduri conţin nivelul de semnificaţie, valoarea prag, valoarea statisticii, precum şi
formula de „calcul” a deciziei de a respinge sau nu ipoteza nulă.
Formula de calcul a valorii prag, din celula B9, a fost pregătită pentru testul Z; ea trebuie
adaptată pentru testul hi pătrat. Aşadar, o veţi modifica în =CHIINV(B7, 1)
Rămâne doar să adaptăm statistica pe care o folosim şi care de data aceasta este cea a lui
Pearson
2
2
N
NNN
NN
NX cr
rccrr c
, unde rN sunt totalurile pe linii, cN sunt
totalurile pe coloane, iar N este totalul general. Aceste totaluri au fost calculate pe coloana
D şi pe rândul 5.
Formula pe care ar trebui să o plasăm în celula F9 este destul de complicată. Ar fi de
preferat calculul preliminar al expresiilor
N
NN cr , pe care l-am putea efectua de exemplu în
domeniul F3:G4, prin formula =$D3*B$5/$D$5
şi analoagele ei.
Ar urma calculul preliminar al termenilor
2
N
NNN
NN
N crrc
cr
, pe care l-am putea
efectua de exemplu în domeniul I3:J4, prin formula =1/F3*(B3-F3)^2
şi analoagele ei.
Acestea fiind calculate, formula din celula B9 devine o simplă însumare: =SUM(I3:J4)
iar concluzia privind confirmarea afirmaţiei (prin respingerea ipotezei nule) apare automat în
celula A8.
Ar fi interesant să plasaţi în celula A9 inscripţia „Valoarea p (riscul acceptării ipotezei
alternative)”, iar în celula B9 formula de calcul, care în cazul acestui test hi pătrat devine =CHITEST(B3:C4,F3:G4)
Ar trebui să obţineţi o valoare dublă faţă de valoarea pe care aţi obţinut-o (pentru acelaşi
nivel de semnificaţie ales), în celula A9 de pe foaia „ZTest”. Aveţi o explicaţie pentru
această „coincidenţă”?
Tema 39: comanda TABLES în Epi Info
Vom folosi acum modulul Analyze Data al aplicaţiei EpiInfo pentru a „analiza” datele
primare din fişierul LP08_1.xls.
Înainte de toate este necesar să preluăm acest fişier, care nu a fost creat cu aplicaţia
EpiInfo! Pentru aceasta vom folosi comanda Read (Import) din gruparea de comenzi Data.
În caseta de dialog READ va trebui să alegem „Excel 8.0” în lista Data Formats, apoi să
identificăm fişierul în caseta Data Source.
Comenzile date, exprimate în limbajul aplicaţiei, vor fi afişate în fereastra Program
Editor. Ele vor putea fi reluate (eventual după modificări) cu butonul Run din această
fereastră.
UMF “Carol Davila” – Informatică Medicală şi Biostatistică MG - Lucrarea practică 8 2011/2012
- 107 -
Apelaţi comanda List pentru a „vedea” conţinutul fişierului. Observaţi cum sunt
identificate datele, pe linii şi pe coloane. (Este un exemplu simplificat de tabel conţinând
date primare.)
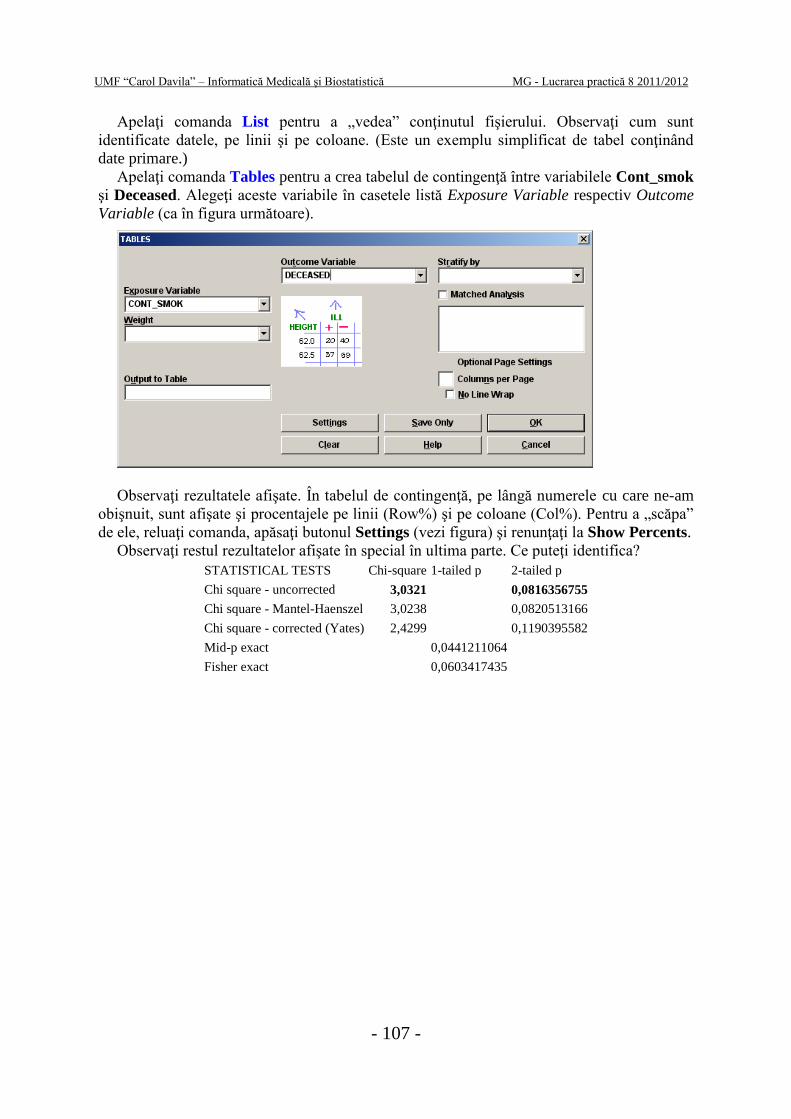
Apelaţi comanda Tables pentru a crea tabelul de contingenţă între variabilele Cont_smok
şi Deceased. Alegeţi aceste variabile în casetele listă Exposure Variable respectiv Outcome
Variable (ca în figura următoare).
Observaţi rezultatele afişate. În tabelul de contingenţă, pe lângă numerele cu care ne-am
obişnuit, sunt afişate şi procentajele pe linii (Row%) şi pe coloane (Col%). Pentru a „scăpa”
de ele, reluaţi comanda, apăsaţi butonul Settings (vezi figura) şi renunţaţi la Show Percents.
Observaţi restul rezultatelor afişate în special în ultima parte. Ce puteţi identifica?
STATISTICAL TESTS Chi-square 1-tailed p 2-tailed p
Chi square - uncorrected 3,0321
0,0816356755
Chi square - Mantel-Haenszel 3,0238
0,0820513166
Chi square - corrected (Yates) 2,4299
0,1190395582
Mid-p exact
0,0441211064
Fisher exact
0,0603417435