un motor eficient de cautare in e-commerce filedomenii adiacente: e-commerce (comert electronic),...
TRANSCRIPT

Ministerul Educatiei Nationale
Universitatea „Ovidius” din Constanta
Facultatea de Matematica si Informatica
Master – Modelare si Tehnologii Informatice
Un motor eficient de cautare in e-commerce
Lucrare de disertatie
Coordonator stiintific: Prof. dr. Popa Constantin
Absolvent: Breda Olivian-Claudiu
Constanta 2018

2
Rezumat / Abstract Rezumat in limba romana: lucrarea curenta are ca tema principala motoarele de
cautare pentru magazine online. Ea e formata dintr-o aplicatie practica, care poate
prezice termeni de cautare introdusi de utilizatorul programului in mod partial eronat,
si are si facilitatea de a sorta rezultatele obtinute – o lista de laptopuri. De asemenea,
exista o parte teoretica, ce isi propune sa prezinte perspective asupra motoarelor de
cautare, trecand printr-un istoric al lor, prezentand modalitatea de functionare a unui
motor de cautare, aratand niste limitari ale motoarelor de cautare si aspecte despre
viitorul motoarelor de cautare. In lucrarea teoretica este descrisa si solutia tehnica,
care au fost scopul si obiectivul de la care am pornit, descrierea algoritmului propus.
Domeniu principal: motoarele de cautare pentru magazine online.
Domenii adiacente: e-commerce (comert electronic), programare C++, algoritmi,
inteligenta artificiala (artificial intelligence), optimizare pentru motoarele de cautare
(SEO, search engine optimization), machine learning (invatare automatizata).
Tipul lucrarii: cercetare.
English language abstract: the current paper has as its main subject search
engines for online stores. The paper consits firstly of a piece of software, which can
correct partially incorrect search terms inserted by the user of the program, and it can
also sort the final results – a list of laptops. There is also a theoretical paper, which
aims to present some perspectives on search engines, going through historical data,
presenting the functioning of a search engine, showing limitations of search engines
and aspects on the future of search engines. In the theoretical paper the technical
solution is also described, what were the aim and objective it started from, and the
description of the proposed algorithm.
Main field: search engines for online stores.
Other fields: e-commerce, C++ programming, algorithms, artificial intelligence,
search engine optimization (SEO), machine learning.
Type of work: research.

3
Cuprins
Rezumat / Abstract ...................................................................................................... 2
Lista figurilor ................................................................................................................ 4
Lista tabelelor .............................................................................................................. 4
1. Introducere .............................................................................................................. 5
2. Istoric si motivatie .................................................................................................... 9
2.1 Istoric al cautarii informatiei ................................................................................ 9
2.2 Modalitatea de functionare a unui motor de cautare ........................................ 17
2.3 Evaluarea eficientei unui motor de cautare ...................................................... 19
2.4 Starea actuala a domeniului ............................................................................. 21
2.5 Limitarile unui motor de cautare generalist ...................................................... 25
2.6 Solutii potentiale pentru paginile de rezultate cautari fara niciun rezultat ......... 27
2.7 Viitorul motoarelor de cautare ale magazinelor online ..................................... 28
3. Solutia propusa ..................................................................................................... 31
3.1 Scop si obiective .............................................................................................. 31
3.2 Descrierea algoritmului .................................................................................... 31
3.3 Utilitatea metodei ............................................................................................. 32
3.4 Analiza implementarii algoritmului .................................................................... 33
3.5 Posibilitati de extindere a algoritmului .............................................................. 36
4. Concluzii ................................................................................................................ 40
Bibliografie................................................................................................................. 42
Anexa 1 – masurarea complexitatii codului ............................................................... 45
Anexa 2 – graficul functiilor tabelului ......................................................................... 48

4
Lista figurilor
Figura 2.1.1 Graf directionat, reprezentand o serie de sase pagini (Langville si
Meyer, 2006)..............................................................................................................11
Figura 2.1.2 Graf pentru o retea de 4 elemente (Langville si Meyer, 2006)...............13
Figura 2.1.3 Cota de piata a cautarilor web, februarie 2018, pentru piata din SUA
(date din partea companiei Jumpshot).......................................................................16
Figura 2.2.1: Unde isi incep consumatorii din SUA cautarile de produse in online
(Keyes, 2017).............................................................................................................18
Figura 2.4.1 Analiza listei de produse a magazinelor online (Baymard.com, 2015)..24
Figura 3.4.1 Exemplu pentru numarul complex ciclomatic al lui McCabe (Tempero,
2018)..........................................................................................................................36
Lista tabelelor Tabel 2.1.1 Primele cateva iteratii ale ecuatiei anterior prezentate asupra grafului
(Langville si Meyer, 2006)..........................................................................................12
Tabel 2.1.2 Cota de piata la nivel mondial, motoare de cautare (StatCounter Global
Stats, 2018)................................................................................................................15
Tabel 2.4.1 Comparatie intre functiile oferite pentru diferite tipuri de cautari in unele
motoare de cautare.....................................................................................................22
Tabel 2.5.1 Tipuri de continut web invizibil (Sherman si Price, 2001)..........................26
Tabel 3.4.1 Indicatori pentru a masura fiabilitatea programului propus (Littlefair,
2018)..........................................................................................................................34

5
1. Introducere Lucrarea de fata, prin continut si aplicatia realizata, se incadreaza in domeniul de
mare actualitate al motoarelor de cautare. Alegerea temei este motivata si sustinuta
de experienta de lucru de peste 10 ani in domeniu. Am putut identifica principalele
probleme ale motoarelor de cautare din magazinele online (de exemplu, o persoana
poate naviga pe site-ul Amazon si cauta o carte; unele rezultate, nerelevante, apar mai
sus ca altele, relevante, si uneori nu se obtin prin cautari rezultatele dorite).
Motivatia principala a lucrarii este data de experienta negativa avuta pe principalele
motoare de cautare pentru magazine online, fie ele din Romania sau pe plan
international. Filtrele Amazon nu functioneaza intotdeauna corect (din perspectiva
noastra), iar cautarea de produse pe site uneori nu returneaza lucrurile potrivite (o
persoana poate cauta ceva si fie nu obtine niciun fel de rezultate, fie obtine rezultate
nedorite). Iar aici este vorba de probleme pe site-ului unei companii gigant, care a avut
in 2017 vanzari de 177,9 miliarde de dolari (Kim, 2018). Intreaga piata romaneasca de
e-commerce a fost estimata de GPeC (Gala Premiilor eCommerce, un eveniment
major pentru piata de e-commerce din Romania) la 2,8 miliarde de euro (Radu, 2018),
asa ca, in mod firesc, magazinele online romanesti au avut bugete mai mici pentru
investitia in motoare de cautare eficiente. Unele probleme sunt mai mari pe site-urile
romanesti de comert online. Am vrut sa aratam o modalitate practica prin care se pot
face unele imbunatatiri la un motor de cautare cu resurse putine. Vom prezenta in
lucrare inclusiv idei noi, potential utile de folosit pentru magazinele online in viitor.
In ceea ce priveste gradul de noutate al lucrarii – solutia propusa de noi vine ca
element de noutate cu un grad de predictie asupra termenilor introdusi de utilizator.
Solutia exista deja in motoare de cautare generaliste (Google, Bing, Yahoo!, Yandex,
Baidu), sau in unele tastaturi pentru telefoanele mobile (SwiftKey pentru Android si
iOS). Ea insa nu a fost implementata in magazinele online suficient de mult. Un
exemplu foarte bun de predictie este cel oferit de tastatura de mobil a celor de la
SwiftKey. Am dorit cu programul propus de noi sa simulam unele din functionalitatile
de predictie pentru un eventual motor de cautare pentru produsele din magazinele
online. O mare parte din facilitatile prezentate sunt deja incluse in SwiftKey.

6
Scopul de la care am pornit lucrarea a fost atat de a implementa ideile pe care le
am in domeniul cautarii pentru motoarele de cautare, de a da un model practic si
verificabil, cat si de a veni cu noi idei, ca posibile rute de prospectat pentru aplicatii
viitoare. Acestea au ramas in plan pur teoretic, urmand a fi implementate de alte
entitati, in incercarea de a imbunatati performantele motoarelor de cautare din prezent.
Descrierea fiecarui capitol:
• 2. Istoric si motivatie - acest capitol are o abordare mai degraba teoretica, am
prezentat aspecte ce tin de partile legate de teorie (istoric, motivatie) ale unui
motor de cautare pentru magazine online.
• 2.1 Istoric al cautarii informatiei - am prezentat in acest subcapitol evolutia
tehnica, de la primele colectii de documente de pe peretii pictati ai pesterilor,
mai departe pe papirus, pergament, hartie si, in final, suport electronic. Am
prezentat sistemele de organizare a informatiei, diferite solutii pentru a cataloga
informatiile. Apoi au fost prezentate detalii despre cum primele motoare de
cautare aveau dificultati in sortarea informatiilor de pe Internet. S-a continuat cu
doi algoritmi de sortare a datelor - PageRank (1998), motorul din spatele
Google, si HITS (tot 1998), un algoritm folosit initial de motorul de cautare
Teoma. Am discutat in continuare despre RankBrain, unui sistem de inteligenta
artificiala bazat pe machine learning pentru a genera rezultatele cautarilor. Au
fost prezentate apoi cotele principalelor motoare de cautare, Google avand
peste 90% din piata, si principalele motoare de cautare avand aproape 99% din
piata motoarelor de cautare la nivel mondial. Am discutat si despre platforma
de cautare din spatele YouTube si cea a Facebook.
• 2.2 Modalitatea de functionare a unui motor de cautare - in acest subcapitol am
aratat pentru inceput unde pornesc cautarile internautilor (Amazon, alte
motoare de cautare importante, retaileri). S-a prezentat si Teoria Setului Difuz
(Fuzzy Set Theory), o ramura a logicii difuze, si rolul ei in cautari. Au fost
descrise in continuare tipurile de cautari in metodele de obtinere a informatiei -
cautari de proximitate / logica difuza / cautari booleene / puterea data unor
termeni.
• 2.3 Evaluarea eficientei unui motor de cautare - in subcapitolul 2.3 au fost
prezentati diferiti KPI (indicatori cheie de performanta, key performance

7
indicators) folositi pentru evaluarea unui motor de cautare - procentul de
utilizatori care folosesc cautarea / numarul de cautari per vizita / procentul de
iesiri din pagina rezultate cautari / numarul mediu de itemi pentru o vizita cu
cautari vs. vizitele care nu au cautari / procentul cautarilor fara niciun rezultat /
cautarile cele mai frecvente / intentia de cautare.
• 2.4 Starea actuala a domeniului – in inceputul subcapitolului a fost prezentata
o comparatie intre functiile oferite pentru diferite tipuri de cautari in unele
motoare de cautare - abilitatea de a interpreta termenul scris gresit „Latpop” /
filtrare in rezultate / sortare rezultate / abilitatea de a interpreta „procesor laptop”
(inclusiv in engleza). Motoarele comparate au fost Google.com / Bing.com /
Amazon.com / Target.com / eBay.com / olx.ro / eMAG.ro / Elefant.ro / F64.ro /
evoMAG.ro. A fost descris apoi un studiu de uzabilitate din 2015 realizat de
echipa de la Baymard Institute, in care au fost analizate cele mai importante 50
de site-uri de e-commerce de pe piata Statelor Unite.
• 2.5 Limitarile unui motor de cautare generalist - in subcapitolul acesta au fost
expuse unele din limitarile motoarelor de cautare generaliste (motoarele de
cautare generaliste sunt motoare de tipul Google, Bing, Yahoo!, care cauta in
surse de date diverse, spre deosebire de cele specializate, cum sunt YouTube
sau Amazon, care cauta doar anumite tipuri de date). Exista diferite tipuri de
continut care nu sunt indexabile de motoarele de cautare generaliste, si
intelegerea acestor lucruri ajuta la alegerea unui motor de cautare pentru nevoi
specifice. Capitolul si-a propus sa arate ca exista anumite cautari pentru care
motoarele de cautare generaliste (Google, Bing, Yahoo!, Yandex, Baidu etc.)
nu sunt cele optime.
• 2.6 Solutii potentiale pentru paginile de rezultate cautari fara niciun rezultat – in
acest subcapitol am dat niste solutii pentru cautarile care in mod tipic nu
returneaza niciun rezultat (de exemplu, cineva cauta un produs care nu exista
pe site, sau tasteaza un cuvant gresit, rezultand un cuvant pentru care nu exista
rezultate in mod tipic). De asemenea, am prezentat concluziile unui studiu
comparativ intre mai multe motoare de cautare.
• 2.7 Viitorul motoarelor de cautare ale magazinelor online - am prezentat aici
primele incercari de aplicare a unor metode de machine learning asupra
eficientei motoarelor de cautare. Am folosit pentru aceasta o resursa de pe site-

8
ul Loop54, care este un SaaS (software ca serviciu, software as a service)
folosit de diferite site-uri pentru a creste vanzarile si ratele de conversie prin
imbunatatirea experientei vizitatorilor (CX, Customer eXperience).
• 3. Solutia propusa - am scris in acest capitol despre solutia software propusa
de catre noi pentru rezolvarea unor parti din problemele identificate in partea
teoretica.
• 3.1 Scop si obiective - in subcapitol au fost descrise, in mod sumar, care a fost
scopul si care au fost obiectivele cercetarii noastre - se poate face relativ simplu
un instrument care sa foloseasca predictia rezultatelor posibile, si apoi sa
filtreze rezultatele obtinute.
• 3.2 Descrierea algoritmului - am descris in acest subcapitol, pas dupa pas, cum
functioneaza algoritmul meu. Se citeste de la tastatura un text. Se verifica daca
programul poate prezice niste termeni alternativi: de exemplu, inversarea unor
litere in cuvant („latpop” vs. „laptop”) – au fost prezentate mai multe solutii de
acest tip. O alta functie a programului este de a cauta si sorta cuvintele in
varianta finala introdusa de la tastatura in baza de date de laptopuri.
• 3.3 Utilitatea metodei - in subcapitol am prezentat utilitatea demersului. In primul
rand, functia de auto-completare termeni, iar apoi, functia de validare date. Mai
departe, odata realizata procedura pe un set de date (programul a fost facut sa
functioneze pe o baza de date pentru laptop-uri), se pot imagina usor solutii
pentru alte tipuri de date de pe site-uri de tip e-commerce.
• 3.4 Analiza implementarii algoritmului - subcapitolul prezinta de ce a fost ales
limbajul de programare C++ si paradigma de scriere cod programare
functionala, apoi procedura, pas cu pas, prin care a fost facut programul.
Ulterior, au fost prezentati cativa indicatori folositi pentru a masura fiabilitatea
software-ului, folosind un program numit CCCC. Au fost detaliati indicatorii
folositi, sumar.
• 3.5 Posibilitati de extindere a algoritmului - este un subcapitol in care am
prezentat diferite posibile viitoare solutii prin care se poate perfectiona aplicatia
noastra.
• Lucrarea se incheie cu un capitol de concluzii si bibliografia aferenta.

9
2. Istoric si motivatie
2.1 Istoric al cautarii informatiei Primele colectii de documente au fost inregistrate pe peretii pictati ai pesterilor.
Apoi, pana la inventia hartiei, anticii romani si greci au inregistrat informatia pe role de
papirus. Unele artefacte de papirus aveau mici etichete atasate rolelor, care ajutau la
gasirea informatiei. Cuprinsul unei lucrari au inceput sa apara in rolele din Grecia in
secolul 2 i.Hr. Ulterior, s-a scris pe pergament, straturi subtiri de piele de animale.
Pentru perioada aceasta, cele mai relevante metode de informatie erau cele pe cale
orala. (Langville si Meyer, 2006)
Inventarea hartiei, cel mai bun suport de stocare a informatiei, a crescut viteza
inregistrarii documentelor si au inceput sa apara colectii tematice. Acest lucru a fost
accelerat puternic prin inventarea presei tipografice de catre Johann Gutenberg in
1450. In anii 1700 au aparut in America biblioteci publice, la initiativa lui Benjamin
Franklin. Astfel, a crescut dorinta de a ierarhiza informatiile. (Langville si Meyer, 2006)
Primul sistem de organizare a informatiei a fost atribuit autorului roman Valerius
Maxiums, care l-a folosit in anul 3 d.Hr. pentru a organiza informatia unei carti ale lui.
Ulterior, au aparut sisteme ca sistemul decimal Dewey (1872), cataloagele de carti
(inceputul anilor 1900), microfilmul (anii 1930), sistemul MARC (MAchine Readable
Cataloging – catalog citibil de catre masini) in anii 1960. In ceea ce priveste cautarile
in baze de date pentru carti au inceput cu un sistem SMART (inteligent) al Cornell in
anii 1960. (Langville si Meyer, 2006)
In anul 1989 stocarea, accesare si cautarea colectiilor de documente a fost
revolutionata de o inventie numita World Wide Web (reteaua pentru lumea intreaga)
de catre fondatorul sau, Tim Berners-Lee. Aceasta a devenit semnalul final al
dominatiei Erei Informatiei si moartea Erei Industriale. Cu toate acestea, volumul mare
de informatie facea cautarile initiale foarte greoaie. (Langville si Meyer, 2006)
Primele motoare de cautare aveau dificultati in ierarhizarea informatiei. Lucrurile s-
au schimbat radical odata cu aparitia Google. Intr-un document datat 29 ianuarie 1998,
"The PageRank Citation Ranking: Bringing Order to the Web" (ierarhizarea bazata pe

10
citari PageRank: aducand ordine in Internet), autorii, dintre care primii doi au fondat
Google (Lawrence Page, Sergey Brin, Rajeev Motwani si Terry Winograd), prezentau
PageRank, un algoritm care dadea o importanta resurselor gasite in cautari, pe masura
volumului linkurilor catre o anumita resursa (cu precizarea ca o resursa putea acorda
o valoare mai mare daca, la randul ei, avea multe linkuri). Autorii concluzionau ca
"folosind PageRank, putem ordona cautarile, in asa fel incat paginile cele mai
importante au pozitii preferentiale. In experimentele facute, asta a dus la rezultate de
calitate ridicata pentru utilizatori". (Page et al., 2018)
Documentul era o continuare a documentului „The Anatomy of a Large-Scale
Hypertextual Web Search Engine” (anatomia unui motor de cautare pe Internet pe
scala larga, si hipertextual), in care Sergey Brin si Lawrence Page prezentau motorul
de cautare in detaliu, inclusiv formula de calculare a PageRank-ului:
„Presupunem ca pagina A are linkuri de la paginile T1 ... Tn (aceste pagini o
citeaza. Parametrul d este un factor de amortizare, care poate fi setat intre 0 si 1. In
general, il stabilim la valoarea 0,85. De asemenea, C(A) este definit ca numarul de
linkuri care pornesc dinspre pagina A spre alte pagini. PageRank-ul paginii A este
definit astfel:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
De notat ca PageRank-ul formeaza o distributie probabilistica peste toate paginile de
Internet, asa ca suma tuturor PageRank-urilor va fi 1. PageRank-ul pentru 26 de
milioane de pagini web poate fi calculat in cateva ore pe o statie de lucru medie.” (Brin
si Page, 1998)
Intr-o lucrare aparuta in 2006 (Langville si Meyer, 2006), formula este
prezentata ca mai jos, o ecuatie simpla a sumelor, radacina carei deriva din cercetarile
bibliometrice, analiza structurii citatiilor intre lucrarile academice. PageRank-ul paginii
Pi, numita r(Pi), este suma tuturor PageRank-urilor paginii care directioneaza catre Pi.
𝑟(𝑃𝑖) = ∑𝑟(𝑃𝑗)
|𝑃𝑗|,
𝑃𝑗∈𝐵𝑃𝑖
unde BPi este setul paginiilor care au trimitere catre Pi (trimit backlink catre Pi in
cuvintele autorilor Sergey Brin si Lawrence Page), si |Pj| este numarul de linkuri

11
externe (catre alte entitati) trimise din pagina Pj. De observat ca PageRank-ul paginilor
care trimit linkuri catre entitate curenta r(Pj) din ecuatia anterior mentionata este
temperat de numarul de recomandari facute de Pj, notat |Pj|. Problema cu ecuatia
respectiva este ca valorile r(Pj), PageRank-ul paginilor care trimit catre pagina Pi, sunt
necunoscute. Pentru a trece peste aceasta problema, autorii ecuatiei au folosit o
procedura iterativa. Astfel, ei au presupus ca, la inceput, toate paginile au un
PageRank egal una cu cealalta (sa zicem, 1/n, unde n este numarul de pagini din
indexul web al lui Google). Acum regula in ecuatia prezentata este urmata pentru a
calcula r(Pi) pentru fiecare pagina Pi din index. Regula dinecuatie este aplicata in mod
succesiv, inlocuind valorile iteratiei anterioare in r(Pj). Introducem si alte notatii pentru
a defini aceasta procedura iterativa. Fie rk+1(Pi) PageRank-ul paginii Pi pentru iteratia
k + 1. Atunci,
𝑟𝑘+1(𝑃𝑖) = ∑𝑟𝑘(𝑃𝑗)
|𝑃𝑗|.𝑃𝑗∈𝐵𝑃𝑖 (Langville si Meyer, 2006)
Procesul este initiat cu r0(Pi) = 1/n pentru toate paginile Pi si este repetat, in
speranta ca scorurile Page Rank vor converge in final catre niste valori stabile.
Aplicand ecuatia de mai sus retelei din figura de mai jos da urmatoarele valori pentru
PageRank, dupa cateva iteratii:
Figura 2.1.1 Graf directionat, reprezentand o serie de sase pagini
(Langville si Meyer, 2006)
1 2
3
6 5
4

12
Iteratia 0 Iteratia 1 Iteratia 2 Rank la iteratia 2
R0(P1) = 1/6 R1(P1) = 1/18 R2(P1) = 1/36 5
R0(P2) = 1/6 R1(P2) = 5/36 R2(P2) = 1/18 4
R0(P3) = 1/6 R1(P3) = 1/12 R2(P3) = 1/36 5
R0(P4) = 1/6 R1(P4) = 1/4 R2(P4) = 17/72 1
R0(P5) = 1/6 R1(P5) = 5/36 R2(P5) = 11/72 3
R0(P6) = 1/6 R1(P6) = 1/6 R2(P6) = 14/72 2
Tabel 2.1.1 Primele cateva iteratii ale ecuatiei anterior prezentate asupra grafului
(Langville si Meyer, 2006)
Un alt algoritm al motoarelor de cautare este si HITS. Un acronim pentru
„Hypertext Induced Topic Search” (cautare de subiecte induse prin hipertext), acesta
a fost un algoritm aflat la baza Teoma, un motor de cautare lansat in 2001 si
achizitionat in acelasi an de un alt motor de cautare, Ask Jeeves Inc. (The Globe si
Mail, 2001)
HITS, algoritm inventat de Jon Kleinberg in 1998 (aproximativ in aceeasi perioada
in care Sergey Brin si Lawrence Page lucrau la algoritmul PageRank), asemenea
PageRank, foloseste structura de URL-uri pentru a crea scoruri de popularitate
asociate cu paginile web. Totusi, HITS are anumite diferente (detalii preluate din
Langville si Meyer, 2006):
• Daca metoda PageRank produce un singur scor de popularitate pentru fiecare
pagina, HITS produce doua.
• In timp ce PageRank-ul este independent de cautare, HITS depinde de
cautarea facuta.
• HITS priveste paginile ca autoritati si huburi. O autoritate este o pagina cu
numeroase linkuri catre ea, si un hub este o pagina cu multe linkuri dinspre ea
spre alte pagini. Paginile de autoritate si huburile merita sa fie numite „bune”
atunci cand urmatoarea afirmatie circulara este valida: „Autoritatile bune au
linkuri catre ele din partea unor huburi bune si huburile bune trimit catre autoritati
bune”. Asadar, fiecare pagina este o masura a autoritatii si o masura a unui
hub.

13
Cum functioneaza algoritmul? (Langville si Meyer, 2006) Fiecare pagina i are un
scor de autoritate xi si un scor de hub yi. Fie E setul tuturor marginilor directionate in
graful de Internet si fie eij marginea directionata de la nodul i catre nodul j. Dat fiind
faptul ca fiecarei pagini i-a fost atribuita initial un scor de autoritate initiala xi si un scor
de hub yi, HITS rafineaza in mod succesiv aceste scoruri calculand:
𝑥𝑖(𝑘)
= ∑ 𝑦𝑗(𝑘−1)
𝑗:𝑒𝑗𝑖𝜖𝐸
𝑦𝑖(𝑘)
= ∑ 𝑥𝑗(𝑘)
𝑗:𝑒𝑗𝑖𝜖𝐸
, unde k = 1, 2, 3, ...
Aceste ecuatii, care au fost ecuatiile originale ale inventatorului lor, Jon
Kleinberg, pot fi scrise intr-o forma matriceala cu ajutorul matricei de adiacenta L a
grafului de URL-uri directionate. (Langville si Meyer, 2006)
1 2
3 4
Figura 2.1.2 Graf pentru o retea de 4 elemente (Langville si Meyer, 2006)
P1 P2 P3 P4
P1 0 1 1 0
L = P2 1 0 1 0
P3 0 1 0 1
P4 0 1 0 0

14
In notarea matriciala, ecuatiile precizate iau forma:
x(k) = LTy(k-1) si y(k) = Lx(k),
unde x(k) si y(k) sunt n x 1 vectori care pastreaza autoritatea aproximativa si scorurile
fiecarui hub la fiecare iteratie. (Langville si Meyer, 2006)
Algoritmul original HITS: (Langville si Meyer, 2006)
1. Se initializeaza y(0) = e, unde e este vectorul coloana al tuturor valorile de 1. Pot
fi folositi si alti vectori de inceput pozitivi.
2. Pana la convergenta, executa:
x(k) = LTy(k-1)
y(k) = Lx(k)
k = k + 1
Se normalizeaza x(k) si y(k).
Lucrurile au evoluat, pe masura ce anii au trecut. Algoritmii s-au tot schimbat,
la un moment dat Google afirma ca au 200 de factori. Intrebat despre asta, in 2010,
CEO-ul Google, Eric Schmidt, a afirmat ca nu ii poate mentiona, pentru ca sunt intr-o
continua schimbare, si, de asemenea, pentru ca sunt un secret comercial al companiei.
(Sullivan, 2010)
Potrivit informatiilor celor de la SearchEngineLand, un site important in lumea
motoarelor de cautare, „RankBrain” este numele dat de catre Google unui sistem de
inteligenta artificiala bazat pe invatare automata (machine-learning artificial
intelligence system) care este folosit pentru a genera rezultatelor cautarilor. Prin
machine learning, un calculator poate sa se invete pe sine insusi cum sa faca o
sarcina, mai degraba decat sa urmeze o procedura predefinita. La data aparitiei
articolului, algoritmul ocupa locul 3 in cele mai importante criterii dupa care un site era
afisat in rezultatele cautarilor. Scopul lui? Interpretarea rezultatelor care nu contin
cuvintele cautate in mod exact, ci cuvinte ce ar putea fi similare. Nevoia de a exista a
algoritmului venit din faptul ca Google procesa in 2016 3 miliarde de cautari zilnic, iar
in 2007 a afirmat undeva intre 20-25% din acele cautari nu au fost observate pana
atunci (nu fusesera probabil cautate niciodata pana atunci). In 2016 e posibil sa fi ajuns
15
la 15% din cautari, in continuare o valoare mare de cautari pentru care algoritmul isi
justifica existenta. Sunt cautari in special formate din multi termeni („long-tail”, cautari
foarte specifice, dar, totusi, numeroase). (Sullivan, 2016)
Luna Google Bing Yahoo! Baidu Yandex
Ru Yandex Altii
2017-02 92,35 2,91 2,17 1,01 0,42 0,35 0,79
2017-03 92,31 2,96 2,2 1,05 0,38 0,35 0,77
2017-04 92,48 2,89 2,01 1,11 0,36 0,35 0,79
2017-05 92,06 2,92 2,07 1,39 0,35 0,34 0,87
2017-06 91,88 2,88 2,18 1,45 0,38 0,38 0,86
2017-07 92,01 2,55 2,23 1,44 0,4 0,49 0,87
2017-08 91,64 2,52 2,32 1,53 0,36 0,5 1,13
2017-09 91,84 2,59 2,33 1,42 0,39 0,41 1,02
2017-10 91,47 2,75 2,25 1,8 0,42 0,41 0,9
2017-11 92,06 2,76 1,73 1,64 0,5 0,36 0,94
2017-12 91,79 2,75 1,61 1,66 0,57 0,39 1,24
2018-01 91,74 2,76 1,83 1,39 0,58 0,36 1,33
2018-02 91,63 2,71 1,94 1,29 0,63 0,33 1,49
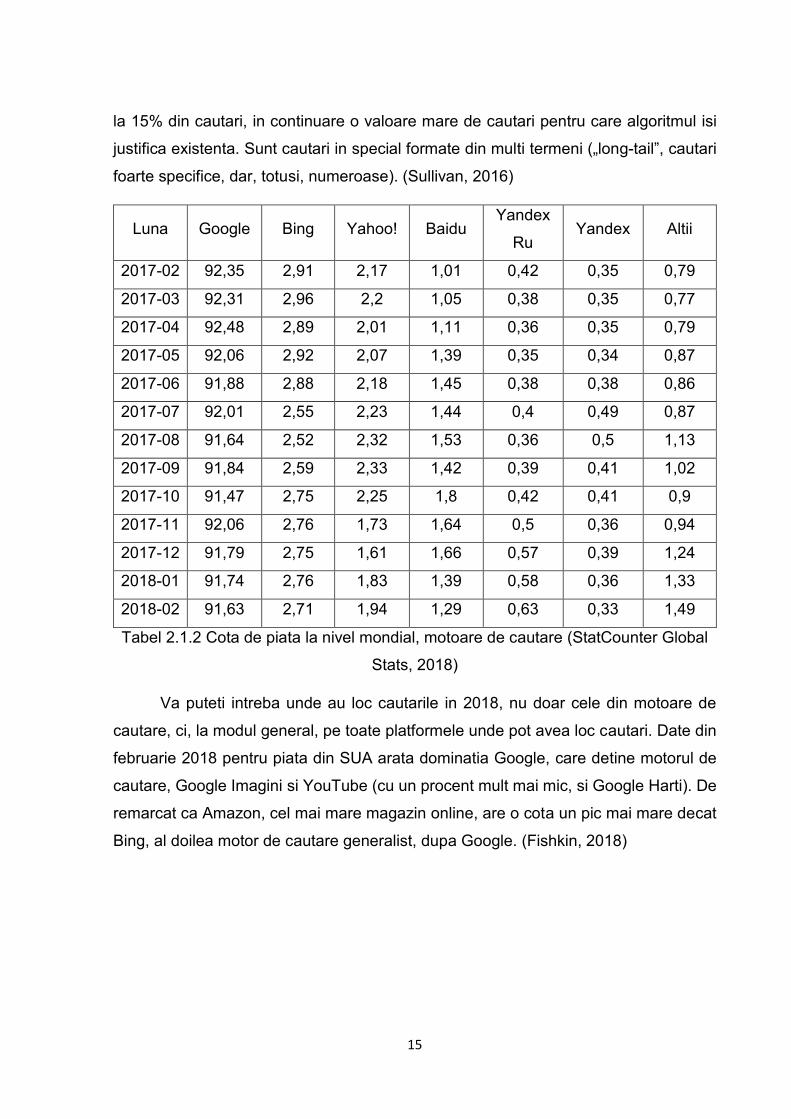
Tabel 2.1.2 Cota de piata la nivel mondial, motoare de cautare (StatCounter Global
Stats, 2018)
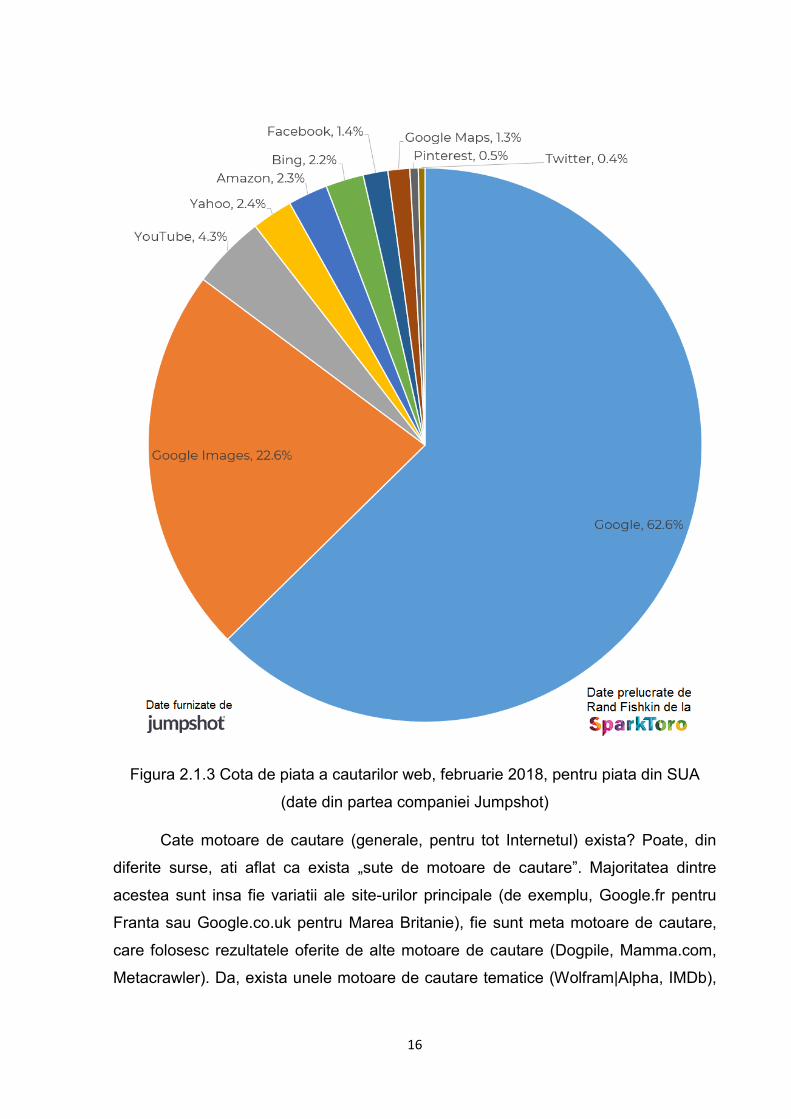
Va puteti intreba unde au loc cautarile in 2018, nu doar cele din motoare de
cautare, ci, la modul general, pe toate platformele unde pot avea loc cautari. Date din
februarie 2018 pentru piata din SUA arata dominatia Google, care detine motorul de
cautare, Google Imagini si YouTube (cu un procent mult mai mic, si Google Harti). De
remarcat ca Amazon, cel mai mare magazin online, are o cota un pic mai mare decat
Bing, al doilea motor de cautare generalist, dupa Google. (Fishkin, 2018)
16
Figura 2.1.3 Cota de piata a cautarilor web, februarie 2018, pentru piata din SUA
(date din partea companiei Jumpshot)
Cate motoare de cautare (generale, pentru tot Internetul) exista? Poate, din
diferite surse, ati aflat ca exista „sute de motoare de cautare”. Majoritatea dintre
acestea sunt insa fie variatii ale site-urilor principale (de exemplu, Google.fr pentru
Franta sau Google.co.uk pentru Marea Britanie), fie sunt meta motoare de cautare,
care folosesc rezultatele oferite de alte motoare de cautare (Dogpile, Mamma.com,
Metacrawler). Da, exista unele motoare de cautare tematice (Wolfram|Alpha, IMDb),

17
dar motoarele cele mai vizitate au un procent apropiat de 95% din piata motoarelor de
cautare. (Grappone si Couzin, 2011)
Exista si alte tipuri de algoritmi care pot sustine un motor de cautare. Platforma
de clipuri video YouTube este al doilea motor de cautare, ce-i drept, specializat, dupa
Google, cu aproximativ 3 miliarde de cautari pe luna, un volum de cautare mai mare
decat cel al Bing, Yahoo!, AOL si Ask.com combinate. (Wagner, 2017) Lucrurile la care
se uita cei 1,5 miliarde de utilizatori inregistrati ai platformei YouTube sunt influentate
de o lista de clipuri asemanatoare. De fiecare data cand un internaut priveste un clip
YouTube, i se prezinta intr-o bara laterala o lista de clipuri asemanatoare. Acea lista e
considerata cel mai important factor in cresterea cotei de piata a YouTube. In una din
putinele explicatii publice despre cum functioneaza formula, o lucrare academica care
prezinta retelele neuronale ale algoritmului, inginerii YouTube o descriu drept una din
"cele mai mari si sofisticate sisteme de recomandare la scala industriala existente in
lume". (Lewis, 2018)
Faptul ca Facebook, cea mai folosita retea sociala la nivel mondial – 2,2 miliarde
de utilizatori activi pe luna, in al 4-lea trimestru al lui 2017 (Statista, 2018) –, cu un
potential enorm in a ajuta utilizatorii in cautarea de produse si servicii pe plan local, cu
un ecosistem format din milioane de pagini de afaceri, date despre locatie ale
utilizatorilor, date de comportament, informatii demografice, rata de angajament, nu a
reusit in anii recenti sa fie un concurent serios pentru Google in cautarile de afaceri
locale poate fi un argument ca a fi relevant in cautari e o sarcina mai grea decat pare
la o analiza superficiala.
2.2 Modalitatea de functionare a unui motor de cautare
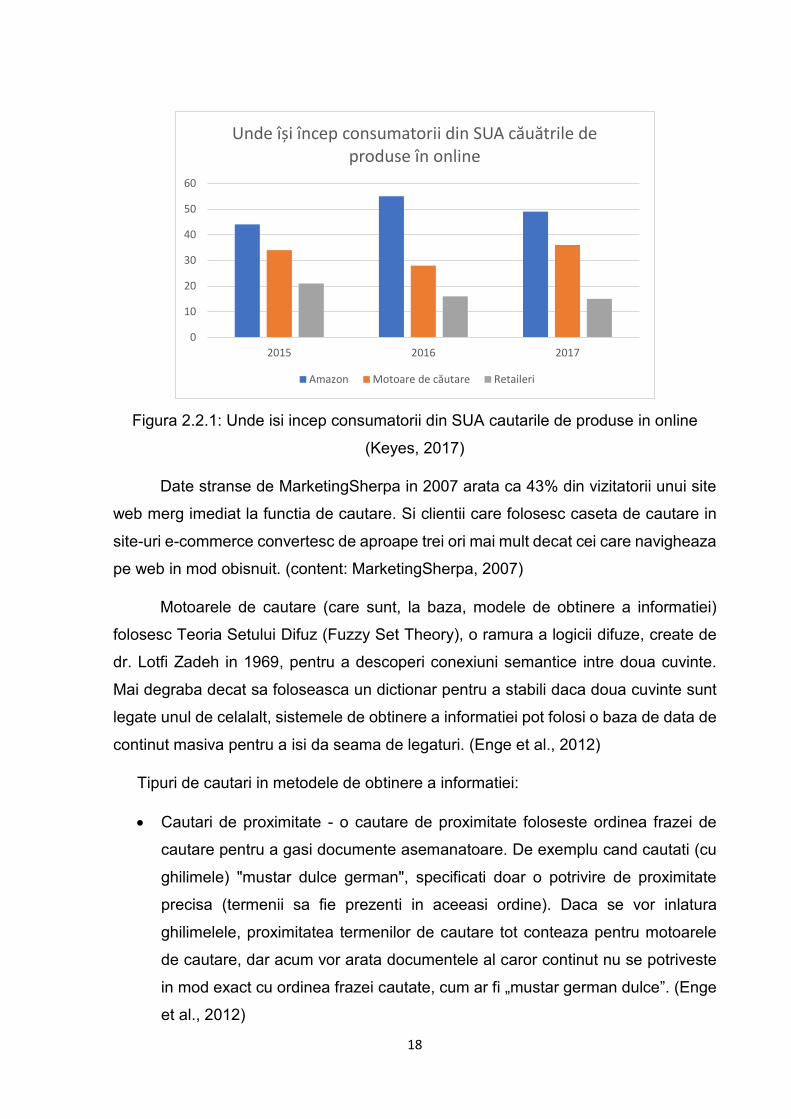
De ce este important, in primul rand, sa discutam despre eficienta unui motor de
cautare? In SUA, cota de piata a celor care isi incep cautarile de produse de cumparat
a scazut pentru Amazon de la 55 la 49% pentru Amazon, in detrimentul motoarelor de
cautare (precum Google), care au crescut de la 28 la 36%, potrivit unui studiu Survata,
citat de Bloomberg. (Keyes, 2017)
18
Figura 2.2.1: Unde isi incep consumatorii din SUA cautarile de produse in online
(Keyes, 2017)
Date stranse de MarketingSherpa in 2007 arata ca 43% din vizitatorii unui site
web merg imediat la functia de cautare. Si clientii care folosesc caseta de cautare in
site-uri e-commerce convertesc de aproape trei ori mai mult decat cei care navigheaza
pe web in mod obisnuit. (content: MarketingSherpa, 2007)
Motoarele de cautare (care sunt, la baza, modele de obtinere a informatiei)
folosesc Teoria Setului Difuz (Fuzzy Set Theory), o ramura a logicii difuze, create de
dr. Lotfi Zadeh in 1969, pentru a descoperi conexiuni semantice intre doua cuvinte.
Mai degraba decat sa foloseasca un dictionar pentru a stabili daca doua cuvinte sunt
legate unul de celalalt, sistemele de obtinere a informatiei pot folosi o baza de data de
continut masiva pentru a isi da seama de legaturi. (Enge et al., 2012)
Tipuri de cautari in metodele de obtinere a informatiei:
• Cautari de proximitate - o cautare de proximitate foloseste ordinea frazei de
cautare pentru a gasi documente asemanatoare. De exemplu cand cautati (cu
ghilimele) "mustar dulce german", specificati doar o potrivire de proximitate
precisa (termenii sa fie prezenti in aceeasi ordine). Daca se vor inlatura
ghilimelele, proximitatea termenilor de cautare tot conteaza pentru motoarele
de cautare, dar acum vor arata documentele al caror continut nu se potriveste
in mod exact cu ordinea frazei cautate, cum ar fi „mustar german dulce”. (Enge
et al., 2012)
0
10
20
30
40
50
60
2015 2016 2017
Unde își încep consumatorii din SUA căuătrile de produse în online
Amazon Motoare de căutare Retaileri

19
• Logica difuza - se refera la un tip de logica ce nu este adevarata sau falsa in
mod categoric. Un exemplu comun este daca o zi este insorita (spre exemplu,
daca este acoperita 50% de nori, este in continuare o zi insorita?). Logica de
acest tip este folosita pentru a detecta si procesa cuvintele tastate gresit. (Enge
et al., 2012)
• Cautari booleene - cautarile booleene folosesc termeni precum AND (si), OR
(sau) si NOT (nu, negatie). Acest tip de logica este folosita pentru a extinde sau
reduce documentele care apar intr-o cautare. (Enge et al., 2012)
• Puterea data unor termeni - acest lucru se refera la importanta unui termen de
cautare particular in cererea transmisa motorului de cautare. Ideea este de a
da un anumit grad de putere unor termeni, pentru a produce rezultate de cautare
superioare. De exemplu, prepozitiile vor primi foarte putina putere in selectarea
rezultatelor, deoarece apar in majoritatea documentelor. Nu ajuta la selectarea
unor documente. (Enge et al., 2012)
2.3 Evaluarea eficientei unui motor de cautare Exista mai mule tipuri de metrici care pot evalua eficienta unui motor de cautare.
Mai jos, cateva din acestea, dintr-un articol aparut pe blogul oficial al companiei Adobe
(Simon, 2015). Sunt mai multi KPI (indicatori cheie de performanta, key performance
indicators):
• Procentul de utilizatori care folosesc cautarea – vizitatorii site-ului de analizat
isi petrec timpul navigand pe site inainte de a merge in caseta de cautare, sau
merg la ea direct de la inceput? Indicatorul, daca are valori mici pentru cei care
folosesc caseta de cautare, poate indica faptul ca exista niste experiente
anterioare neplacute fie cu acest site, fie cu alte site-uri din nisa sau industrie,
poate sugera ca exista o caseta de cautare slab vizibila si insuficient de bine
promovata sau poate arata ca site-ul este atat de prietenos cu vizitatorii, incat
acestia gasesc informatia direct, si nu au nevoie de cautari. Cu instrumente
precum cele de analytics (informatii statistice organizate pentru a fi analizate;
exemplu – Google Analytics sau Omniture pe plan international; in Romania,
Trafic.ro sau Brat.ro - Studiul de Audienta si Trafic Internet, SATI) se poate
masura acest indicator.

20
• Numarul de cautari per vizita – cate cautari face fiecare vizitator. Cea mai buna
situatie este in care face doar una – o persoana cauta ceva, gaseste, si
converteste (adica devine client) imediat. Mai mult de o cautare per vizitator
poate insemna lucruri rele, cum ar fi ca o cautare a fost goala sau a gasit lucruri
nepotrivite. Cei de la Google sau alte motoare de cautare pot evalua si ei acest
indicator – sa zicem ca cineva merge la Google, cauta ceva, intra pe un site, e
nemultumit (probabil), sau e insuficient multumit, si se intoarce la Google si face
click pe un alt rezultat. Acest tip de actiune se numeste „bounce” (intoarcere in
urma unui impact). Vizitatorii intra pe un site, nu gasesc, si se intorc in punctul
de plecare, in cautarea unui rezultat mai bun. Iarasi, acesta este un indicator de
baza in instrumentele tip analytics.
• Procentul de iesiri din pagina rezultate cautari – daca un vizitator paraseste site-
ul din pagina de rezultate cautari obtinuta in urma unei cautari in site, in mod
sigur site-ul are niste probleme la care ar trebui ca detinatorul site-ului sa se
uite. Cautarile ineficiente nu sunt o experienta a consumatorilor pozitiva.
Obiectivul de marketing al zilelor noastre este prezentarea unui vizitator cu
experienta pozitiva in perspectiva sa de client. Clientul ar trebui sa gaseasca ce
cautau inca din prima incercare. De remarcat ca acest procent se coreleaza
puternic cu procentul intrarilor intr-un site. Daca pe un site se intra frecvent pe
o anumita pagina a site-ului, e firesc ca pe acel site sa existe si un procent
ridicat al celor care parasesc site-ul din pagina respectiva. Totul se reduce insa
la procente – este procentul celor care parasesc pagina in linie cu restul
paginilor sau e ceva radical diferit? In functie de raspunsul la aceasta intrebare
se poate decide daca e cazul sa se ia masuri sau nu.
• Numarul mediu de itemi pentru o vizita cu cautari vs. vizitele care nu au cautari.
Cheia in evaluarea acestei diferente e in procente. Aici intra o doza de bun simt
in comparatii, intr-o oarecare experienta. Ce se intampla pe site-urile principale
de e-commerce este ca se testeaza constant lucruri, in cautarea perfectionarii.
• Procentul cautarilor fara niciun rezultat – este una din situatiile in care o veste
proasta poate fi folosita in avantajul magazinului online. E bine ca detinatorul
magazinului sa se uite peste ce cautau acele persoane, care e procentul celor
care nu gasesc niciun rezultat, ce fac dupa ce ajung intr-un punct mort cu
cautarile? Solutii la aceste probleme am incercat sa dam si in programul nostru

21
– de exemplu, daca cineva cauta 4 termeni si pe site se gasesc doar 3,
programul 3 afiseaza cele mai relevante rezultate doar pentru cei 3 termeni.
• Cautarile cele mai frecvente – ce cauta un vizitator? Intelegerea termenilor cei
mai frecvent folositi poate sa ajute detinatorul magazinului online sa inteleaga
de ce au venit internautii pe site. Cu aceasta informatie, se poate imbunatati
navigatia sau apelurile la actiune (butoane precum „Adauga in cos”, „Cumpara”,
„Aboneaza-te la newsletter” – posta electronica, „Contacteaza-ne”), in asa fel
incat vizitatorii sa nu apeleze atat de mult la cautari. E bine ca detinatorul
magazinului sa foloseasca instrumentele de tip analytics pentru a imbunatati
algoritmii de cautare in site. Tot aici e de mentionat si instrumentul Google
Trends (trenduri de cautare din statisticile Google), care permite evaluarea
cautarilor din industrie. Un alt instrument ar putea fi Google Keyword Planner
(planificatorul de cuvinte cheie de la Google), care foloseste termenii cautati
pentru vizitatori, si poate da informatii de tip sezonalitate, sau costuri per click
pentru campaniile de publicitate platita.
• Intentia de cautare – un comportament intangibil, si, cu toate acestea critic de
inteles. Aici este vorba de a masura la ce se gandea vizitatorul in timpul vizitei
pe site. Acest lucru este legat de ROI (return of investment, rata de rentabilitate
a investitiei), pentru ca exista, de exemplu, unii vizitatori care intra pe un site
doar ca sa vada ce mai e nou, si navigheaza liber. Altii sunt acolo strict pentru
ca au nevoie de informatie, si au un model de navigare pentru a obtine informatii
(de exemplu, detalii tehnice despre un produs, sau link catre pagina
producatorului, sau un video explicativ cu produsul). Sansele de conversie
directa a acestor vizitatori sunt mici, dar e de mentionat ca prin mai multe vizite
pe un site, acesta va ramane in mintea vizitatorului, care poate converti in client
la un moment ulterior. Totusi, este de preferat ca in instrumentul de Analytics
sa existe un diferentiator clar intre clientii care fac tranzactii si cei care doar
navigheaza pe un site in scopul obtinerii de informatii.
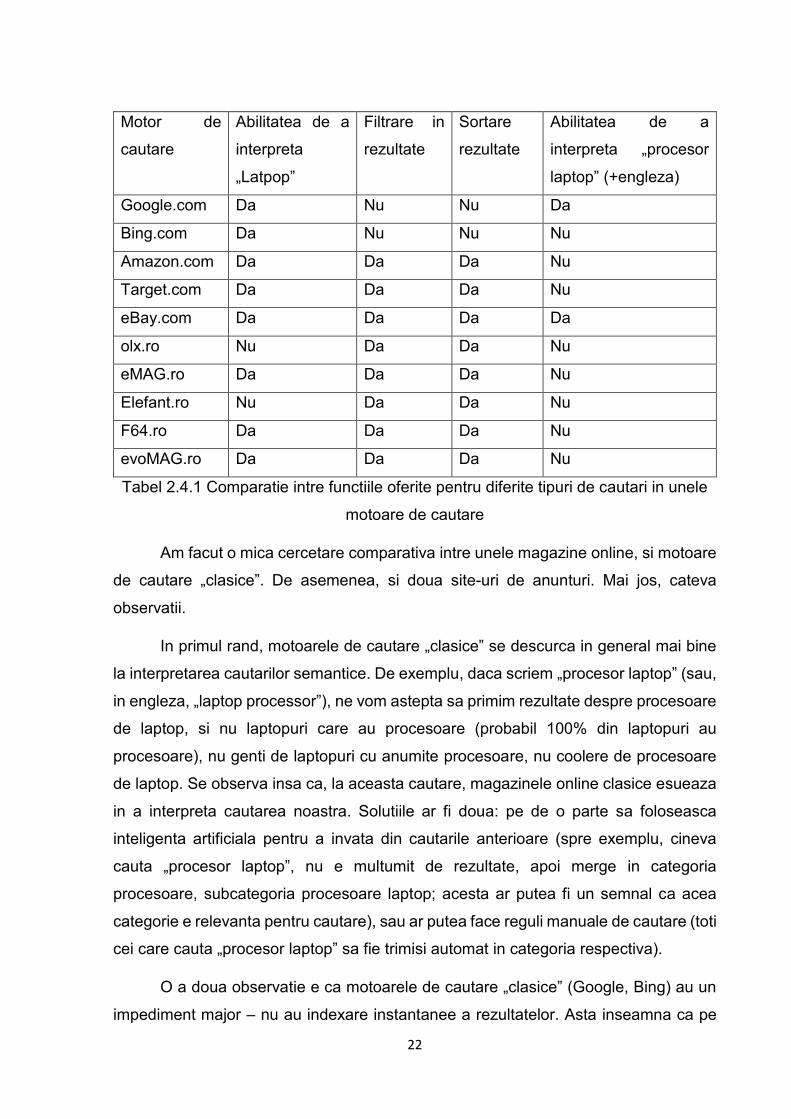
2.4 Starea actuala a domeniului Mai jos, un tabel comparativ intre mai multe motoare de cautare, din Romania, si
pe plan international:
22
Motor de
cautare
Abilitatea de a
interpreta
„Latpop”
Filtrare in
rezultate
Sortare
rezultate
Abilitatea de a
interpreta „procesor
laptop” (+engleza)
Google.com Da Nu Nu Da
Bing.com Da Nu Nu Nu
Amazon.com Da Da Da Nu
Target.com Da Da Da Nu
eBay.com Da Da Da Da
olx.ro Nu Da Da Nu
eMAG.ro Da Da Da Nu
Elefant.ro Nu Da Da Nu
F64.ro Da Da Da Nu
evoMAG.ro Da Da Da Nu
Tabel 2.4.1 Comparatie intre functiile oferite pentru diferite tipuri de cautari in unele
motoare de cautare
Am facut o mica cercetare comparativa intre unele magazine online, si motoare
de cautare „clasice”. De asemenea, si doua site-uri de anunturi. Mai jos, cateva
observatii.
In primul rand, motoarele de cautare „clasice” se descurca in general mai bine
la interpretarea cautarilor semantice. De exemplu, daca scriem „procesor laptop” (sau,
in engleza, „laptop processor”), ne vom astepta sa primim rezultate despre procesoare
de laptop, si nu laptopuri care au procesoare (probabil 100% din laptopuri au
procesoare), nu genti de laptopuri cu anumite procesoare, nu coolere de procesoare
de laptop. Se observa insa ca, la aceasta cautare, magazinele online clasice esueaza
in a interpreta cautarea noastra. Solutiile ar fi doua: pe de o parte sa foloseasca
inteligenta artificiala pentru a invata din cautarile anterioare (spre exemplu, cineva
cauta „procesor laptop”, nu e multumit de rezultate, apoi merge in categoria
procesoare, subcategoria procesoare laptop; acesta ar putea fi un semnal ca acea
categorie e relevanta pentru cautare), sau ar putea face reguli manuale de cautare (toti
cei care cauta „procesor laptop” sa fie trimisi automat in categoria respectiva).
O a doua observatie e ca motoarele de cautare „clasice” (Google, Bing) au un
impediment major – nu au indexare instantanee a rezultatelor. Asta inseamna ca pe

23
un site ca Amazon (o cautare site:amazon.com la Google arata ca Google a indexat
aproximativ 145 de milioane de pagini) sau eMAG (site:eMAG.ro returneaza 25 de
milioane de pagini) Google si Bing sunt nevoiti sa indexeze (sa parcurga cu mici roboti
automat – spideri – intregul site) foarte multe pagini pentru a avea o varianta cat mai
recenta a site-ului. Desigur, asta dureaza zile, uneori saptamani. Asa ca pentru Google
si Bing asta inseamna ca nu au niciodata in index cele mai recente variante ale
paginilor de Internet. Aceste pagini pot suferi modificari, apar noi produse, se schimba
preturile, apar promotii. Din acest motiv, sortarea, cel putin cu tehnologia de astazi, e
foarte dificila. Da, Google si Bing pot „sti” care este pretul laptopurilor si sa
implementeze o solutie de sortare a rezultatelor dupa pret. Dar daca este pretul de
acum cateva zile, sau, mai rau, acum o saptamana, fara nicio informatie despre
promotii si schimbari de pret de ultim moment, rezultatele vor avea o relevanta mai
redusa. Prin urmare, se intampla ce am observat in cercetarea noastra sumarizata in
tabel – motoarele de cautare „clasice” nu au implementate functii de filtrare / sortare
rezultate, si ne asteptam ca situatia sa nu se schimbe prea devreme, din cauza
limitarilor tehnice (motoarele de cautare indexeaza relativ greu un site mare de
e-commerce).
Avem si o ultima observatie, despre predictii cuvinte. Google este un motor de
cautare care, din experienta noastra, are abilitatea de a interpreta foarte bine un
termen tastat, chiar daca e tastat cu greseli de tipul litere inversate, prea multe litere
intr-un cuvant dorit, prea putine. In unele cautari, mai nou, Google chiar ignora o parte
din cuvintele introduse, in incercarea de a fi cat mai relevant. In cautarile noastre, am
observat ca olx.ro si Elefant.ro nu interpreteaza cautarea „latpop” (desigur, scrisa fara
ghilimele, altfel si Google o va vedea ca pe o cautare corecta) ca pe o cautare scrisa
gresit. O tastatura numita SwiftKey, disponibila pe sistemele de operare de mobil iOS
(din 2014) si Android (din 2010) are bune abilitati de a prezice cuvinte, de a invata din
cuvintele pe care utilizatorii le tasteaza pe mobil. Tehnologia din „spatele” Google, sau,
la o scara mai mica, dar in continuare eficienta, a SwiftKey nu consideram ca se
regaseste inca in toate magazinele online. Faptul ca exista o tehnologie accesibila
oricui nu inseamna si ca toate software-urile de predictie cuvinte invata din experienta
altora si le si folosesc.

24
In plus, fata de ce am analizat in tabel (pentru ca e mai dificil de interpretat) este
si abilitatea de a acorda importanta diferita cuvintelor intr-o cautare. De exemplu,
primele cuvinte dintr-o cautare ar trebui sa fie mai importante decat restul. Intr-un
manual de cautare avansata pe Google, se mentioneaza diferenta intre [blue sky]
(cerul albastru si compania Blue Sky Studios) si [sky blue] (albastru cer, o denumire
folosita in alte contexte). (Edu.google.com, 2012) Pentru magazinele online ar trebui
sa conteze ordinea in care sunt scrise cuvintele, si care sunt cuvintele scrise la
inceputul frazei.
Intr-un studiu din 2015 realizat de echipa de la Baymard Institute au fost
analizate cele mai importante 50 de site-uri de e-commerce de pe piata Statelor Unite
(Baymard.com, 2015). Rezultatele sintetice ale studiului:
Figura 2.4.1 Analiza listei de produse a magazinelor online (Baymard.com, 2015)
Cofondatorul institutului a scris un articol despre rezultatele cercetarii efectuate
asupra magazinelor online respective in revista Smashing Magazine. (Holst, 2015)
Cateva observatii din articolul respectiv:
• Doar 16% din site-urile de e-commerce cele mai importante furnizeaza
utilizatorilor o experienta de filtrare a rezultatelor rezonabil de buna. Acest lucru
se intampla din cauza lipsei unor optiuni de filtrare a rezultatelor importante. Din
datele studiului rezulta ca logica de filtrare ineficienta si interfetele nefunctionale
sunt si ele probleme.

25
• 42% din site-urile de e-commerce de top nu au anumite tipuri de filtre specifice
unor categorii pentru cateva din categoriile de produse cele mai importante.
• 20% din site-urile de e-commerce nu au filtre tematice, in ciuda faptului ca vand
produse cu atribute tematice evidente (sezon, stil s.a.m.d.).
• Din site-urile care se ocupa de produse care sunt dependente de o
compatibilitate (de exemplu, o placa de baza e compatibila doar cu anumite
microprocesoare; sau un incarcator baterii poate lucra doar cu anumite baterii),
32% nu au filtre de comptabilitate.
• Testele au aratat ca mai mult de 10 valori filtrate necesita scurtarea (truncation)
rezultatelor pentru a fi afisate in mod corect pe ecran. Cu toate acestea, 32%
din site-uri fie au un design de scurtare insuficient, care face ca utilizatorii sa nu
observe valorile truncate (6%), sau se folosesc de ceva ce testele au aratat ca
e si mai problematic, zone de scroll intern (24%, se refera la casete in care
vizitatorii dau scroll orizontal si/sau vertical pentru a putea citi toata informatia).
• Doar 16 din site-uri promoveaza in mod activ filtre deasupra listei de produse
(aceasta este o pre-conditie pentru situatia cand se depinde mai mult de filtre
decat de categorii produse).
• Abilitatea de filtrare eficienta variaza puternic de la o industrie la alta,
electronicele si industria confectiilor suferind de filtre insuficiente (pentru fiecare
din contextele lor specifice), in timp ce site-urile cu bricolaj sau vanzatorii de
produse generaliste au magazinele cu cele mai bune performante de filtrare
produse.
2.5 Limitarile unui motor de cautare generalist Am discutat in lucrare pana acum doar de lucrurile care pot fi gasite de
motoarele de cautari. Totusi, aceste motoare de cautare au limitarile lor. Sunt unele
aspecte ce tin de ordin tehnic, pe care o sa le discut mai jos, care arata ca un motor
de cautare are limitarile lui in a gasi informatia pe un site. Pe un site de e-commerce,
de exemplu, un motor de cautare clasic (Google, Bing, Yahoo!, Yandex, Baidu) nu
poate adauga produse in cos, nu poate compara produse, nu poate completa un
formular de cerere oferta, nu poate interpreta ce inseamna sa ai un discount la
cumpararea a doua produse in acelasi timp.
26
Motoarele de cautare generaliste (acestea sunt motoare de tipul Google, Bing,
Yahoo!, care cauta in surse de date diverse, spre deosebire de cele specializate, cum
sunt YouTube sau Amazon, care cauta doar anumite tipuri de date) adauga constant
facilitati si imbunatatiri serviciilor lor. Lucruri care sunt invizibile astazi pot deveni
vizibile maine, daca motoarele de cautare vor decide sa adauge capabilitatea de a
indexa lucruri pe care in prezent nu pot sau nu doresc sa indexeze. (Sherman si Price,
2001)
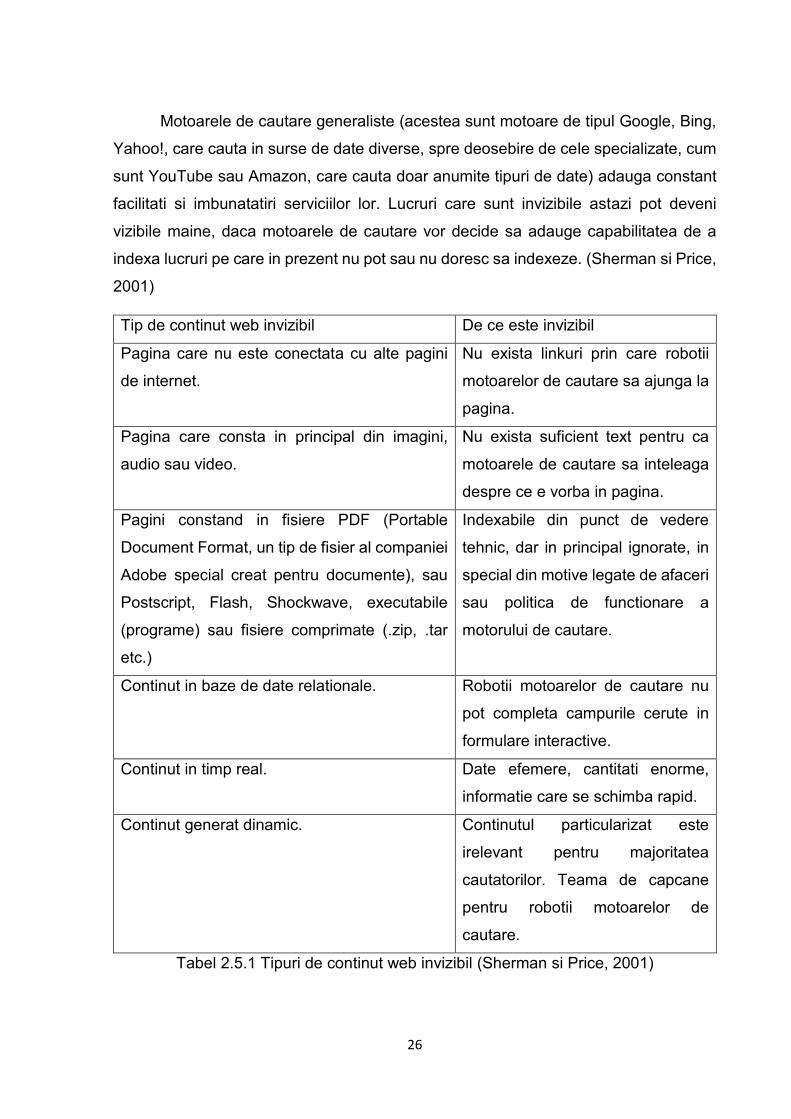
Tip de continut web invizibil De ce este invizibil
Pagina care nu este conectata cu alte pagini
de internet.
Nu exista linkuri prin care robotii
motoarelor de cautare sa ajunga la
pagina.
Pagina care consta in principal din imagini,
audio sau video.
Nu exista suficient text pentru ca
motoarele de cautare sa inteleaga
despre ce e vorba in pagina.
Pagini constand in fisiere PDF (Portable
Document Format, un tip de fisier al companiei
Adobe special creat pentru documente), sau
Postscript, Flash, Shockwave, executabile
(programe) sau fisiere comprimate (.zip, .tar
etc.)
Indexabile din punct de vedere
tehnic, dar in principal ignorate, in
special din motive legate de afaceri
sau politica de functionare a
motorului de cautare.
Continut in baze de date relationale. Robotii motoarelor de cautare nu
pot completa campurile cerute in
formulare interactive.
Continut in timp real. Date efemere, cantitati enorme,
informatie care se schimba rapid.
Continut generat dinamic. Continutul particularizat este
irelevant pentru majoritatea
cautatorilor. Teama de capcane
pentru robotii motoarelor de
cautare.
Tabel 2.5.1 Tipuri de continut web invizibil (Sherman si Price, 2001)

27
2.6 Solutii potentiale pentru paginile de rezultate cautari fara niciun
rezultat In lucrarea "Designing Search: UX Strategies for eCommerce Success", autorul
Greg Nudelman afirma ca nu exista un set de reguli clare care sa garanteze o
implementare a unei pagini care nu returneaza niciun rezultat. Totusi, in lucrare, el
prezinta patru principii generale care pot furniza un bun punct de inceput (Nudelman,
2011):
1. „Nu va fie teama sa spuneti ca nu ati inteles. Indicati clar ca nu ati obtinut niciun
rezultat”, astfel incat clientul sa isi dea seama ca este o problema, si sa o poata
corecta. Daca vizitatorul intelege ca nu sunt rezultate in pagina, problema se
poate remedia prin tastarea altor termeni cheie.
2. „Axati-va pe a furniza o rezolvare. Asigurati-va ca fiecare variabila din pagina
de rezultate de cautare face ceva productiv, pentru a ajuta la rezolvarea
problemei cu niciun rezultat in cautare.” Spre exemplu, cei de la Google, cand
cineva introduce cuvinte ce par ar fi scrise gresit, intreaba internautii "Ati dorit
sa scrieti ...?" (alt termen decat cel introdus).
3. „Creati o strategie de potrivire partiala robusta. Constrangerile prea mari sunt
unele din greselile cele mai frecvente pe care le fac oamenii cand cauta pe site-
uri de e-commerce.” Daca aveti o strategie de rezultate partiale robuste, ati
putea, de exemplu, sa faceti ca o cautare sa raspunda doar la 3 termeni din cei
5 cautati. Google face, de asemenea, si acest lucru.
4. „E bine sa aveti mai multe strategii de livrare a raspunsurilor. Obtineti rezultate
din surse diferite, pentru a furniza rezultate care sa ajute la cautarile fara rezultat
(initiale), dar in acelasi timp pastrati relevanta cautarii initiale efectuate de
vizitator.” Ce se intampla de multe ori in practica este ca sunt site-uri care au
un site de e-commerce si o functie de cautare pentru acesta, au, in plus, si un
blog (deseori pe platforma WordPress), cu o functie de cautare pentru acesta.
O integrare eficienta ar insemna ca atunci cand cineva cauta pe site sa obtina
si rezultate din articolele puse pe blog, dar acestea sa aiba o prioritate mai mica
decat rezultatele cu produse din site.
In concluziile unui studiu ("The effectiveness of Web search engines for retrieving
relevant ecommerce links"), autorii (Bernard J. Jansen si Paulo R. Molina), au tras

28
cateva concluzii despre motoarele de cautare pe care le-au analizat: Excite (un motor
de cautare generalist, existent si astazi), Froogle (un motor de cautare detinut de
Google, in prezent disparut de pe piata), Google, Overture (un motor de cautare
generalist, cumparat de Yahoo! in 2003), Yahoo! Directories (un director web al
Yahoo!, candva foarte popular, in prezent disparut; pe baza lui exista un motor de
cautare specializat): (Jansen si Molina, 2006)
1. Froogle si Yahoo! Directories, doua site-uri care au pus un accent ceva mai
mare pe e-commerce decat alte site-uri, au avut o relevanta statistica mai mare
decat Excite, Google si Overture (intre care nu s-a gasit o diferenta statistica).
De asemenea, nu a fost nicio diferenta statistica intre Froogle si Yahoo!
Directories. Ca raspuns la prima ipoteza a studiului (daca un motor de cautare
personalizat e mai relevant decat unul generalist), se pare ca aceasta este
adevarata, cele mai bune rezultate fiind obtinute din site-uri specializate.
2. A doua ipoteza a studiului a fost daca cumva primele rezultate din pagina de
cautare (de exemplu, rezultatele 1-5) sunt mai relevante decat rezultatele
urmatoare (6-10). Raspunsul a fost negativ, nu s-a observat ca primele rezultate
ar fi mai relevante decat celelalte, pentru toate motoarele de cautare analizate.
3. In fine, o ultima ipoteza era daca cumva rezultatele organice (cele care nu sunt
sponsorizate, apar natural, fara a fi platite, asadar sunt "organice") ar fi mai
relevante decat cele platite. Raspunsul, in aceasta situatie, a fost unul pozitiv.
2.7 Viitorul motoarelor de cautare ale magazinelor online Loop54 este un SaaS (software ca serviciu, software as a service) bazat pe
machine learning folosit de diferite site-uri pentru a creste vanzarile si ratele de
conversie prin imbunatatirea experientei vizitatorilor (CX, Customer eXperience).
Intr-un articol de pe site-ul propriu, compania arata cum machine learning va
schimba viitorul cautarilor in e-commerce, unele tendinte fiind deja aplicate.
(Loop54.com, 2017)
Motoarele de cautare clasice pentru magazine online se axeaza in mod tipic pe
lucruri precum (Loop54.com, 2017):

29
• Indexare eficienta – folosita pentru a localiza rapid datele fara a trebui sa caute
in fiecare coloana de tabel de fiecare data cand o tabela de baze de date este
accesata.
• Reguli de ierarhizare bazate pe atribute - ierarhizeaza rezultatele pe baza
relevantei asteptate a cautarii unui utilizator, folosind o combinatie de metode
dependente de cautarea facuta si altele independente de cautarea efectuata.
• Potrivita a cautarii relaxata (fuzzy) – potrivire a cautarii in mod aproximativ (de
exemplu, „lpatop” pentru „laptop”).
• Variatii – obtinerea unor cuvinte chiar daca nu sunt in forma exacta (carte / carti
/ cartile / cartea)
• Impartire pe elemente (tokenization) – procesul prin care o cautare se imparte
in segmente de cuvinte, fraze, simboluri si alte parti relevante, numite elemente
(tokens).
In evolutia machine learning, algoritmii de cautare au putut face avansuri
tehnologice foarte mari in ceea ce priveste datele comportamentale. Ele au folosit
comportamentul de click, de adaugare in cos si de cumparare pentru a influenta
sortarea rezultatelor (in acest sens, sortarea nu se face exclusiv bazat pe locatia in
metadatele unui produs a unui text cautat). Machine learning a adus abilitatea
motoarelor de cautare de a intelege relatiile dintre produse, chiar inainte ca orice text
sa fie cautat sau sa se fie obtinut date de comportament. In acest fel, un motor de
cautare poate localiza produse similare sau complementare mai departe decat pe baza
unei simple categorii comune sau a unui brand de producator. Poate identifica tipare
complexe in toate metadatele si construi o arhitectura profunda in catalogul de
produse. Pornind de la aceste elemente de baza, un motor de cautare bazat pe
machine learning poate produce o lista de produse asemanatoare care nu au nicio
legatura cu cautarea efectuata. (Loop54.com, 2017).
Furnizarea unei liste de „produse asemanatoare” care sunt similare cu produsul la
care se uita un client poate duce la rate de conversie (din vizitator in client) crescute si
la valori medii ale cosului de cumparaturi marite, si ele. Machine learning permite unui
motor de cautare sa structureze unele relatii dintre produse care nu existat vreodata.
Facand asta, poate realiza o lista inteligenta, auto-perfectibila de „rezultate
asemanatoare”, care sa fie complet diferite de cele oferite in general de sistemele

30
clasice. Mai mult, acest tip de motor de cautare nu are nicio nevoie de a avea date de
comportament pentru a functiona, eliminand din strat problema unui inceput de
functionare mai dificil (de notat, totusi, ca datele de comportament sunt necesare, si ar
fi bine sa fie adaugate motorului pentru a ajuta la sortarea produselor, pentru o
relevanta crescuta). (Loop54.com, 2017)

31
3. Solutia propusa
3.1 Scop si obiective Ne-am propus cu programul la care am lucrat sa arat ca se poate face relativ simplu
un instrument care sa foloseasca o cautare intr-o baza de date de laptopuri, pe doua
planuri – predictia unor termeni introdusi la tastatura in mod partial corect, si apoi
sortarea rezultatelor obtinute pe baza unor criterii de relevanta. Solutia gasita in final
este, inca, inferioara la modul general unor solutii dedicate precum cele ale Google,
Amazon sau eMAG, dar pe anumite segmente, solutia propusa le poate depasi si pe
cele dedicate intr-o eventuala analiza comparativa.
3.2 Descrierea algoritmului Algoritmul propus urmareste introducerea de date si cautarea intr-o baza de date
de laptopuri. Baza de date e formata din numele laptopului si URL-ul aferent de pe
site-ul eMAg.ro. Propunerea noastra e pe doua planuri: pe de o parte, am facut un
algoritm de predictie cuvinte, se introduc unul sau mai multi termeni, iar algoritmul creat
urmareste daca acei termeni sunt tastati, cumva gresit, si in a doua parte am facut o
sortare a rezultatelor care contin termenii cautati.
In prima etapa in care este construit algoritmul se citeste de la tastatura un text,
format doar din anumite caractere (litere, cifre, spatiu, cratima, punct, virgula,
ghilimele). Am facut ca textul introdus sa poata fi prelucrat de la tastatura usor, prin
folosirea unor comenzi speciale, pentru deplasarea cursorului in text, desi textul se
citeste litera cu litera, si nu ca string (text). Exista un numar maxim de cuvinte pentru
care se afiseaza predictii, 5, apoi un cuvant e necesar sa aiba intre 3 si 14 litere, si tot
stringul introdus de la tastatura trebuie sa aiba maxim 60 de caractere cu spatii (si alte
semne permise). Pentru a vedea predictii, se apasa tasta TAB, pentru a cauta direct,
fara predictii, se apasa tasta ENTER.
Programul citeste apoi dintr-un fisier text predictiile posibile pentru fiecare din
cuvinte. Predictiile au fost generate din baza de date folosita (o lista de laptopuri de pe
site-ul eMAG). Se verifica daca programul poate prezice niste termeni alternativi: de

32
exemplu, inversarea unor litere in cuvant („latpop” vs. „laptop”). Apoi, pe baza unei
matrici cu pozitia fiecarei litere de pe tastatura, programul poate interpreta daca
cuvantul „laptop” a fost tastat de fapt ca „lstpop” (pe tastatura, litera „s” este langa litera
„a”). Programul verifica in toate tastele din jurul tastei respective. O alta varianta de
predictie sunt cuvintele care incep cu un string. De asemenea, se cauta si daca un
cuvant a fost tastat cumva cu o litera in plus fata de cuvantul dorit. O alta procedura
verifica daca un termen are o litera in minus.
Daca se gaseste mai mult de o predictie, programul ofera optiunea de a alege intre
predictiile gasite.
In partea a doua a programului, se cauta cuvintele in varianta finala introdusa de la
tastatura in baza de date de laptopuri. Programul este capabil sa inteleaga anumite
echivalari, de exemplu intre termenii „DVD” si „DVD-ROM”, sau „MSDos” si „MS-Dos”
etc.
Daca un termen va fi mai la inceputul stringului introdus, acela va avea prioritate
mai mare in cautari decat un termen aflat la finalul stringului.
Daca un string are 4 termeni, dar in baza de date de laptopuri sunt doar rezultate
in care apar 3 termeni, vor fi afisati aceia.
3.3 Utilitatea metodei In primul rand, functia de auto-completare termeni. Daca se urmeaza pasii descrisi
de noi, se poate obtine o functie de auto-completare termeni foarte buna.
Apoi, functia de validare date. Cand se importa datele din baza de date a eMAG si
se impart datele pe coloane in Excel, si se sorteaza alfabetic, se pot gasi usor erori de
introducere date, care pot fi corectate. Am gasit husa de laptop in categoria laptop-uri,
titluri de laptop puse gresit (fara "," ca separator, sau cu virgula, dar fara spatiul de
dupa), ordine cuvinte din titlu nerespectata.
Mai departe, odata realizata procedura pe un set de date (noi am facut procedura
pentru laptop-uri), se pot imagina usor solutii pentru alte tipuri de date de pe site-uri de
tip e-commerce. Solutia propusa in algoritm este replicabila.

33
De asemenea, cautarea devine mult mai buna prin procesul de intelegere a unor
obiceiuri de tastare (notebook, in loc de laptop; 2 Core in loc de Dual Core), si prin
incercarea de intelegere a sensului unei cautari. Statistici de genul acesta se pot
colecta cu instrumente precum Google Analytics, si apoi folosi pentru a rafina,
constant, cautarile. E un proces repetitiv ce ar trebui sa fie constant.
3.4 Analiza implementarii algoritmului Programul a fost implementat in C++, deoarece am avut experienta ca
programatori cu programele Pascal, C si C++. Avem o oarecare expertiza in PHP si
HTML, dar am preferat sa ne axam pe scrierea de cod si algoritmi, nu neaparat in a
invata sa folosim un limbaj de programare pentru web/Internet.
De asemenea, codul a fost scris in paradigma de scriere programare
functionala, pentru ca avem expertiza in acest tip de programare.
Constructia programului a avut ca prim pas salvarea in calculator a unor pagini
HTML de descriere laptopuri de pe site-ul eMAG. Acestea au fost procesate in
calculator, pentru a obtine, in final, o lista cu nume de laptopuri (randurile impare 1, 3,
5 etc.) si de URL-uri pentru acele laptopuri (randurile pare 2, 4, 6 etc.).
Apoi, din lista respectiva am extras cele mai folosite cuvinte, si le-am folosit
pentru functie de autocompletare cuvinte (utilizatorul completeaza un string, programul
stie la ce e posibil sa ma refer).
In continuare, am facut o lista de conjunctii si prepozitii, care vor fi ignorate in
cautari.
Mai departe, am scris codul pentru a procesa aceste informatii.
Pentru ca in C++ string-urile functioneaza ceva mai atipic decat in Java, si din
cauza faptului ca experienta noastra in programare este limitata, am ajuns sa scriem
foarte mult cod. Sunt aproximativ 2.500 de linii de cod, si aproape 8.000 de cuvinte
folosite. Ce-i drept, codul are numeroase comentarii, si, pentru debugging usor, am
lasat si variantele de testare (sunt multe linii, ulterior comentate, care doar afiseaza un
status, pentru debugging usor).
34
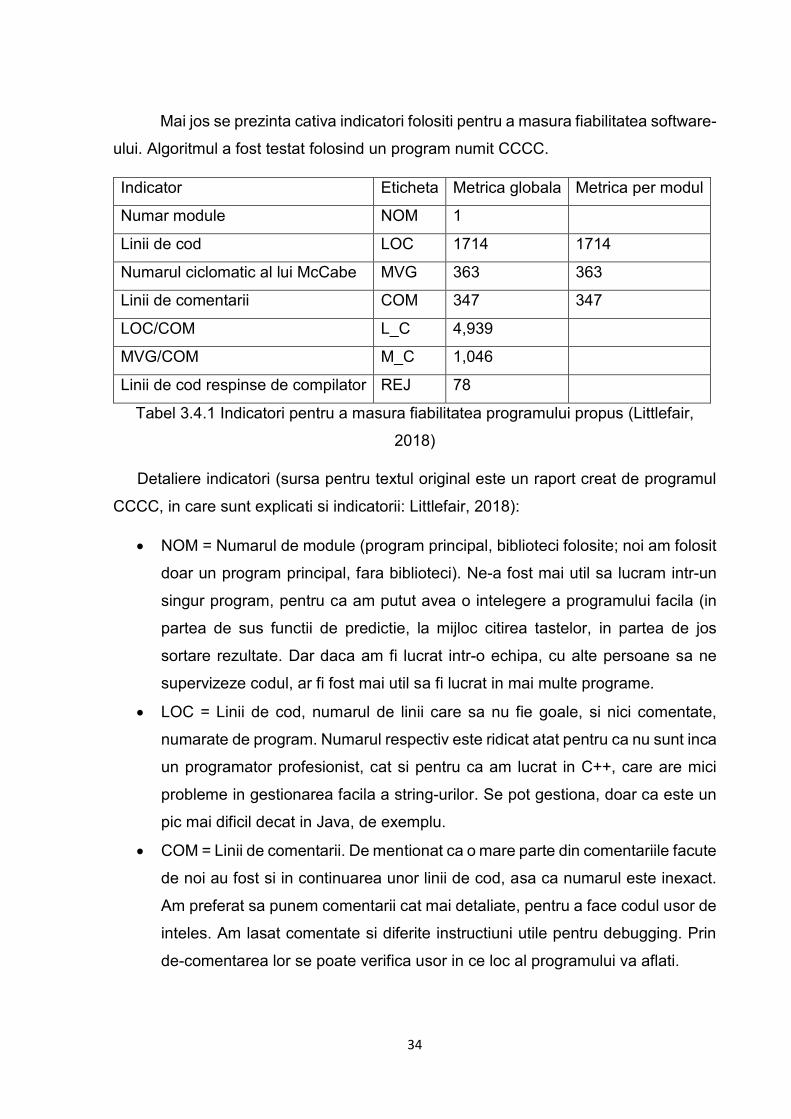
Mai jos se prezinta cativa indicatori folositi pentru a masura fiabilitatea software-
ului. Algoritmul a fost testat folosind un program numit CCCC.
Indicator Eticheta Metrica globala Metrica per modul
Numar module NOM 1
Linii de cod LOC 1714 1714
Numarul ciclomatic al lui McCabe MVG 363 363
Linii de comentarii COM 347 347
LOC/COM L_C 4,939
MVG/COM M_C 1,046
Linii de cod respinse de compilator REJ 78
Tabel 3.4.1 Indicatori pentru a masura fiabilitatea programului propus (Littlefair,
2018)
Detaliere indicatori (sursa pentru textul original este un raport creat de programul
CCCC, in care sunt explicati si indicatorii: Littlefair, 2018):
• NOM = Numarul de module (program principal, biblioteci folosite; noi am folosit
doar un program principal, fara biblioteci). Ne-a fost mai util sa lucram intr-un
singur program, pentru ca am putut avea o intelegere a programului facila (in
partea de sus functii de predictie, la mijloc citirea tastelor, in partea de jos
sortare rezultate. Dar daca am fi lucrat intr-o echipa, cu alte persoane sa ne
supervizeze codul, ar fi fost mai util sa fi lucrat in mai multe programe.
• LOC = Linii de cod, numarul de linii care sa nu fie goale, si nici comentate,
numarate de program. Numarul respectiv este ridicat atat pentru ca nu sunt inca
un programator profesionist, cat si pentru ca am lucrat in C++, care are mici
probleme in gestionarea facila a string-urilor. Se pot gestiona, doar ca este un
pic mai dificil decat in Java, de exemplu.
• COM = Linii de comentarii. De mentionat ca o mare parte din comentariile facute
de noi au fost si in continuarea unor linii de cod, asa ca numarul este inexact.
Am preferat sa punem comentarii cat mai detaliate, pentru a face codul usor de
inteles. Am lasat comentate si diferite instructiuni utile pentru debugging. Prin
de-comentarea lor se poate verifica usor in ce loc al programului va aflati.

35
• MVG = Complexitatea ciclomatica a lui McCabe. Aceasta este o masura a
complexitatii decizionale care formeaza programul. Definitia stricta a acestei
masuratori este ca este un numar de rute linear independente printru grafic
aciclic directionat, care identifica trecerea controlului unui subprogram.
Software-ul analizator CCCC masoara aceasta prin inregistrarea rezultatelor
decizionale distincte continute in fiecare functie, din care rezulta o buna
aproximare a versiunii definite formal a masuratorii. Detaliem indicatorul mai
jos. De mentionat ca recomandarea numarului optim ar fi undeva intre 10 si 15,
iar la noi depaseste 350. Explicatia e ca nu am impartit programul in module
distincte.
• L_C = Linii de cod pentru o linie de comentarii. Prin acest indicator se masoara
densitatea comentariilor, cu atentie la dimensiunea textului programului.
Indicatorul in cazul de fata nu este foarte precis masurat, deoarece nu ia in
considerare comentariile „inline”, cele scrise in continuarea unei linii de cod.
Totusi, consideram ca si asa se poate vedea ca am folosit comentarii in codul
nostru.
• M_C = Complexitatea ciclomatica pe linia de comentarii. Folosind acest
indicator putem afla densitatea comentariilor in ceea ce priveste complexitatea
logica a programului. Detaliem mai jos despre acest indicator.
• REJ = Linii de cod respinse de compilator. Indicatorul e unul specific
programului CCCC, in Dev C++ pe Windows x64 nu ni s-a reportat niciun fel de
eroare de cod.
Mai jos, cateva aspecte despre complexitatea ciclomatica a lui McCabe (sursa – o
prezentare dintr-un curs al Universitatii Auckland - Tempero, 2018).
In primul rand, cu cat este mai complexa structura codului, cu atat este mai dificil
de inteles, e mai probabil sa aiba ceva defect, va fi mai dificil de actualizat, va dura
mai mult timp realizarea lui, si va fi mai dificil de reutilizat.
Apoi, numarul complex ciclomatic al lui McCabe (McCabe’s Cyclomatic Complexity
Number, CCN) masoara numarul de cai liniare independente prin graful programului
(de vazut imaginea de mai jos, cu un graf).
v(F) = e – n + 2,

36
unde F este graful de parcurgere in cod, n numarul de noduri, e numarul de margini.
Intuitiv, pe masura ce numarul complex ciclomatic al lui McCabe devine mai
mare, codul devine mai complex. Diferite surse recomanda un CCN nu mai mare de
10-15.
Figura 3.4.1 Exemplu pentru numarul complex ciclomatic al lui McCabe (Tempero,
2018)
3.5 Posibilitati de extindere a algoritmului In primul rand, ar fi util un generator automat de filtre, se poate face un sistem care
sa foloseasca filtrele cel mai des folosite de alte persoane care au cautat ceva similar,
si sa ne fie afisate cele mai frecvent folosite filtre.
Apoi, pentru produsele in limba romana, ar fi util ca textele produselor sa poata fi
gasite indiferent daca scriu sau nu cu diacritice. Diacriticele sunt si ele de doua tipuri,
cu virgula (S/s, T/t) si cu sedila (S/s si T/t). Un motor de cautare ar trebui sa poata
interpreta orice varianta de a scrie un cuvant – cuvantul „tantari” din „plasa tantari” ar
putea fi scris in 9 feluri distincte, in functie de semnul diacritic folosit pentru „t” (si
numarul se inmulteste cu 4 daca adaugam cele 4 feluri de a scrie a: a\i\a\i).
Cum poate „invata” un site abia lansat pe piata daca se cauta frecvent „notebook”
sau „laptop”? Un raspuns, printre alte posibile solutii, ar putea fi folosirea Google
Trends, un site care permite comparatii intre termeni. Instrumentul respectiv va oferi si
noi sugestii de cautare. S-ar putea face astfel niste dictionare de echivalenta, un motor
de cautare ar putea „intelege” ca „laptop” inseamna, de fapt, „notebook”. Desigur, ar
putea fi utile si niste dictionare de sinonime, dar pentru termenii mai tehnici e posibil

37
sa nu fie suficient de moderne in exprimare, si e posibil sa se piarda termeni mai de
argou, sau exprimari imprecise, dar folosite in practica.
Uneori, lucrurile generate automat pot da erori. De exemplu, da, „notebook” poate
insemna „laptop”, dar nu ar trebui sa fie egal cu „netbook”, desi, aparent, termenii sunt
similari. Ar trebui ca listele generate automat sa fie monitorizate. Sau se poate crea un
algoritm, ceva mai complex, care sa invete din greseli. Prin studierea
comportamentului vizitatorilor, se poate determina daca pentru majoritatea „netbook”
= „notebook” – daca se observa ca vizitatorii nu sunt multumiti de afisarea de
notebookuri la cautari de netbookuri, sau daca se observa ca au fost multe produse
notebook returnate de catre cei care cautau netbookuri, se pot lua masuri corective.
Daca acest proces de corectie are loc, atunci predictia ar putea ramane.
Pentru un site cu trafic ceva mai mare, si cu o prezenta stabilita pe o anumita piata,
ar putea fi utila analiza statisticilor din instrumente precum Google Analytics, care
permit, odata facuta o configurare, monitorizarea cautarilor.
Exista si functii de cautare care sunt specifice anumitor nise. De exemplu, pentru o
persoana care cauta un parfum cu un anumit miros, ar fi relevant sa i se prezinte o
serie de parfumuri realmente asemanatoare cu acel parfum.
Filtrele de sortare pot si ele sa fie rafinate. Sa zicem ca discutam despre un
magazin de ceaiuri. Aici, in plus fata de filtre precum „ceaiuri de menta”, „ceaiuri de
sunatoare” etc., ar putea fi utile filtre pentru diferite metode de a folosi acele ceaiuri –
exista ceaiuri de raceala, pentru slabit, pentru somn linistit, pentru energie s.a. In lumea
tehnologiei, laptopurile pot fi de birou, pentru acasa (multimedia), pentru procesare
video, pentru jocuri, pentru conditii de lucru dificile (cu rezistenta la praf si caderi). Ar
ajuta daca filtrele nu ar fi exclusiv axate pe specificatii tehnice, ci ar fi si fidele intentiei
de cautare a vizitatorilor, asa cum poate fi ea interpretata de detinatorii de magazine
online. Tot legat de laptopuri, „laptopuri noi” ar fi un filtru doar cu laptopuri lansate intr-
o anumita perioada. Similar, o functie de filtrare pentru „laptopuri ieftine”.
O problema intalnita la unele magazine este neconcordanta 100% a filtrelor cu
specificatiile produselor. Pe Amazon.com, de exemplu, unele produse sunt vandute
nu de catre Amazon in sine, ci de terte parti. Este dificil sa impui criterii coerente pentru

38
zeci (poate sute) de milioane de produse, introduse de foarte multi comercianti. Prin
urmare, uneori filtrele Amazon din cautari nu sunt precise.
O functie de sortare care lipseste multor magazine online e functia de sortare dupa
data aparitiei pe piata. E posibil sa ne placa 3 laptopuri in masura egala. Ar fi un
puternic criteriu diferentiator sa pot afla usor data lansarii pe piata a modelelor
respective.
Alte criterii de sortare, care uneori nu apar in magazinele online: sortare dupa top
vanzari (aceasta ar trebui sa fie sortarea implicita), sortare dupa numar si sentiment
comentarii, traficul pentru anumite produse, istoricul celui care cauta, laptopuri
populare in ultima luna, recomandari editoriale (ce recomanda echipa din spatele site-
ului).
Functia de predictii cuvinte (pe masura ce scriem un cuvant, sa ni se sugereze
texte in mod automat) ar putea avea ca functie aditionala abilitatea de a invata care
sunt cele mai des folosite predictii, si sa le afiseze prioritar pe acela. Apoi, sa invete
din comportamentul nostru, de utilizatori logati in site, si, odata ce am facut o selectie,
sa o afiseze pe aceea prioritar. Nu in ultimul rand o functie de tip auto-completare, ca
un utilizator sa scrie 2-3 litere si sa i se indice cuvinte de 10 litere, sa spunem.
Mai departe, se poate lua in considerare comportamentul vizitatorilor - pe ce fac
click cand cauta, daca se intorc la rezultatele cautarii dupa ce vad un anumit produs
(ceea ce poate insemna ca nu au fost multumiti de rezultatul respectiv), ce produse se
cumpara efectiv dupa o cautare, ce produse sunt recomandate mai departe, care este
sentimentul vizitatorilor, asa cum decurge el din comentariile si notele (ratingurile)
lasate pentru produse etc. Daca se intra pe acest proces - cum optimizam rezultatele
de cautare de pe un site? - se poate ajunge cu perfectionarea la un nivel foarte ridicat.
Pe un magazin online ne-am astepta sa gasim si niste rute predefinite foarte bune.
De exemplu, cine cauta „Laptop Asus” ar putea sa fie trimis automat in categoria
„Laptopuri”, cu filtru selectat pe „Asus”. Da, e posibil ca vizitatorii sa se astepte sa
ajunga intr-o pagina de cautari cu filtre posibile, dar e de testat si sugestia noastra.
Suntem aproape siguri ca cine introduce un cod produs in functia de cautare vrea
sa ajunga direct la produsul respectiv. Pentru acel tip de cautari, am implementa o

39
functie de tipul „Ma simt norocos”, prezenta pe motorul de cautare Google, care sa
„trimita” automat internautii la primul (deci, cel mai relevant) rezultat gasit.
O functie pe care am implementat-o in program e ca daca o cautare nu are niciun
rezultat, sa tai din termenii introdusi.
Ar fi util ca un motor de cautare sa stie ca 2 TB = 2.000 GB (pentru hard-diskuri) =
2.048 GB (pentru alte tipuri de cautari, oricum se poate pune ca echivalent). De
asemenea, separatorul ar trebui sa fie atat virgula, cat si punct (sa fie echivalente):
„2.048” = „2,048”.
Exista si cautari foarte provocatoare: „hard-disk laptop”. Poate vizitatorul doreste
sa primeasca o lista de hard-disk-uri pentru laptopuri. Dar acele hard-diskuri pot fi
interne sau externe. Si cautarea ar putea fi si „laptop care sa contina hard-disk, spre
deosebire de alte laptopuri, cu SSD”.
Conjunctiile, in general, ar trebui eliminate din functiile de cautare. „Cel mai nou
laptop” ar putea fi o exceptie, aici ar fi utila o sortare de la cel mai nou spre cel mai
vechi, cu toate laptopurile din magazin.

40
4. Concluzii Am incercat cu demersul nostru sa demonstram ca se poate face un motor de
cautare laptopuri care sa permita predictii cuvinte, si o sortare primara rezultate.
Raman ca posibilitati de explorat diferite sugestii pe care le-am acumulat pe masura
ce am realizat proiectul, de imbunatatire a motoarelor de cautare.
Raspundem mai jos principalelor puncte prezentate in partea introductiva:
• "Am vrut sa aratam o modalitate practica prin care se pot face unele imbunatatiri
la un motor de cautare cu resurse putine." – Am lucrat cu un limbaj de
programare axat mai putin pe partea de web, C++. A fost o prima varianta a
unui potential algoritm mult mai complex. Consideram ca am realizat o
mini-performanta – am facut un algoritm care poate face atat predictii asupra ce
utilizatorul doreste sa tasteze, cat si un mic algoritm de sortare a datelor relativ
eficient. Loc de imbunatatire este suficient, mai ales pe baza unor algoritmi de
machine learning.
• "Vom prezenta in lucrare inclusiv idei noi, potential utile de folosit pentru
magazinele online in viitor." – partea aceasta a fost una din cele mai consistente
in demersul noastra. Din experienta noastra personala in domeniul optimizarii
pentru motoarelor de cautare (SEO), am avut ocazia sa interactionam cu
majoritatea din principalele motoare de cautare, si am acumulat, de-a lungul
anilor, numeroase observatii despre cat de ineficiente pot fi unele cautari. Am
cautat in lucrarea noastra sa prezentam unele posibile solutii la aceste
probleme.
• " Am dorit cu programul propus de noi sa simulam unele din functionalitatile de
predictie pentru un eventual motor de cautare pentru produsele din magazinele
online." – am scris mult cod pentru a face un motor de cautare cu cateva functii
de predictie distincte. Programul nostru este inca departe de modelul pe care l-
am avut, anume tastatura pentru sistemele de operare pentru mobil Android si
iOS numita SwiftKey. Insa, la nivel primar, am folosit o parte din facilitatile oferite
de tastatura si consideram ca le-am imitat cu succes.

41
• " Scopul de la care am pornit lucrarea a fost atat de a implementa ideile pe care
le am in domeniul cautarii pentru motoarele de cautare, de a da un model practic
si verificabil, cat si de a veni cu noi idei, ca posibile rute de prospectat pentru
aplicatii viitoare. Acestea au ramas in plan pur teoretic, urmand a fi
implementate de alte entitati, in incercarea de a imbunatati performantele
motoarelor de cautare din prezent." – am vorbit anterior despre ideile noi pe
care ne-am propus sa le aducem cu lucrarea si cat de bine sau rau am realizat
acest lucru. Legat de testarea abilitatilor – principala remarca negativa pe care
o avem este legata de complexitatea codului. Programul este foarte lung,
consideram ca daca am fi facut si o a doua varianta am fi putut gasi chiar noi
insine alte solutii pentru a comprima codul. Iar un programator cu experienta
bogata in programare ar putea realiza un cod semnificativ mai mic. Per
ansamblu, insa, ne declaram multumiti de rezultatul obtinut pornind de la
obiectivele initiale ale cercetarii. Un motiv in plus de satisfactie este si faptul ca
am comentat o parte insemnata din functiile folosite, si am pastrat, in corp de
comentarii, si instructiunile folosite pentru debugging (cautare erori) in program,
asa ca eventualele erori pot fi reparate mai usor prin de-comentarea liniilor.
Ca o concluzie finala, consideram ca scopul de la care s-a pornit initial – acela de
a face o lucrare prin care sa aratam ca se poate realiza cu un algoritm realizat cu
resurse putine un program care sa aiba abilitatea de a prezice diferite elemente folosite
pentru a introduce date, iar, ulterior, abilitatea de a ierarhiza informatia pe baza unor
criterii –, a fost atins, fie doar si partial. Programul are anumite facilitati atat in etapa
de predictie cuvinte, cat si in etapa ulterioara, de cautare si sortare rezultate. Legat de
partea teoretica a demersului nostru, consideram ca si scopul acestuia a fost atins,
asa cum am aratat deja in comparatia intre obiectivele propuse si cele pe care le-am
indeplinit in mod practic.

42
Bibliografie Baymard.com. (2015). Top 50 E-Commerce Sites Ranked by Product List Usability -
Baymard Institute. [online] Disponibil la: https://baymard.com/ecommerce-product-
lists/benchmark/site-reviews [Accesat 4 Apr. 2018].
Brin, S. si Page, L. (1998). The Anatomy of a Large-Scale Hypertextual Web Search
Engine - Stanford InfoLab Publication Server. [online] Ilpubs.stanford.edu. Disponibil
la: http://ilpubs.stanford.edu:8090/361/ [Accesat 1 Apr. 2018].
content: MarketingSherpa, M. (2007). How to Improve Your Site’s Internal Search &
Lift ROI - 9 Strategies & Tips. [online] MarketingSherpa. Disponibil la:
https://www.marketingsherpa.com/article/interview/how-to-improve-your-sites
[Accesat 3 Apr. 2018].
Edu.google.com. (2012). Lesson 1.5: Word order matters (Text). [online] Disponibil la:
https://edu.google.com/coursebuilder/courses/pswg/1.2/assets/notes/Lesson1.5/Less
on1.5Wordordermatters_Text_.html [Accesat 2 Apr. 2018].
Enge, E., Spencer, S., Stricchiola, J. si Fishkin, R. (2012). The art of SEO. 2nd ed.
Sebastopol, Calif.: O'Reilly Media, pp.47-48.
Fishkin, R. (2018). New Jumpshot 2018 Data: Where Searches Happen on the Web
(Google, Amazon, Facebook, & Beyond) | SparkToro. [online] SparkToro. Disponibil
la: https://sparktoro.com/blog/new-jumpshot-2018-data-where-searches-happen-on-
the-web-google-amazon-facebook-beyond/ [Accesat 5 Apr. 2018].
Grappone, J. si Couzin, G. (2011). Search engine optimization. 3rd ed. Indianapolis,
Ind.: Wiley Pub., p.70.
Holst, C. (2015). The Current State Of E-Commerce Filtering. [online] Smashing
Magazine. Disponibil la: https://www.smashingmagazine.com/2015/04/the-current-
state-of-e-commerce-filtering/ [Accesat 4 Apr. 2018].
Jansen, B. si Molina, P. (2006). The effectiveness of Web search engines for retrieving
relevant ecommerce links. Information Processing & Management, 42(4), pp.1075-
1098.

43
Keyes, D. (2017). Search engines are weakening Amazon’s hold on product search.
[online] Business Insider. Disponibil la: http://www.businessinsider.com/google-
search-engines-weaken-amazon-hold-on-product-search-2017-12 [Accesat 1 Apr.
2018].
Kim, E. (2018). Amazon shares jump after earnings. [online] CNBC. Disponibil la:
https://www.cnbc.com/2018/02/01/amazon-earnings-q4-2017.html [Accesat 31 Mar.
2018].
Langville, A. si Meyer, C. (2006). Google's PageRank and Beyond. Princeton:
Princeton University Press, pp.1-3; 32-33; 115-116.
Lewis, P. (2018). 'Fiction is outperforming reality': how YouTube's algorithm distorts
truth. [online] The Guardian. Disponibil la:
https://www.theguardian.com/technology/2018/feb/02/how-youtubes-algorithm-
distorts-truth [Accesat 1 Apr. 2018].
Littlefair, T. (2018). CCCC Software Metrics Report. CCCC Software Metrics Report.
Loop54.com. (2017). How machine learning is changing e-commerce site-search for
the better. [online] Disponibil la: https://www.loop54.com/blog/machine-learning-is-
changing-ecommerce-site-search-for-the-better [Accesat 4 Apr. 2018].
Nudelman, G. (2011). Designing search. Editia 1. Indianapolis, IN: Wiley, p.12.
Page, L., Brin, S., Motwani, R. si Winograd, T. (2018). The PageRank Citation Ranking:
Bringing Order to the Web. - Stanford InfoLab Publication Server. [online]
Ilpubs.stanford.edu. Disponibil la: http://ilpubs.stanford.edu:8090/422/ [Accesat 31
Mar. 2018].
Pelican, E. (2016). Modele de aproximare si simulare, Curs
Petac, E. (2018). Elaborarea lucrarii de disertatie, Seminar
Radu, A. (2018). Raportul pietei de e-commerce 2017: Romanii au cumparat online de
2,8 miliarde de euro (UPDATE cu infografic). [online] Blogul GPeC. Disponibil la:
https://www.gpec.ro/blog/raportul-pietei-de-e-commerce-2017-romanii-au-cumparat-
online-de-28-miliarde-de-euro [Accesat 31 Mar. 2018].
Sburlan, D. (2016). Modele neconventionale de calcul, Curs

44
Sherman, C. si Price, G. (2001). The invisible web. Medford (New Jersey): Information
today, pp.56, 60.
Simon, M. (2015). The Value and Incremental ROI of Internal Site Search | Adobe
Blog. [online] Adobe Blog. Disponibil la: https://theblog.adobe.com/the-value-and-
incremental-roi-of-internal-site-search/ [Accesat 3 Apr. 2018].
StatCounter Global Stats. (2018). Search Engine Market Share Worldwide |
StatCounter Global Stats. [online] Disponibil la: http://gs.statcounter.com/search-
engine-market-shar
Statista. (2018). Facebook users worldwide 2017 | Statista. [online] Disponibil la:
https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-
worldwide/ [Accesat 1 Apr. 2018].
Sullivan, D. (2010). Schmidt: Listing Google's 200 Ranking Factors Would Reveal
Business Secrets - Search Engine Land. [online] Search Engine Land. Disponibil la:
https://searchengineland.com/schmidt-listing-googles-200-ranking-factors-would-
reveal-business-secrets-51065 [Accesat 31 Mar. 2018].
Sullivan, D. (2016). FAQ: All about the Google RankBrain algorithm - Search Engine
Land. [online] Search Engine Land. Disponibil la: https://searchengineland.com/faq-
all-about-the-new-google-rankbrain-algorithm-234440 [Accesat 31 Mar. 2018].
Tempero, E. (2018). COMPSCI 702: Software Measurement. McCabe’s Cyclomatic
Complexity Number. [online] Disponibil la:
http://www.dcc.ufmg.br/~mtov/pmcc/cyclomatic_complexity_tempero.pdf [Accesat 3
Apr. 2018].
The Globe si Mail. (2001). AskJeeves acquires Teoma search engine. [online]
Disponibil la: https://www.theglobeandmail.com/technology/askjeeves-acquires-
teoma-search-engine/article1185212/ [Accesat 4 Apr. 2018].
Wagner, A. (2017). Are You Maximizing The Use Of Video In Your Content Marketing
Strategy. [online] Forbes.com. Disponibil la:
https://www.forbes.com/sites/forbesagencycouncil/2017/05/15/are-you-maximizing-
the-use-of-video-in-your-content-marketing-strategy/ [Accesat 1 Apr. 2018].
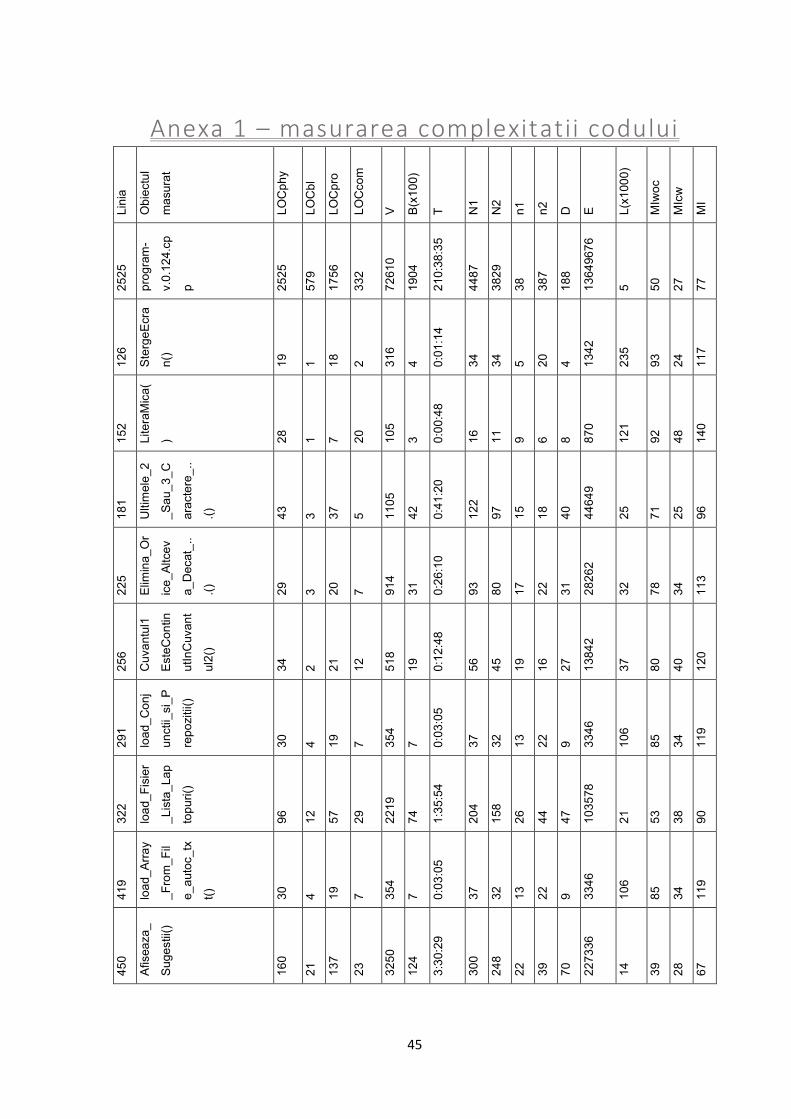
45
Anexa 1 – masurarea complexitatii codului L
inia
Ob
iectu
l
ma
su
rat
LO
Cp
hy
LO
Cb
l
LO
Cp
ro
LO
Cco
m
V
B(x
10
0)
T
N1
N2
n1
n2
D
E
L(x
100
0)
MIw
oc
MIc
w
MI
25
25
pro
gra
m-
v.0
.12
4.c
p
p
25
25
57
9
17
56
33
2
72
61
0
19
04
21
0:3
8:3
5
44
87
38
29
38
38
7
18
8
13
64
96
76
5
50
27
77
12
6
Ste
rge
Ecra
n()
19
1
18
2
31
6
4
0:0
1:1
4
34
34
5
20
4
13
42
23
5
93
24
11
7
15
2
Lite
raM
ica
(
) 28
1
7
20
10
5
3
0:0
0:4
8
16
11
9
6
8
87
0
12
1
92
48
14
0
18
1
Ultim
ele
_2
_S
au
_3_
C
ara
cte
re_
..
.()
43
3
37
5
11
05
42
0:4
1:2
0
12
2
97
15
18
40
44
64
9
25
71
25
96
22
5
Elim
ina
_O
r
ice
_A
ltce
v
a_
Decat_
..
.()
29
3
20
7
91
4
31
0:2
6:1
0
93
80
17
22
31
28
26
2
32
78
34
11
3
25
6
Cuva
ntu
l1
Este
Con
tin
utI
nC
uva
nt
ul2
()
34
2
21
12
51
8
19
0:1
2:4
8
56
45
19
16
27
13
84
2
37
80
40
12
0
29
1
loa
d_
Co
nj
un
ctii_
si_
P
rep
ozitii(
)
30
4
19
7
35
4
7
0:0
3:0
5
37
32
13
22
9
33
46
10
6
85
34
11
9
32
2
loa
d_F
isie
r
_L
ista
_La
p
top
uri
()
96
12
57
29
22
19
74
1:3
5:5
4
20
4
15
8
26
44
47
10
35
78
21
53
38
90
41
9
loa
d_
Arr
ay
_F
rom
_F
il
e_
au
toc_tx
t()
30
4
19
7
35
4
7
0:0
3:0
5
37
32
13
22
9
33
46
10
6
85
34
11
9
45
0
Afisea
za_
Su
ge
stii(
)
16
0
21
13
7
23
32
50
12
4
3:3
0:2
9
30
0
24
8
22
39
70
22
73
36
14
39
28
67
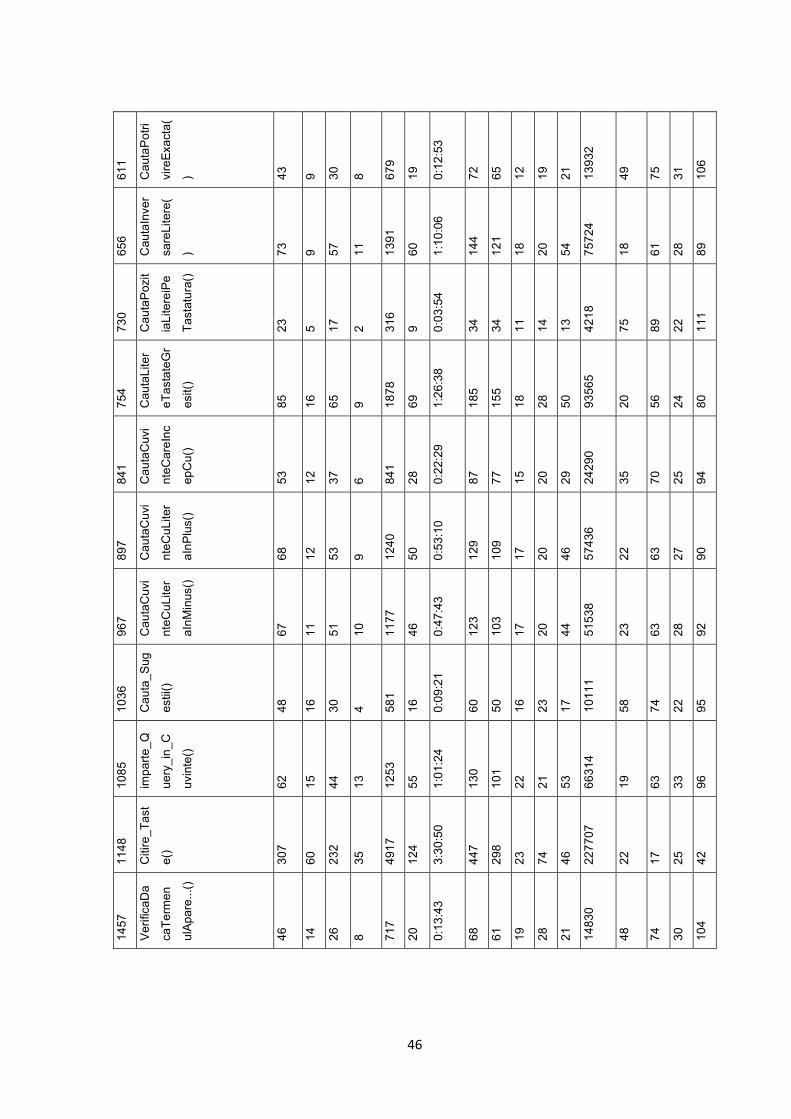
46
61
1
Ca
uta
Po
tri
vir
eE
xa
cta
(
) 43
9
30
8
67
9
19
0:1
2:5
3
72
65
12
19
21
13
93
2
49
75
31
10
6
65
6
Ca
uta
Inve
r
sa
reLite
re(
) 73
9
57
11
13
91
60
1:1
0:0
6
14
4
12
1
18
20
54
75
72
4
18
61
28
89
73
0
Ca
uta
Pozit
iaL
ite
reiP
e
Ta
sta
tura
()
23
5
17
2
31
6
9
0:0
3:5
4
34
34
11
14
13
42
18
75
89
22
11
1
75
4
Ca
uta
Lite
r
eT
asta
teG
r
esit()
85
16
65
9
18
78
69
1:2
6:3
8
18
5
15
5
18
28
50
93
56
5
20
56
24
80
84
1
Cau
taC
uvi
nte
Care
Inc
ep
Cu()
53
12
37
6
84
1
28
0:2
2:2
9
87
77
15
20
29
24
29
0
35
70
25
94
89
7
Cau
taC
uvi
nte
CuL
ite
r
aIn
Plu
s()
68
12
53
9
12
40
50
0:5
3:1
0
12
9
10
9
17
20
46
57
43
6
22
63
27
90
96
7
Cau
taC
uvi
nte
CuL
ite
r
aIn
Min
us()
67
11
51
10
11
77
46
0:4
7:4
3
12
3
10
3
17
20
44
51
53
8
23
63
28
92
10
36
Cau
ta_
Sug
estii(
)
48
16
30
4
58
1
16
0:0
9:2
1
60
50
16
23
17
10
11
1
58
74
22
95
10
85
imp
art
e_
Q
ue
ry_in
_C
uvin
te()
62
15
44
13
12
53
55
1:0
1:2
4
13
0
10
1
22
21
53
66
31
4
19
63
33
96
11
48
Citir
e_
Ta
st
e()
30
7
60
23
2
35
49
17
12
4
3:3
0:5
0
44
7
29
8
23
74
46
22
77
07
22
17
25
42
14
57
Ve
rifica
Da
ca
Te
rme
n
ulA
pa
re..
.()
46
14
26
8
71
7
20
0:1
3:4
3
68
61
19
28
21
14
83
0
48
74
30
10
4
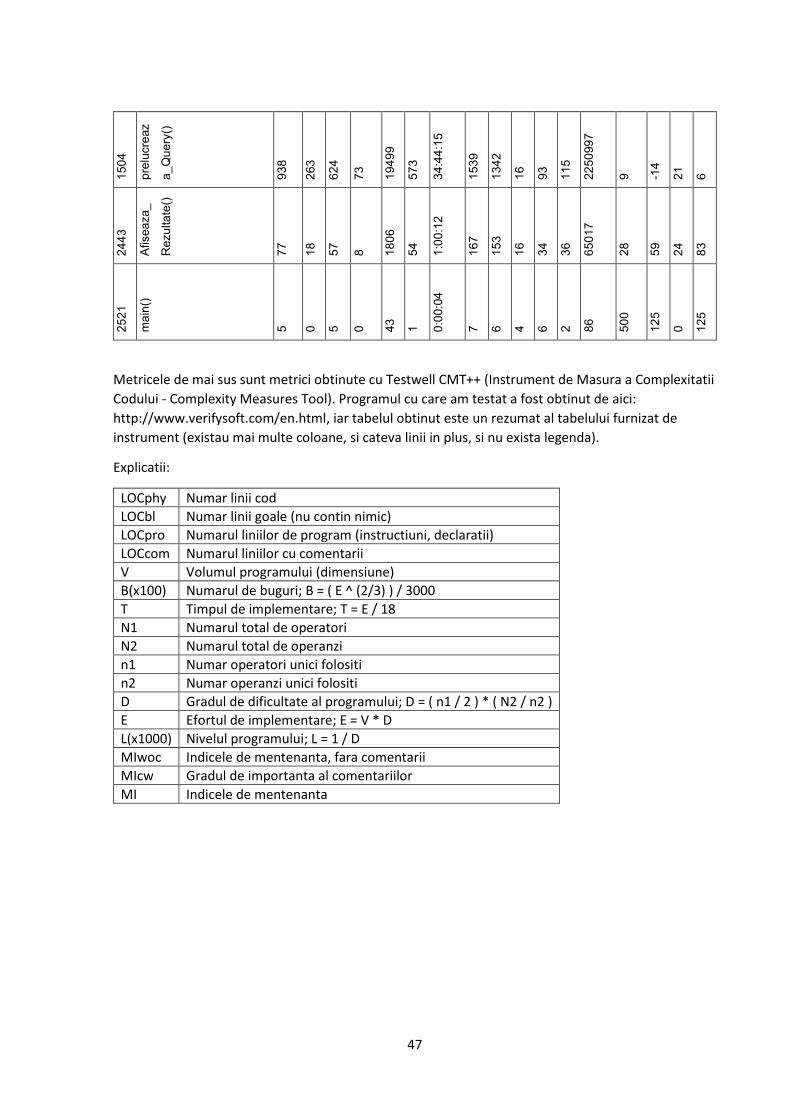
47
15
04
pre
lucre
az
a_
Qu
ery
()
93
8
26
3
62
4
73
19
49
9
57
3
34
:44
:15
15
39
13
42
16
93
11
5
22
50
99
7
9
-14
21
6
24
43
Afisea
za_
Re
zu
lta
te()
77
18
57
8
18
06
54
1:0
0:1
2
16
7
15
3
16
34
36
65
01
7
28
59
24
83
25
21
ma
in()
5
0
5
0
43
1
0:0
0:0
4
7
6
4
6
2
86
50
0
12
5
0
12
5
Metricele de mai sus sunt metrici obtinute cu Testwell CMT++ (Instrument de Masura a Complexitatii
Codului - Complexity Measures Tool). Programul cu care am testat a fost obtinut de aici:
http://www.verifysoft.com/en.html, iar tabelul obtinut este un rezumat al tabelului furnizat de
instrument (existau mai multe coloane, si cateva linii in plus, si nu exista legenda).
Explicatii:
LOCphy Numar linii cod
LOCbl Numar linii goale (nu contin nimic)
LOCpro Numarul liniilor de program (instructiuni, declaratii)
LOCcom Numarul liniilor cu comentarii
V Volumul programului (dimensiune)
B(x100) Numarul de buguri; B = ( E ^ (2/3) ) / 3000
T Timpul de implementare; T = E / 18
N1 Numarul total de operatori
N2 Numarul total de operanzi
n1 Numar operatori unici folositi
n2 Numar operanzi unici folositi
D Gradul de dificultate al programului; D = ( n1 / 2 ) * ( N2 / n2 )
E Efortul de implementare; E = V * D
L(x1000) Nivelul programului; L = 1 / D
MIwoc Indicele de mentenanta, fara comentarii
MIcw Gradul de importanta al comentariilor
MI Indicele de mentenanta

48
Anexa 2 – graficul functiilor tabelului Mai jos, se pot vedea functiile programului – cum se intrepatrund, care dintre ele
folosesc alte functii, si in ce alte functii sunt apelate. Sagetile nu au o semnificatie
aparte.
49