rezumatul tezei de doctorat - doctorat.tuiasi.ro · manipula ușor date de dimensiuni mari pe de o...
TRANSCRIPT

UNIVERSITATEA TEHNICĂ “GHEORGHE ASACHI” DIN IAŞI
APLICAȚII ALE INTELIGENȚEI ARTIFICIALE ÎN
MODELARE ȘI ANALIZA DATELOR
Rezumatul tezei de doctorat
Inf. Tiberius Dumitriu Conducător de doctorat: prof.dr.ing. Vasile-Ion Manta
IAȘI, 2019

UNIVERSITATEA TEHNICA "GHEORGHE ASACHI' DIN IA$I
RECTORATUL
Citre
Vi facem cunoscut c5, in ziua de 21 septembrie 2019 la ora 10:30 in Sala
Consiliu a Facultalii de Automaticd 5i Calculatoare, va avea loc suslinerea publici a tezei
doctorat intitulatS:
"Aplicafii ale inteligentei aftificiale in modelare 9i analiza datelor"
elaborati de domnulTlBERIUS DUMITRIU in vederea conferirii titlului gtiinfific de doctor.
Comisia de doctorat este alcituiti din:
1 LAZAR Corneliu, Prof.dr.ing., Universitatea Tehnicd "Gheorghe Asachi" din lagi preSedinte
2. MANTA Vasile-lon, Prof.dr.ing., Universitatea Tehnic5 "Gheorghe Asachi" din lagi conducitor de doctorat
3. MOCANU Mariana lonela, Prof.dr.ing., Universitatea Politehnica din Bucuregti referent oficial
4. pOTOLEA Rodica, Prof.dr.ing., Universitatea Tehnici din Cluj-Napoca referent oficial
5. UNGUREANU Florina, Prof.dr.ing., Universitatea Tehnici "Gheorghe Asachi" din laSi referent oficial
Cu aceastd ocazie vi invitdm si participa[i la suslinerea publici a tezei de
doctorat.
de
de
cA$cAVAL secdlr universitate,
,ffi^"*"r,,

Cuprins
Cuprins
Capitolul I Introducere ...................................................................................................... 1 I.1 Obiective ................................................................................................................... 2 I.2 Diseminarea rezultatelor. Contribuții și lucrări publicate ........................................ 3 I.3 Structura tezei ........................................................................................................... 7
Capitolul II Metode evolutive utilizate în modelare şi optimizare ................................. 9
Capitolul III Modelare și clasificarea datelor ................................................................ 12 III.1 Modelare. Definiţii şi concepte ........................................................................... 12
III.2 Clasificarea datelor ............................................................................................. 13
Capitolul IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor
procese chimice ........................................................................................................... 15 IV.1 Aplicaţii ale algoritmului evolutiv ICA ............................................................... 15
IV.1.1 Optimizarea operatorilor specifici ICA .................................................. 15 IV.1.2 Rezultate experimentale ......................................................................... 18
IV.2 Aplicații ale rețelelor neuronale artificiale (RNA) în eliberarea de medicamente .. 19 IV.2.1 Hidrogelurile .......................................................................................... 19 IV.2.2 Procedee experimentale .......................................................................... 20
IV.2.3 Modelarea și structura RNA.................................................................... 20 IV.2.4 Rezultate și discuții ................................................................................. 21
IV.3 Rețelele neuronale artificiale pentru predicția comportării reologice a unor
suspensii coloidale cu nanoparticule de argint ................................................... 22
IV.3.1 Aspecte generale și tendințe recente în studiile efecutate asupra unor
suspensii coloidale cu nanoparticule de argint ...................................... 22
IV.3.2 Procedee experimentale .......................................................................... 22 IV.3.3 Criterii de evaluare .................................................................................. 24 IV.3.4 Rezultate și discuții ................................................................................. 24
IV.4 Analiza automată a porozității unor hidrogeluri bazată pe procesarea imaginilor
obținute prin microscopie electronică de baleiaj (SEM) .................................... 25 IV.4.1 Procesarea imaginilor ............................................................................. 26
IV.4.2 Analiza porozității .................................................................................. 27 IV.4.3 Rezutate și discuții .................................................................................. 28
Capitolul V Aplicații ale inteligenței artificiale în analiza datelor bazate pe semnale
biologice ...................................................................................................................... 29 V.1 Evaluarea memoriei pe termen scurt pe baza încărcării cognitive folosind
semnale EEG ...................................................................................................... 29
V.1.1 Paradigmele încărcării cognitive .............................................................. 29 V.1.2 Paradigma n-back. Memoria de lucru și încărcarea cognitivă ................. 29 V.1.3 Achiziția datelor EEG............................................................................... 30 V.1.4 Analiza și clasificarea datelor ................................................................... 30 V.1.5 Indicatori pentru măsurarea încărcării cognitive ...................................... 31
V.1.6 Rezultate experimentale ........................................................................... 31 V.2 Analiza performanțelor dispozitivelor de achiziție EEG ...................................... 32 V.3 Metodă genetică de optimizare multiobiectiv bazată pe comutarea între

Cuprins
clasificatori ......................................................................................................... 34
V.3.1 Achiziția și preprocesarea setului de date ............................................... 35 V.3.2 Algoritm genetic cu comutare pentru selecția de trăsături ...................... 36
V.3.3 Rezultate experimentale ........................................................................... 36 V.4 Metodă evolutivă de selecție a atributelor EEG folosind extensii temporale ...... 37
V.4.1 Selecția de trăsături din semnale EEG..................................................... 37 V.4.2 Achiziția datelor EEG............................................................................... 37 V.4.3 Preprocesarea datelor EEG și extragerea de trăsături............................... 38
V.4.4 Metodă evolutivă pentru selecția de trăsături ........................................... 38 V.5 Analiza tehnicilor de clasificare a emoțiilor ......................................................... 40
V.5.1 Interfaţa om - calculator ........................................................................... 40 V.5.2 Achiziţia şi preprocesarea datelor ............................................................ 41 V.5.3 Analiza şi clasificarea datelor ................................................................... 42
V.5.4 Rezultate experimentale ........................................................................... 43
Capitolul VI Concluzii generale ...................................................................................... 45
Lista publicațiilor ............................................................................................................. 48
Bibliografie selectivă ........................................................................................................ 50

1
Capitolul I Introducere
Dorința de a putea prognoza evoluția diverselor evenimente sau a unor procese, a condus la necesitatea obținerii unor metode statistice, matematice sau informatice care să poată manipula ușor date de dimensiuni mari pe de o parte, iar pe de altă parte să ofere soluții optime care să țină cont și de modificările dinamice ce au loc chiar în timpul acelor evenimente sau procese. Achiziția și analiza datelor pentru un eveniment petrecut într-o anumită perioadă de timp poate oferi indicii temeninice asupra tendințelor viitoare ale procesului sau evenimentului studiat. Pe de altă parte, extargerea informațiilor relevante din datele culese în timp este vitală pentru analiza și prognoza tendințelor viitoare ale unui fenomen. Operații de analiză a datelor statistice sunt utilizate astăzi în domenii precum: marketing, meteorologie, chimie, medicină, industrie, transporturi, științe sociale, politice, economice etc.
Progresul obţinut în ultimele decenii în domeniul tehnologiei a dus la creşterea puterii de calcul facilitând cercetarea şi crearea unor noi algoritmi, a unor categorii și tehnici predictive deosebite precum arborii de decizie, algoritmii evolutivi, rețelele neuronale sau mașini cu vectori suport. Acestea reuşesc să realizeze operaţii tot mai complexe ce necesită parcurgeri multiple ale seturilor de date. Modelate astfel încât să ruleze cu volume mari de date având totodată un număr mare de variabile, aceste noi tehnici au avantajul unei mai bune rezistențe față de zgomotul din datele cu diverse anomalii, zgomot care este problematic pentru modele clasice.
În diverse domenii precum chimie, fizică, meteorologie, pentru a culege datele statistice utilizate în operaţiile de analiză şi predicţie a fenomenelor sau proceselor, este necesară măsurarea unor valori la anumite momente de timp. Astfel o serie de timp este definită ca fiind o secvență de valori a unor propriertăţi măsurate la anumite intervale timp, intervale ce de multe ori sunt egale, însă această condiţie nu este neapărat necesară pentru toate procesele (Anghelache & Manole, 2012). Crearea unor modele care să ofere soluții pentru o prognoză cât mai apropiată de realitate necesită de multe ori analiza unor cantități mari de date sau utilizarea unor algoritmi complecși, mari consumatori de timp. De aceea găsirea unor soluții de optimizare a extragerii datelor relevante, de optimizare a timpului de execuție sau de găsirea unor soluții optimale convenabile sunt deziderate ale multor cercetări actuale, inclusiv a tezei de față. În multe din aplicaţiile practice problemele de optimizare urmăresc optimizarea simultană a mai multor funcţii obiectiv. Dacă problemele mono-obiectiv pot admite o sigură soluţie optimală sau un număr limitat de soluţii de optim, problemele optimizărilor multiobiectiv cu obiective conflictuale duc de multe ori la obţinerea unui număr infinit de soluţii optimale. Frontul optimal este dat de reprezentarea acestor soluții în spațiul obiectiv. În lucrările de specialitate căutarea unor strategii pentru creșterea capacității de explorare sau a capacității de adaptare precum și simplificarea operațiilor implicate în procesele de căutare sunt teme de mare actualitate. Unele dintre aceste soluții se bazează pe utilizarea algoritmilor evolutivi. Aceștia simulează evoluția naturală bazată pe conceptele darwiniste. Utilizarea algoritmilor evolutivi în metode de optimizare multiobiectiv au avantajul că, pe de o parte lucrând cu mai mulți indivizi la fiecare epocă, pot permite găsirea unui set de soluții distribuite în apropierea frontului Pareto într-o singură parcurgere, iar pe de altă parte algoritmii evolutivi au avantajul unei capacități mari de explorare a spațiului de căutare, ceea ce poate ajuta la o ameliorare a convergenței premature a soluțiilor.

Cap. I Introducere
2
I.1 Obiective
Două obiective generale au fost urmărite în cadrul acestei teze: Dezvoltarea unor algoritmi care să accelereze căutarea unor soluții optime în
problemele de modelare sau în probleme de analiză a datelor bazate pe serii de timp fără a minimiza spațiul de căutare, fără a risca o convergență prematură sau de a converge către un optim local;
Investigarea aplicării acestor algoritmi în cazul unor probleme de prognoză a evoluției unor procese chimice pe de o parte și de selecție a trăsăturilor relevante pentru clasificarea semnalelor biologice pe de altă parte.
Pentru atingerea acestor deziderate s-au studiat în literatura de specialitate elemente specifice modelării, clasificării, aspecte privind propietățile fizico-chimice a unor hidrogeluri. Totodată pentru extragerea de trăsături a fost studiat un bogat material bibliografic în domeniul clasificării semnalelor de tip EEG (engl. ElectroEncephaloGram - electroencefalograma) folosite pentru a determina nivelului încărcării cognitive precum și despre activitatea electrodermală (engl. ElectroDermal Activity - EDA), variația frecvenței cardiace (engl. Heart Rate Variability - HRV) sau mișcarea pupilei utilizate pentru analiza și clasificarea emoţiilor.
Pentru atingerea acestor obiective în lucrarea de toctorat au fost tratate următoarele aspecte:
Prezentarea principalelor noțiuni teoretice şi a noutăţilor în domenul algoritmilor evolutivi;
Prezentarea principalelor noțiuni teoretice și a noutăților în domeniul algoritmilor de clasificare supervizată;
Prezentarea principalelor noțiuni teoretice legate de problema optimizării folosind metode evolutive;
Adaptarea unor mecanisme pentru îmbunătăţirea Algoritmului Imperialist Competitiv (engl. Imperialist Competitive Algorithm – ICA) prin:
Alegerea unei metode mai bune de împărţire a populaţiei iniţiale; Aplicarea unor operatori evolutivi cunoscuţi asupra imperialiştilor (indivizii cei mai adaptaţi dintr-o generaţie); Modificarea metodelor de competiţie şi asimilare pentru a creşte şansele de diversificare a populaţiei; Redefinirea şi reîmpărţirea coloniilor în mai multe imperii în situaţia în care toate coloniile converg prematur într-un singur imperiu;
Dezvoltarea unor metode de modelare pentru predicția comportamentului fizico-chimic al unor sisteme polimerice și compararea rezultatelor obținute cu datele experimentale:
Utilizarea unor reţele neuronale artificiale (engl. Artificial Neural Network – ANN) a căror antrenare se face cu ajutorul unor algoritmi evolutivi, cu scopul modelării unei metode de eliberare de medicament folosind un sistem de tip hidrogel bi-component; Modelarea unor rețele neuronale artificiale și a unor metode bazate pe regresie cu vectori suport pentru predicția comportamentului reologic al unor suspensii coloidale cu nanoparticule de argint; Studiul detecţiei automate a unor proprietăţi fizice ale matricelor polimerice de tip hidrogeluri folosind imagini de microscopie electronică de baleiaj (engl. Scanning Electron Microscopy - SEM);
Crearea sau modificarea unor algoritmi genetici de optimizare pentru selecţia atributelor utilizate în clasificarea nivelelor de încărcare cognitivă, utilizând semnale EEG

Cap. I Introducere
3
şi teste pentru încărcarea memoriei (engl. cognitive load): Analiza încărcării cognitive utilizând semnale EEG, teste aritmetice și paradigme de tip n-back, pentru diferiți clasificatori sau indicatori statistici; Studiul compatibilităţii unor dispozitive de achiziţie a semnalelor EEG; Studiul nivelelor de încărcare a memoriei de lucru (engl. working memory) pentru selecția atributelor;
Dezvoltarea unor metode de selecție atributelor EEG relevante utilizând seturi de date de mari dimensiuni şi cu un număr mare de atribute:
selecţia trăsăturilor utilizând un singur tip de clasificator; selecţia trăsăturilor prin comutare între diferite tipuri de clasificatori; selecția trăsăturilor folosind metode de optimizare configurate dinamic pentru seturi de date EEG cu extensie temporală;
Utilizarea unor semnale biologice precum EDA, HRV și ET (engl. Eye Tracking; [mișcarea pupilei]) pentru clasificarea emoțiilor folosind ca atribute entropiile acestor semnale.
I.2 Diseminarea rezultatelor. Contribuții și lucrări publicate
Rezultatele obținute în urma activității de cercetare au fost diseminate în 17 lucrări (14 publicate sau prezentate și 3 în curs de publicare) - din care 7 sunt indexate ISI Proceedings - înscrise în următoarele categorii:
• 2 lucrări publicate într-o revistă OpenAccess indexată de CEEOL, din care o lucrare este indexata şi ISI Proceedings. • 8 lucrări publicate în volumele unor conferințe internaționale, dintre care 8 indexate în IEEE Xplore, 6 fiind indexate ISI Proceedings; • 4 lucrări prezentate în cadrul unor conferințe naționale; • o lucrare în curs de publicare în volumului unei conferințe internaționale indexate ISI Proceedings; • o lucrare este în curs de elaborare în dorinţa de a fi trimisă spre publicare într-o revistă indexată ISI; • o altă lucrare este în curs de elaborare cu scopul de a fi publicată într-o revistă cotată CNCSIS B+. Direcțiile principale de cercetare prezentate în această teză vizează pe de o parte
crearea unor metode de modelare potrivite pentru predicția comportamentului fizico-chimic al unor sisteme chimice, iar pe de altă parte găsirea unor metode genetice de optimizare pentru selecția trăsăturilor relevante folosind clasificarea supervizată.
Modificarea, îmbunătățirea, descoperirea unor noi algoritmi evolutivi, căutarea mijloacelor de accelerare a modului în care se ajunge la soluția optimă fără a limita spațiul de explorare cu, eventual, reducerea timpului de atingere a acestui optim a dus la o creștere constantă a numărului de studii în acest domeniu. În lucrarea (Dumitriu, 2015) se analizează avantajele și dezavantajele utilizării algoritmilor genetici (engl. Genetic Algorithm – GA) și a unor variante ale algoritmului imperialist competitiv (engl. Imperialist Competitive Algorithm – ICA) cu scopul de a identifica o metodă eficientă de analiză a datelor de mari dimensiuni sau având multe atribute. Pentru identificarea unui algoritm eficient s-au comparat timpii de execuție, numărul de epoci necesare pentru a obține o valoare optimă dorită sau acurateţea obţinută într-un

Cap. I Introducere
4
anumit număr de epoci. O metodă de îmbunătăţire a acurateţei rezultatelor obţinută într-o perioadă de timp rezonabilă a fost propusă şi testată. De asemenea s-a testat utilizarea mai multor posibile optimizări ale operatorilor acestui algoritm. Astfel, combinarea a două variante distincte a acestui algoritm împreună cu anticiparea şi soluţionarea cazului de convergenţă prematură a condus către o tendinţă clară a algoritmului propus de a atinge mai rapid o valoare optimală decât alte implementări, această tendinţă fiind vizibilă în toate testele efectuate. Rezultate obţinute au fost prezentate în (Dumitriu, 2015).
Prin faptul că rețelele neuronale artificiale (RNA) sunt foarte robuste prin prisma lucrului cu date afectate de zgomot sau date incomplete având și abilitatea de a generaliza, acestea s-au dovedit a fi foarte utile pentru a prognoza rezultatele posibile ale eliberărilor de medicamente din diverse sisteme chimice. Ţinând cont că de multe ori analizele chimice durează şi că substaţele implicate în procesele de cercetare sunt de multe ori foarte scumpe, o modelare a comportamentului de eliberare a medicamentelor poate fi utilă atât din considerente de eficienţă şi cost cât şi pentru a sugera cercetătorului tendinţele posibile ale respectivului produs sau proces. Astfel, investigațiile efectuate asupra eliberării in vitro a medicamentelor au arătat că hidrogelurile pe bază de poli (N-izopropil acrilamida)/alginat de sodiu (PNIPAAm/ALG) prezintă o comportare de eliberare prelungită a medicamentului, influențată de compoziția lor: pe măsură ce cantitatea de alginat (plizaharidă cu un caracter hidrofil) din compoziția hidrogelului este mai mare, viteza și procentul de eliberare a medicamentului încărcat scade. Rezultatele simulării folosind reţele neuronale artificiale a căror antrenare a fost făcută folosind algoritmul evolutiv propus în (Dumitriu, 2015) sunt în concordanță cu datele experimentale observate, demonstrând potențialul rețelelor neuronale artificiale pentru contribui la dezvoltarea formulelor de dozare cu eliberare prelungită. Detaliile acestor studii sunt ilustrate în (Dumitriu, Dumitriu, Manta, 2016).
Pentru a estima eficiența utilizării amestecurilor pe bază de alginat de sodiu și lignosulfonat de amoniu ca mediu de dispersie pentru formarea și stabilizarea nanoparticulele de argint, s-au folosit ca instrumente de modelare rețele neurale artificiale și maşini cu vector suport pentru regresie (engl. Support Vector Regression - SVR). Comportamentul reologic al suspensiilor coloidale cu nanoparticule de argint obținute in situ a fost investigat prin măsurători realizate în rotație, folosind geometria con-placă, în funcție de compoziția dispersiei. Crearea unui model pentru a prognoza acest comportament a condus la obţinerea unor rezultate a căror acurateţe este foarte bună. Analiza comparativă a datelor experimentale cu rezultatele obținute prin simulare a arătat o precizie ridicată a estimării atât prin utilizarea rețelelelor neuronale artificiale, cât și folosind SVR, în special pentru dependența tensiune de forfecare – viteză de forfecare. În intervalul vitezelor de forfecare joase, în general modelul SVR a prezentat o capacitate de estimare mai promițătoare pentru curba de curgere. Estimarea vâscozității este abordată într-un număr mic de lucrări ştiinţifice din literatura de specialitate. Acest studiu arată că influența compoziției suspensiei coloidale asupra variației vâscozității în funcție de viteza de forfecare are un efect semnificativ asupra capacității de învățare a modelelor RNA și SVR, ceea ce a condus la o precizie ușor mai scăzută a valorilor estimate. Aceste rezultate au fost publicate în (Dumitriu, Dumitriu, Cîmpanu, 2017a)
În cadrul sistemelor de interfeţe creier-calculator (engl. Brain-Computer Interface – BCI), clasificarea supervizată a semnalelor EEG este o direcție intens studiată. Performanța procesului clasic de învățare, e-learning sau în mediu virtual, este corelată cu încărcarea cognitivă şi activitatea memoriei de lucru. Pentru a clasifica activitatea memoriei de lucru sau nivelul de încărcare cognitivă a unei persoane au fost utilizate diverse tehnici precum maşini cu vector suport (engl. Support Vector Machine – SVM) sau păduri de arbori (engl. Random Forest - RF) de decizie.
Capacitatea de a reține informații sau fragmente de informaţii în timpul rezolvării unei probleme se face cu ajutorul memorie pe termen scurt. Utilizarea acestei memorii de lucru duce

Cap. I Introducere
5
la creşterea activităţii creierului în regiunile frontale și prefrontale. De-a lungul cercetărilor legate de activitatea creierului uman s-a observat că lobilor frontali le sunt asociate în general funcții cognitive de nivel superior precum gândirea, analiza informaţiilor sau luarea unor decizii. Studiile au arătat că activitatea din cortexul prefrontal poate fi asociată cu unele funcţii de decizie de nivel înalt. Pentru a evalua clasificarea nivelelor de încărcare cognitivă și ale memoriei de lucru (Ungureanu, Cîmpanu, Dumitriu, Manta, 2017) au studiat diverse abordări pe parcursul unei activități de învățare. Datele achiziţionate au fost preprocesate eliminându-se artefacte precum clipitul sau mişcarea mușchilor, apoi au fost filtrate pentru a extrage formele de undă specifice semnalelor EEG (Delta, Theta, Alpha, Beta și Gamma) în vederea analizării şi clasificării acestora. Fiecărui tip de undă i s-a calculat anvelopa semnalului şi funcţia spectrală atât pentru starea de relaxare cât şi pentru diferite trepte de încărcare cognitivă. În acest scop subiecţii au efectuat teste de tip n-back şi calcule aritmetice simple. Prezentarea rezultatelor obţinute s-a făcut în (Ungureanu, Cîmpanu, Dumitriu, Manta, 2017).
Astăzi cercetarea în domeniul sitemelor BCI creşte exploziv atât prin dezoltarea unor noi echipamente fizice cât şi prin metodele moderne de achiziţie şi prelucrare a datelor, părăsind dispozitivele invazive şi axându-se din ce în ce mai mult pe cele mult mai simple, neinvazive eventual de tip fără fir (engl. wierless). În încercarea de a identifica un anumit nivel de încărcare cognitivă folosind semnalele EEG, au fost utilizate două metode de clasificare pentru a face diferenţa între nivelele de încărcare a memoriei de scurtă durată. În urma unor experimente în care participanţii la teste au efectuat teste de tip n-back s-au achiziţionat date folosind două căşti diferite: una profesională de tip Brain Product ce foloseşte electrozi umezi aşezaţi conform Sistemului Internaţional 10-20, şi un echipament cu un cost scăzut dar având conexiune wierless, Emotiv Epoc+. Semnalele EEG preluate au fost preprocesate, cu ajutorul unor filtre au fost extrase datele de interes, fiind apoi clasificate folosind o serie de algoritmi recomandaţi pentru semnalele nestaţionare. Selectarea acelor atribute potrivite pentru identificarea cât mai exactă a nivelului de încărcare rămâne însă o problemă dificilă. Experimentele efectuate corelează clasificarea tiparelor EEG pentru un anumit nivel de încărcare a memoriei, între cele două dispozitive. Rezultatele obţinute scot în evidenţă rolul clasificatorilor RF şi SVM atunci când sunt utilizaţi pentru mai multe clase, cu scopul selecţiei atributelor necesare unei clasificări cât mai bune ale semnalelor EEG când se aplică paradigma n-back. În acelaşi timp se pot observa avantajele dar şi unele dezavantaje ale echipamentelor wierless. Deşi atât RF cât și SVM obțin performanțe foarte bune în aplicați pentru clasificarea de tipare EEG, totuşi nivelul de încărcare a memoriei de scurtă durată poate fi identificat cu o acurateţe mare, utilizând doar semnalele culese mai ales de electrozii din regiunea frontală, de catre RF. Ambele dispozitive au avut un comportament asemănător în această privinţă. Rezultatele acestor cercetări au fost publicate în (Cîmpanu, Ungureanu, Manta, Dumitriu, 2017a)
Întrucât de cele mai multe ori procedeele instrucţionale au la bază teorii legate de încărcarea cognitivă, clasificarea supervizată a semnalelor EEG poate ajuta la crearea unor proceduri educative. Odată cu evoluţia umană şi percepția asupra cunoașterii a evoluat. Aceasta duce la ideea că rolul încărcării cognitive în dezvoltarea cunoaşterii ar putea fi studiat şi cu ajutorul semnalelor EEG. Totuşi trebuie ţinut seama şi de faptul că sistemul cognitiv uman nu evoluează în mod expres pentru a învăța tematici care să necesite cunoștințe specifice unui anumit domeniului. Deoarece memoria de lucru se activează în procesul de memorare a cunoştinţelor specifice, chiar dacă în plan secundar, încărcarea cognitivă poate fi utilizată pentru a calibra încărcarea memoriei de lucru pe parcursul procesului educațional. În (Cîmpanu, Dumitriu, Ungureanu, 2018a) se analizează diferite modalități de clasificare și identificare a nivelelor de încărcare cognitivă pe parcursul activității de învățare. Clasificarea bazată pe cei mai apropiați k vecini (engl. k Nearest Neighbors - kNN), pe clasificatorul Bayesian naiv (engl. Naive Bayes), pe RF, pe SVM sau pe mecanismele AdaBoost (engl. ADAptive BOOSTing), au fost utilizate

Cap. I Introducere
6
pentru clasificarea semnalelor EEG. Rezultatele sunt ilustrate în (Cîmpanu, Dumitriu, Ungureanu, 2018a).
O direcţie actuală în estimarea stărilor afective are la bază analiza semnalelor fiziologice umane precum activitatea electrodermală (EDA), variaţia ritmului cardiac (HRV) sau urmărirea acţiunilor pupilei (ET). Detecţia acestora poate fi utilă în estimarea stării de oboseală sau anxietate ce pot avea repercursiuni nefaste în diverse meserii precum cea de şofer, pilot, medic etc. Identificarea emoțiilor are avantajul că acestea pot fi interceptate pe baza unor date nealterate precum indicatori faciali sau vocali, însă aceştia pot fi falsificați, mimaţi sau trucaţi uneori cu ușurință.
Pentru a determina starea afectivă a unei persoane, (Dumitriu, Ungureanu, Cîmpanu, Manta, 2018) utilizează o serie de parametri fiziologici. Folosind senzori de monitorizare a activității electrodermale, a privirii sau a pulsului, subiecţii sunt testaţi folosind o serie de experimente bazate pe stimuli vizuali. Datele achiziţionate sunt prelucrate şi analizate comparând rezultatul unor algoritmi de învăţare cunoscuţi precum: KNN, AdaBoost, SVM sau efectuând o analiză liniară discriminativă (engl. Linear Discriminant Analysis - LDA), considerând entropiile semnalelor ca fiind atribute principale. Această metodă aduce o idee nouă de analiză în domeniul estimării stărilor afective. Deşi promiţătoare, aceste metode trebuie investigate eventual şi împreună cu date EEG în dorinţa de a obţine o acurateţe ridicată. Rezultatele sunt evidenţiate în (Dumitriu, Ungureanu, Cîmpanu, Manta, 2018).
Selecţia şi extragerea trăsăturilor în cazul semnalelor EEG sunt intens studiate în ultimii ani. Selecția trăsăturilor presupune procesarea unui număr foarte mare de date descrise prin foarte multe atribute. Metodele de selecţie de trăsături propuse evaluează calitatea soluţiilor prin verificarea lor pentru fiecare clasificator utilizat. Definirea funcţiilor obiectiv în cazul optimizării multiobiectiv este strâns legată de clasificatorul folosit, ceea ce face ca selecţia de trăsături să fie afectată de modelul clasificatorului utilizat. (Cîmpanu, Ferariu, Ungureanu, Dumitriu, 2017b) propune o nouă metodă de selecţie a trăsăturilor bazată pe algoritmii genetici în care metoda de optimizare asigură o evaluare mult mai robustă a seturilor de atribute aflate în competiţie prin utilizarea unor mecanisme de comutare între clasificatori. Aceasta este astfel creată încât creşterea acurateței evaluării calităţii soluţiilor se face fără o creştere semnificativă a timpului de execuţie. Pentru exemplificare s-au folosit semnalele EEG asupra cărora au fost utilizaţi clasificatori de tip RF şi SVM ce au evaluat încărcarea memoriei în operaţii de tip n-back. De asemenea etapa de preprocesare a semnalelor EEG, a fost analizată şi discutată. Proprietăţile noii metode propuse sunt ilustrate experimental în schemele de asociere a rangurilor Pareto în sensul optimizării multiobiectiv sugerate în (Cîmpanu, Ferariu, Ungureanu, Dumitriu, 2017b).
Majoritatea studiilor actuale privind selecţia sau extragerea trăsăturilor se bazează pe metode ale învățării automate. O abordare ce foloseşte metode evolutive de optimizare multiobiectiv pentru procedura de extragere de trăsături cu scopul clasificării nivelelor de încărcare a memoriei este studiată în (Cîmpanu, Ferariu, Dumitriu, Ungureanu, 2017c). Analiza trăsăturilor candidat privite din punctul de vedere al acurateței clasificării și dezvoltarea unui algoritm genetic de optimizare multiobiectiv ce permite selecția unei soluții finale preferate este principala contribuţie. Pentru clasificarea vectorilor de trăsături s-au folosint algoritmii RF şi SVM. Validarea rezultatelor s-a făcut folosind două seturi de date EEG, optimizarea selecţiei de trăsături având rolul de a distinge între diversele trepte de încărcare a memoriei. Performanțele metodei se pot observa în (Cîmpanu, Ferariu, Dumitriu, Ungureanu, 2017c).
(Ferariu, Cîmpanu, Dumitriu, Ungureanu, 2018) folosesc un efect inerţial în selecţia de atribute pentru a minimiza eroarea de clasificare şi numărul de trăsături selectate. Astfel, selecţia are loc cu ajutorul unei metode genetice de optimizare multiobiectiv. Pentru aceasta setul de atribute disponibil la un anumit moment este extins cu seturile de atribute de la momente de timp anterioare. Datele folosite sunt semnale EEG achiziţionate în timp ce subiecţii efectuau o

Cap. I Introducere
7
serie de operaţii matematice a căror complexitate creşte gradual. Pentru a încuraja clasificarea pe ranguri a soluţiilor sunt propuse două metode pentru procedura de optimizare mono-obiectiv. Astfel, numărul arborilor implicaţi în algoritmul de clasificare RF creşte gradual cu scopul de a minimiza efortul computaţional pentru evaluarea erorii de clasificare. În acelaşi timp, definirea unei funcţii obiectiv dinamice ce descrie numărul de atribute selectate cu rolul de a minimiza această eroare este utilizată. Rezultatele aplicării acestor metode au fost prezentate în (Ferariu, Cîmpanu, Dumitriu, Ungureanu, 2018).
I.3 Structura tezei
În cele şase capitole ale acestei teze sunt centralizate rezultatele cercetărilor publicate în decursul perioadei doctorale în articolele prezentate mai sus.
Primul capitol porneşte de la motivația alegerii temei după care sunt descrise pe scurt inovaţiile şi temele ce au făcut obiectul cercetării. Publicaţiile în care s-a făcut diseminarea rezultatelor se regăsesc în al doilea subcapitol, urmat de prezentarea structurii tezei.
În capitolul doi sunt explicate fundamentele teoretice ale algoritmilor evolutivi ce susţin aplicaţiile create. Bazele biologice, terminologia şi principiile fundamentale ale calculului evolutiv sunt expuse în primul subcapitol. În subcapitolul doi este discutată problematica optimizării obţinerii soluţiilor unor probleme complexe. Terminologia, elementele şi operatorii principali ai algoritmilor evolutivi sunt detaliaţi în subcapitolul al treilea, împreună cu unele considerente legate de convergenţa acestor algoritmi. Această secţiune este urmată de o prezentare a specificului algoritimilor genetici. În ultima secţiune a capitolului sunt prezentate detaliile unui algoritm evolutiv ce va constitui un element important al modelării unor procese chimice. Acest algoritm este utilizat ca bază de referinţă, împreună cu algoritmii genetici în problema determinării minimului unor funcţii.
Capitolul trei introduce noţiunile de modelare şi clasificare ca şi concepte ce susţin partea de implementare a aplicaţiilor. Astfel, modelul biologic şi modelul neuronului artificial sunt dezbătute succint în primele două secţiuni ale subcapitolului. Funcţiile de activare ale acestuia din urmă sunt prezentate şi explicate în contextul utilizării lor. Structura unei reţele neuronale simple şi explicarea mecanismelor de antrenare sunt de asemenea tratate. Partea a doua a acestui capitol debutează cu definirea clasificării și a terminologiei asociate, explică metodele de grupare supervizată, clasificarea acestora precum şi indicatorii de performanţă recunoscuţi pentru a măsura valoarea unui clasificator. O prezentare a celor mai cunoscute metode de clasificare este evidențiată, iar clasificatorilor kNN, SVM, RF, AdaBoost, utilizaţi în aplicaţiile descrise în capitolul cinci li se acordă o atenţie deosebită.
În capitolul patru sunt prezentate principalele rezultate legate de aplicarea unor metode ale inteligenţei artificiale, mai ales a algoritmilor evolutivi în modelarea unor procese chimice bazate pe serii de timp. În primul subcapitol sunt evaluate unele metode de îmbunătăţire a operatorilor algoritmului competitiv imperialist (ICA), totodată cu prezentarea unor modificări ale utilzării acestora, astfel încât algoritmul să îşi sporească puterea de explorare a spaţiului soluţiilor potenţiale fără însă a creşte efortul computaţional. Optimizarea, pe de o parte a acestor operatori şi asigurarea diversificării spaţiului de explorare pe de altă parte, sunt tratate în raport cu minimizarea unor funcţii de referinţă recunoscute ca atare în literatura de specialitate. Rezultatele experimentale ale simulărilor arată tendinţa generală a acestor metode de a atinge mai rapid valoarea optimală decât în cazurile altor algoritmi evolutivi cunoscuţi. Descrierea procedurilor experimentale alături de rezultatele obţinute pentru multiple clase de teste este de asemenea prezentată în acest capitol. Aceste optimizări sunt apoi utilizate pentru antrenarea

Cap. I Introducere
8
unei reţele neuronale ce va trebui să modeleze comportamentul unor hidrogeluri în eliberarea de medicamente. Prognozarea valorilor acestui proces este utilă pentru dozarea cât mai exactă a compoziţiilor chimice necesare procedurilor experimentale. Procedurile experimentale sunt de asemenea descrise. Rezultatele obţinute prin simularea comportamentului folosind o reţea neuronală antrenată cu algoritmul evolutiv îmbunătăţit descris mai sus sunt comparate cu cele observate în urma experimentelor de laborator, demonstrând atât valoarea modelării cât şi utilizării ICA în faza de antrenare. De asemenea comportamentul reologic a unor suspensii coloidale de nanoparticule de argint a fost studiat atât prin modelarea cu reţele neuronale cât şi utilizând maşini cu vectori suport pentru regresie. Atât procedurile chimice cât şi metodele de modelare şi simulare pentru predicţia comportamentului nanoparticuleor sunt descrise în această secţiune. Rezultatele experimentale sunt prezentate la final. Capitolul se încheie cu unele concluzii asupra utilizării modelelor prezentate.
Capitolul cinci aduce în discuţie metodele de măsurare a încărcării cognitive utilizând ca sursă de investigare semnalele EEG. Pentru a putea estima încărcarea cognitivă o serie de teste de tip n-back au fost utilizate de un număr de voluntari. Sunt explicate în primul subcapitol metodele de achiziţie de date, modalităţile de analiză şi clasificare a acestora, precum şi indicatorii utilizaţi în măsurarea încărcarii cognitive. Totodată s-a analizat şi compatibilitatea utilizării unor dispozitive de achiziţie fără fir dar mai ieftine în raport cu cele profesionale. Rezultatele experimentelor sunt prezentate şi explicate în finalul subcapitolului. Pentru seturile de date EEG de dimensiuni mari, este prezentată o metodă de selecţie a atributelor ce foloseşte extensii temporale. De asemenea este analizată selecția de trăsături folosind o metodă de comutare între clasificatori cu scopul de a minimiza impactul acestora asupra procesului de clasificare. Achiziţia şi preprocesarea sunt de asemenea descrise, alături de rezultatele experimentale. Pe de altă parte, analiza emoţiilor este văzută tot prin intermediul unor date fiziologice precum activitatea electrodermală, mişcarea pupilei ochilor sau ritmul cardiac. Dispozitivele cu ajutorul cărora aceste semnale au fost achiziţionate sunt de asemenea descrise. Tratarea multimodală a acestor date este rară în literatură. În acest capitol este prezentată și metoda utilizată pentru sincronizarea datelor. Analiza şi clasificarea datelor a avut ca scop evaluarea stării emoţionale a subiecţilor, fără însă a putea măsura şi intensitatea acestora. Metodologia şi rezultatele obținute sunt de asemenea prezentate. Ca o măsură aparte, investigarea utilizării valorilor unor entropii ca atribute ale seturilor de date utilizate pentru clasificare a avut rezultate încurajatoare.
Concluziile investigaţiilor şi rezultatelor obținute pentru metodele utilizate sunt prezentate capitolului șase. Lista publicațiilor în care au fost diseminate rezultatele și lista referințelor bibliografice ordonată alfabetic încheie această lucrare.

9
Capitolul II Metode evolutive utilizate în modelare şi optimizare
Charles Darwin în lucrarea sa “Originea speciilor”, a încercat să demonstreze că trăsăturile ereditare au decis schimbările apărute de-a lungul timpului asupra speciilor și că cele mai puternice trăsături sunt transmise urmașilor (Peretó & colab., 2009).
Pentru simularea unor sisteme biologice la Universitatea din Michigan au apărut primii algoritmi genetici. Aceștia utilizează câteva principii fundamentale ale geneticii în încercarea de a crea algoritmi de căutare utilizați în diverse direcții de cercetare precum optimizarea.
Conform (Engelbrecht, 2007), evoluția poate fi privită ca fiind un proces de optimizare ce are rolul de a crește șansa unui organism de a supraviețui într-un mediu competitiv și dinamic. Cu ajutorul metodelor calculului evolutiv pot fi rezolvate o serie de probleme precum cele de optimizare, modelare sau simulare.
În problemele de optimizare modelul împreună cu datele de ieşire dorite sunt cunoscute și se înceracă determinarea datelor de intrare corespunzătoare. Problemele de modelare presupun cunoașterea datelor de intrare şi rezultatele acestora, în timp ce modelul trebuie determinat astfel încât, pentru fiecare din datele apriori cunoscute să poată fi calculat un rezultatul corect. Astfel de problemele sunt utile în cazurile în care sunt disponibile date de dimensiuni mari și se dorește identificarea unui model care să explice conexiunile dintre acestea și rezultate. În problemele de simulare sunt cunoscute modelul şi o serie de date de intrare şi cerinţa este de a determina datele de ieşire corecte, corespunzătoare intrărilor date.
Rezolvarea unor probleme poate fi privită ca o încercare de explorare a spaţiului soluţiilor potenţiale. Cum, în general sunt căutate cele mai bune soluţii, procesul de căutare poate fi privit ca fiind o etapă de optimizare (Leon, 2006).
Cele mai simple tehnici de optimizare sunt cele enumerative. În cadrul acestora este evaluată fiecare posibilă soluţie în spaţiul de căutare care are un număr finit de soluţii admisibile. Metodele deterministe explorează spațiul caracteristic unei probleme date, de aceea sunt potrivite în cazul spațiilor de căutare cu dimensiune redusă. Dacă însă vorbim de un spațiu amplu de căutare metodele stocastice sunt preferate. Intre acestea metodele calculului evolutiv sunt unele dintre soluţiile des utilizate având ca model fenomenele naturale ale moştenirii genetice şi a luptei pentru supravieţuire. Printre cele mai utilizate metode din categoria calculului evolutiv amintim strategiile evolutive, programarea evolutivă, programarea genetică și algoritmii genetici. Totodată, proprietăţi diverse ale acestor paradigme au fost utilizate pentru a crea alte sisteme hibride cu scopul de a îmbunătăţi metodele de optimizare.
În (Engelbrecht, 2007) un algoritm evolutiv este definit ca fiind procesul de căutare stohastică a soluției optimale pentru o problemă dată.
În general, în cazul algoritmilor bazați pe calcul evolutiv, pentru găsirea populației finale (numită soluție), se pornește cu o populație de soluții potențiale, care evoluează în așa fel încât indivizii din noua generație sunt mai adaptați la mediu decât indivizii din care au fost creați. Direcționarea căutării se face prin transformări asupra populației similare cu procesele naturale de selecție, recombinare și mutație. În același timp asupra mulțimii indivizilor se aplică un operator de selecție pentru a putea alege părinții pentru generația viitoare. Aceast operator funcționează conform principiul darwinist al teorie evoluției de supraviețuiește cel mai bine adaptat. Într-o generație, în pasul de selecție se vor regăsi paradigmele supraviețuirii celui mai bine adaptat individ, conform unor legi aplicate în etapa de evaluare. Numărul de epoci depinde de condiția de oprire.

Cap. II Metode evolutive utilizate în modelare şi optimizare
10
Așa cum reiese din afirmațiile de mai sus, conceptul de algoritm evolutiv presupune definirea unor operatori și ai unor etape precum: definirea modulului de iniţializare (modalitatea de determinare a populaţiei iniţiale), reprezentarea (definirea membrilor populaţiei), funcţia de evaluare (de tip fitness), populaţia, mecanismul de selectare a părinţilor (indivizii care interschimbă material genetic), operatorii de variaţie (recombinarea şi mutaţia), mecanismul de selectare a membrilor generaţiei următoare (actualizarea populaţiei), definirea condiţiei terminale.
Principalul avantaj al algoritmilor evolutivi în general și al celor genetici în mod particular, este determinat de faptul că solicită puține cunoștințe despre problema de rezolvat, fiind suficientă valoarea funcției obiectiv. Întrucât algoritmii genetici pot fi utilizați la optimizarea unor funcții nederivabile, mai mult condiția de continuitate a funcției obiectiv nu este necesară, aceștia au astfel un grad mare de universalitate (Ferariu, 2013). Pe de altă parte, algoritmii genetici sunt mari consumatori de timp. Perfomanțele acestora depind de valorile unor parametrii precum probabilitatea mutației și a încrucișării, dimensiunea populației, numărul de generații, rata și metoda de selecție pentru reproducere, etc.
Imperialist Competitive Algorithm (ICA)
În cazul obţinerii unor modele pentru prognoza unor evenimente sau a unor procese a căror antrenare se face pe o mulţime de date având un cardinal mare, timpul de antrenare a unor reţele neuronale, sau a altor algoritmi sau tehnici specifice modelării poate fi mult prea mare. Aceast neajuns face ca în practică implementarea sau utilizarea acestora pentru anumite domenii să fie nerealistă. Algoritmul Imperialist Competitiv a atras o atenţie deosebită autorului, datorită vitezei de convergenţă superioară faţă de alţi algoritmi, fără a micşora spaţiul de căutare şi fără a altera major diversitatea populaţiei. Acest algoritm a fost propus de Atashpaz-Gargari și Lucas ca un model matematic pentru evoluția socială umană.
În varianta inițială a Algoritmului Imperialist Competitiv, propusă de Atashpaz-Gargari, populația inițială, în forma cromozomială, numită țară (eng. „country”) este generată aleator într-o zonă din spațiu de definiție (numere aleatoare din domeniul de definiție al funcției obiectiv). Unele dintre cele mai bune țări sunt selectate pentru a fi imperialiști, iar restul sunt colonii ale fiecărui imperiu al cărui lider este un imperialist. Valoarea unui imperiu este apreciată pe baza unei funcții numite puterea imperiului.
Algoritmul II.3 Algoritmul Imperialist Competitiv (ICA)
(Atashpaz-Gargari & Lucas, 2007)
Pasul 1: Iniţializarea populaţiei, Evaluarea imperialiştilor şi crearea imperiilor
Repetă
Pentru fiecare imperiu i
Pasul 2: Aplicarea operatorul de Asimilare fiecărei colonii.
Pasul 3: Reevaluarea costurilor fiecărei colonii şi a imperiilor.
Recalcularea puterii imperiilor.
Pasul 4: Actualizarea imperialiştilor.
Sfârşit pentru
Pasul 5: Recalcularea costul fiecărui imperiu. Pasul 6: Aplicarea operatorului de Competiţie între imperii. Pînă când Condiţiile de stop sunt îndeplinite. În Pasul 2, scopul operatorului de Asimilare este ca toate coloniile unui imperiu să încerce
să se apropie de imperialistul lor fie printr-o apropiere pe aceeaşi direcţie de deplasare, fie cu o
variaţie sub un anumit unghi ( ) ales sau generat aleatoriu. Dacă kc este un imperialist ( impNk )

Cap. II Metode evolutive utilizate în modelare şi optimizare
11
și ic este una dintre coloniile acestuia ( Ni ), operația de asimilare, care deplasează colonia spre
imperialist, poate fi descrisă ca (Lin & colab., 2012):
)( ikii cccc , (II.1)
unde valoarea recomandată pentru este 2 în (Atashpaz-Gargari & Lucas,2007) și 4 în (Lin &
colab., 2012), iar este o valoare aleatoare între 0 și 1 În pasul 3, sunt recalculate costul fiecărei colonii precum şi costul și puterea fiecărui
imperiu. Dacă una dintre colonii are un cost mai bun decât costul imperialistului, atunci poziția sa este schimbată cu cea a imperialistului.
În etapa de Competiție, se ia cea mai slabă colonie din cel mai slab imperiu și se redistribuie imperiului cu o putere mai convenabilă. Pentru aceasta se poate alege aleatoriu un imperiu sau se poate calcula o cea mai mare probabilitate ca această colonie să aparţină unui alt imperiu. După un anumit număr de iterații, cel mai slab imperiu rămâne fără colonii și este asimilat într-un imperiu puternic. Pașii 2 - 6 se repetă până când se realizează condițiile de oprire.
Mai târziu a fost propus un nou operator numit Revoluție (Lin & colab., 2012; Lin & colab., 2013) care schimbă aleatoriu caracteristicile unor colonii pentru a asigura diversitatea populaţiei.
Creşterea gradului de explorare a ICA
Întrucât acest algoritm are uneori tendinţa de a se bloca într-un optim local prin păstrarea elitistă doar a celor mai buni indivizi, încă din primele aplicaţii ale algoritmului ICA în diverse domenii teoretice sau practice, cercetătorii au încercat să îmbunătățească pasul de asimilare. Aceste îmbunătăţiri au avut mai ales rolul de a introduce o diversificare a indivizilor, fără a creşte semnificativ impactul general asupra vitezei de convergenţă a algoritmului. Între aceste încercări, în (Zhang, 2012) şi în (Duan & colab., 2010) este utilizată teoria haosului pentru a crește capacitatea de explorare a ICA și de a crea indivizi noi. Algoritmul creat astfel a fost intitulat Chaotic Imperialist Competitive Algorithm (CICA) şi are ca efect o mai buna alegere a modificărilor alelelor decât variaţiile aleatoare.
În (Lin & colab., 2012) a fost remarcat impactul redus al competiției, întrucât în acest pas se elimină cea mai slabă colonie din cel mai slab imperiu și este mutată într-un imperiu mai puternic. Pentru acest ultim imperiu, noua colonie nu aduce un avantaj consistent: costul noi colonii este deja scăzut, iar contribuția sa la puterea întregului imperiu este neglijabilă. Pentru a compensa acest lucru, s-a căutat o metodă de îmbunătăţire a indivizilor prin aplicarea unui operator asupra imperialiştilor, ca fiind cromozomii cei mai promiţători în a genera indivizi mai adaptabili. Astfel, pentru a spori eficiența concurenței și a crește șansele de a crea noi indivizi mai bine adaptaţi, a fost introdus un nou operator denumit Interacțiune, operator ce se aplică doar asupra imperialiștilor.
Două versiuni ale ICA au fost create pentru a pune în aplicare etapa de interacțiune: crearea unui imperialist artificial (ICAAI) şi încrucişarea imperialiştilor (ICACI) asemănătoare cu operatorul de încrucişare utilizaţi în algoritmii genetici.
Această operațiune crește șansele de a găsi un nou individ mai bun (adică mai bine adaptat) și crește posibilitatea de a evita căderea într-o valoare optimă locală.
În toată literatura studiată se observă faptul că utilizarea acestui algoritm aduce avantajele unei convergenţe mai rapide către o valoare optimală. De asemenea, în majoritatea studiilor datele utilizate pentru codificarea cromozomială sunt de tip real, deoarece acest algoritm pe pretează preferenţial pentru acest tip de date.

12
Capitolul III Modelare și clasificarea datelor
III.1 Modelare. Definiţii şi concepte Conform (MDA,2010) “studierea a unui obiect sau fenomen inaccesibil cercetării directe
cu ajutorul unui obiect sau fenomen direct cognoscibil” poartă numele de modelare. Astfel un proces, eveniment, obiect, fenomen poate fi studiat cu scopul de a înțelege relațiile dintre componenetele sau comoprtamentul respectivului fenomen. Abstractizarea și crearea unui model poate ajuta la analiza și prezicerea comportării viitoare a respectivului fenomen. Procesul prin care se construiește modelul asociat evenimentului studiat poartă numele de modelare.
Modelarea aproximează sistemul studiat prin surprinderea şi înglobarea în model a celor mai importante trăsături ale acestuia (Cucu, 2014). O serie de algoritmi sau metode pot fi utizaţi în modelare. Dintre acestea amintim algoritmii evolutivi, reţelele neuronale, arborii de decizie, maşini cu suport vectorial.
Primii pași în studiul reţelelor neuronale au fost făcuți de către Hermann von Helmholz, Ernst Mach și Ivan Pavlov care au emis teorii asupra procesului de învățare. În 1943 Warren McCulloch și Walter Pitts au pus în evidență primul model formal al neuronului, evidențiind capacitatea de calcul a acestuia și posibilitatea de implementare cu ajutorul circuitelor electronice. Pe la sfârșitul anilor 1940, Hebb, având la bază teoriile lui Pavlov, a enunțat principiul adaptării permeabilității sinaptice conform căruia de fiecare dată când o conexiune sinaptică este folosită, permeabilitatea ei crește (Hebb, 1949). Acest principiu stă la baza procesului de învățare prin modificarea ponderilor sinaptice.
Frank Rosenblatt realizează primul perceptron, utilizat în recunoașterea caracterelor, iar în 1958 propune o reţea bazată pe perceptroni. Tot în anii 1950 Bernard Windrow și Ted Hoff dezvoltă algoritmi de învățare pentru rețele neurale liniare cu un singur nivel de unități funcționale. Algoritmii lor sunt bazați pe minimizarea erorii pe setul de date de antrenare (Werbos, 1990). În 1969 Marvin Minsky și Seymor Papert publică lucrarea "Perceptrons" în care aceştia indică limitările perceptronilor (Minsky & Papert, 1969). Rosenblatt enunță și demonstrează teorema de convergență a perceptronului. În același timp, perceptronul este considerat ca fiind unitatea elementară de prelucrare pentru Rețelele Neuronale Artificiale (RNA).
Astfel, perceptronul simplu este cea mai simplă configuraţie posibilă a unei reţele neuronale care realizează, pe baza unui algoritm specific, o clasificare a formelor de intrare (vectori cheie, seturi de date de intrare), respectiv o împărţire a acestora în clase.
Cum perceptronul este inspirat din modelul biologic al neuronului, între acestea există o serie de similitudini. Astfel, sinapsele pe care un neuron le face prin dendrite cu alți neuroni sunt numite intrări. Corpul neuronului este pentru modelul artificial un sumator și o funcție de activare (numită și funcție de transfer), axonul în perceptron reprezintă ieșirea. Pentru a reprezenta caracteristici neliniare simple s-a introdus noțiunea de bias.
O rețea neuronală artificială este o structură de procesare paralelă și distribuită a informației. Inspirate din punct de vedere structural şi funcţional de creierul fiinţelor vii, RNA sunt un model matematic simplificat al sistemului nervos central, fiind capabile să asimileze noi tipare, să creeze noi asocieri și să se adapteze mediu.
În definirea unei rețele neuronale arhitectura, modul de funcționare și adaptarea sunt caracteristicile principale. Astfel, arhitectura reprezintă modul de amplasare și interconectare al
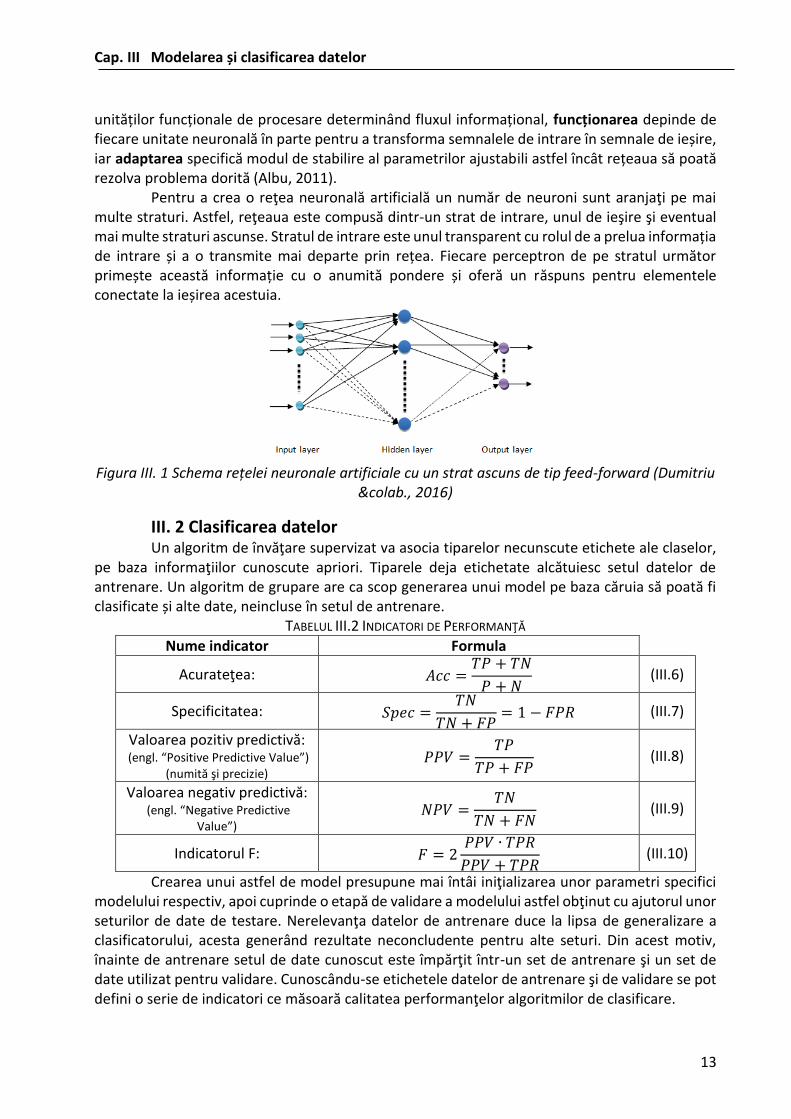
Cap. III Modelarea și clasificarea datelor
13
unităților funcționale de procesare determinând fluxul informațional, funcționarea depinde de fiecare unitate neuronală în parte pentru a transforma semnalele de intrare în semnale de ieșire, iar adaptarea specifică modul de stabilire al parametrilor ajustabili astfel încât rețeaua să poată rezolva problema dorită (Albu, 2011).
Pentru a crea o reţea neuronală artificială un număr de neuroni sunt aranjaţi pe mai multe straturi. Astfel, reţeaua este compusă dintr-un strat de intrare, unul de ieşire şi eventual mai multe straturi ascunse. Stratul de intrare este unul transparent cu rolul de a prelua informația de intrare și a o transmite mai departe prin rețea. Fiecare perceptron de pe stratul următor primește această informație cu o anumită pondere și oferă un răspuns pentru elementele conectate la ieșirea acestuia.
Figura III. 1 Schema rețelei neuronale artificiale cu un strat ascuns de tip feed-forward (Dumitriu
&colab., 2016)
III. 2 Clasificarea datelor Un algoritm de învăţare supervizat va asocia tiparelor necunscute etichete ale claselor,
pe baza informaţiilor cunoscute apriori. Tiparele deja etichetate alcătuiesc setul datelor de antrenare. Un algoritm de grupare are ca scop generarea unui model pe baza căruia să poată fi clasificate și alte date, neincluse în setul de antrenare.
TABELUL III.2 INDICATORI DE PERFORMANŢĂ
Nume indicator Formula
Acurateţea: 𝐴𝑐𝑐 =𝑇𝑃 + 𝑇𝑁
𝑃 + 𝑁 (III.6)
Specificitatea: 𝑆𝑝𝑒𝑐 =𝑇𝑁
𝑇𝑁 + 𝐹𝑃= 1 − 𝐹𝑃𝑅 (III.7)
Valoarea pozitiv predictivă: (engl. “Positive Predictive Value”)
(numită şi precizie) 𝑃𝑃𝑉 =
𝑇𝑃
𝑇𝑃 + 𝐹𝑃 (III.8)
Valoarea negativ predictivă: (engl. “Negative Predictive
Value”) 𝑁𝑃𝑉 =
𝑇𝑁
𝑇𝑁 + 𝐹𝑁 (III.9)
Indicatorul F: 𝐹 = 2𝑃𝑃𝑉 ∙ 𝑇𝑃𝑅
𝑃𝑃𝑉 + 𝑇𝑃𝑅 (III.10)
Crearea unui astfel de model presupune mai întâi iniţializarea unor parametri specifici modelului respectiv, apoi cuprinde o etapă de validare a modelului astfel obţinut cu ajutorul unor seturilor de date de testare. Nerelevanţa datelor de antrenare duce la lipsa de generalizare a clasificatorului, acesta generând rezultate neconcludente pentru alte seturi. Din acest motiv, înainte de antrenare setul de date cunoscut este împărţit într-un set de antrenare şi un set de date utilizat pentru validare. Cunoscându-se etichetele datelor de antrenare şi de validare se pot defini o serie de indicatori ce măsoară calitatea performanţelor algoritmilor de clasificare.

Cap. III Modelarea și clasificarea datelor
14
În literatura de specialitate se regăsesc o multitudine de algoritmi de clasificare. Astfel unii sunt bazaţi pe instanţe, alții sunt bazate pe metode probabilistice (rețele bayesiene, modele Markov ascunse, etc) sau pe ansambluri (păduri de arbori sau AdaBoost) ori bazați pe reguli (CN2, CBA, etc.
Pentru algoritmii bazaţi pe instanţe, abstractizarea nu este un element cheie în procesul de construire a modelului, ceea ce poate penaliza clasificatorul în procesul de etichetare a instanţelor (Aggarawal, 2015). Deşi au o învăţare lentă şi de multe ori costisitoare din punct de vedere al calculului computaţional, crearea unor modele bazate pe instanţe relevante local au şi avantaje precum faptul că principalele caracteristici specifice nu sunt ignorate.
KNN este un algoritm de învăţare supervizată bazat pe valoarea etichetării celor mai apropiaţi K vecini. Aceştia sunt consultaţi şi printr-un vot majoritar se hotărăşte clasa noii instanţe ca fiind aceeaşi cu majorităţii. Problema alegerii celor mai apropiaţi vecini însă nu este una uşor de rezolvat, complexitatea identificării acestora fiind dependentă de numărul tiparelor existente în seturile de date.
SVM separă clasele calculând o suprafaţă de decizie aflată la distanţa maximă de punctele clasificate. Separarea datelor se face cu ajutorul unui hiperplan, care împarte instanţele din cele două clase fără eroare folosind distanţa maximă de la cel mai apropiat eşantion pozitiv şi negativ. Dacă clasele nu sunt liniar separabile se asigură un număr minim de instanţe clasificate greşit.
O altă categorie o reprezintă algoritmii bazaţi pe metode probabilistice. Dintre aceştia amintim reţelele bayesiene, regresia logistică sau modelele Markov. Aceştia folosesc analiza statistică pentru atribuirea etichetei potrivite unei instanţe (Deng & colab., 2015).
De asemenea o clasă mai nouă dar extrem de promiţătoare este cea bazată pe ansambluri precum RF (păduri de arbori de decizie) sau AdaBoost ce utilizează agregarea prin amplificare. Învăţarea bazată pe ansambluri presupune agregarea mai multor clasificatori slabi pentru a obţine un rezultat final bun. Fiecare dintre clasificatorii slabi reuşesc să rezolve independent problemele de clasificare pentru ca, mai apoi, prin mediere sau prin vot majoritar să se specifice încadrarea finală într-o anumită clasă (Wang & Yang, 2013).
Propus de Freund și Schapire, AdaBoost (”AdaptiveBoosting” – engl.) este unul din cei mai utilizați algoritmi de amplificare. Acesta actualizează setul de ponderi asociate exemplelor din setul de antrenare. La fiecare iterație sunt construiți trei algoritmi de învățare slabă, iar deciziile celor trei algoritmi sunt agregate prin vot majoritar.
Pădurile de arbori generați în mod aleator RF (”Random Forests” – engl.) lucrează pe ansambluri de arbori de decizie sau de regresie CART (”Classification And Regression Trees” – engl.) nesimplificați. Similar algoritmilor de ambalare, RF eșantionează atributele fără a le înlocui pentru construirea nodurilor fiecărui arbore. Arborii sunt construiți cu adâncime maximă fără simplificări, fiecare dintre aceștia fiind gestionat în mod independent (Breiman, 2001). Fiecare arbore asociază câte o clasă tiparelor din set, pădurea fiind cea care decide clasa finală prin vot majoritar sau prin mediere.

15
Capitolul IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
IV.1 Aplicaţii ale algoritmului evolutiv ICA
IV.1.1 Optimizarea operatorilor specifici ICA Problema găsirii unor valori optimimale de aproximare a funcțiilor a fost studiată mult
timp. Algoritmii Genetici introduși în (Holland, 1975), sau metode propuse în (Ramezania & colab., 2013), Particle Swarm Optimization – PSO (Clerc & colab., 2002), Ant Colony Optimization (Clerc & colab., 2002), Artificial Bee Colony Algorithm (Gao & colab., 2012; Lin & colab., 2012; Zhang & colab.,2011) sunt tot atâtea exemple de simulări computaționale ale evoluției biologice. Pentru unele probleme, GA sunt suficiente pentru rezolvarea problemelor și găsirea unei soluții, dar există multe tipuri de probleme pentru care soluția optimă nu poate fi obținută (datorită unui număr mic de iterații sau a problematicii optimului local). În astfel de cazuri, algoritmii hibrizi sunt preferați (Ramezania & colab., 2013).
Operatori ai algoritmii genetici combinați cu ICA dovedesc rezultate foarte bune în rezolvarea problemelor ridicate de optimizare, cum ar fi evitarea capcanei optimului local. Capcana optimului local este tendința unui algoritm de a găsi un optim local în detrimentul optimului global.
Un nou algoritm bazat pe hibridizarea ICA cu GA și elemente din teoria haosului a fost propus și s-a studiat comportamentul acestuia pentru aproximarea valorii minime a unei funcții în raport cu Algoritmi Genetici clasici, cu Algoritmul Imperialist Competitiv și cu Algoritmii ICAAI, ICACI, CICA, descriși în capitolul II.
Majoritatea cercetătorilor care au studiat și propus versiuni noi ale ICA au încercat să îmbunătățească pasul de asimilare sau să crească forța etapei de competiție, eventual în combinație cu alți algoritmi cum ar fi GA, PSO, k-Means. Unii dintre ei au studiat constrângerile privind condițiile de pornire pentru ICA. Algoritmul propus în această teză utilizează cele mai bune dintre aceste constrângeri sau propuneri de îmbunătățiri pentru a asigura diversitatea indivizilor dar și pentru a evita blocarea într-un optim local.
Numărul de iterații pare să fie soluția cea mai utilizată și cea mai utilă pentru condițiile de oprire. Cu toate acestea, sunt de discutat două aspecte:
1) Dacă numărul de iterații este mare și numărul de imperii este mic, este posibil să se obțină un singur imperiu care conține toate țările cu mult înainte de îndeplinirea condițiilor de oprire. În acest caz, competiția nu are loc (aceasta se desfășoară între două imperii), iar algoritmul folosește doar operația de asimilare pentru a varia indivizii.
2) Dacă numărul de iterații este prea mic, soluția optimă obținută poate să nu fie cel mai bun rezultat așteptat.
Pentru a depăși astfel de neajunsuri, a fost propusă o nouă abordare în (Dumitriu, 2015). Principala diferență între versiunea propusă și celelalte versiuni studiate este aceea că, atunci când se ajunge la un singur imperiu care conține toate coloniile, algoritmul, în loc să se oprească reîmparte populația în multe imperii cu aceleași reguli aplicate distribuției inițiale pentru

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
16
imperialiști și colonii. Apoi, se reiau operațiunile de asimilare, interacțiune și competiție așa cum reiese din pseudocodul de mai jos.
Algoritmul IV.1 Algoritmul propus bazat pe ICA (Dumitriu, 2015)
Pasul 1: Definirea problemei de optimizare. Pasul 2: Generează țările și calculează costul fiecăreia Pasul 3: Alege dintre țări pe cele cu cele mai bune costuri pentru a deveni
imperialiștii inițiali. Calculează costul inițial al imperiului. Pasul 4: Calculează puterea inițială a unui imperiu. Pasul 5: Calculează numărul inițial de colonii pentru fiecare imperiu. Pasul 6: Distribuie aleator celelalte țări fiecărui imperiu (acestea devin colonii). repetă pentru fiecare imperiu i
Pasul 7: Aplică operatorul de asimilare pentru toate coloniile și pentru unele colonii calculează un unghi θ pentru schimbarea direcției față de imperialist folosind scheme din teoria haosului cum propune algoritmul CICA.
Pasul 8: Ajustează valorile dacă acestea depășesc domeniul de definiție. Pasul 9: Recalculează costul noilor colonii. Pasul 10: Actualizează imperialiștii prin interschimbarea cu colonia cu cel mai bun
cost din imperiu, daca este cazul. Pasul 11: Recalculează costul și puterea imperiilor.
sfârșit pentru dacă (numărul imperiilor > 1)
Pasul 12: Aplică operatorul de interacțiune între imperialiști conform metodelor propuse în ICACI și ICAAI.
Pasul 13: Aplică operatorul competiție cu o probabilitate 𝜌. sfârșit dacă dacă (numărul de imperii = 1)
Pasul 14: Alege cele mai bune colonii pentru a fi noii imperialiști. Recalculează costurile. Acești imperialiști vor forma noile imperii.
Pasul 15: Calculează puterea fiecărui imperiu. Pasul 16: Recalculează numărul de colonii pentru fiecare dintre noile imperii. Pasul 17: Redistribuie aleatoriu coloniile în noile imperii.
sfârșit dacă până când sunt îndeplinite condițiile de stop.
Pașii 1-6 definesc și configurează împărțirea pe imperii și alegerea imperialiștilor conform celor mai bune metode de calculare a numărului de imperialişti şi respectiv, de distribuţie uniformă a numărului de colonii ataşat fiecărui imperialist. În acest fel se evită posibilitatea ca un imperiu să fie lipsit de colonii.
Pasul 7 ajută la diversificarea spaţiului de explorare, prin apropierea de colonist. Unghiul θ utilizat în cazul încercării de a schimba direcţia de repoziţionare poate duce noul individ mai aproape sau îl poate îndepărta de imperialist, dar poate oferi şansa apariţiei unor noi indivizi mai bine adaptați. De asemenea, generarea valorilor pentru unghiul θ poate fi făcută aleator, sau după anumite procedee precum tabelele de scheme pentru funcţiile haotice.
În Tabelul IV.1 sunt trecute schemele utilizate în faza experimentală.

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
17
TABELUL IV.1 HĂRȚILE DE HAOS UTILIZATE ÎN EXPERIMENTE
Chaotic map Function
CM1 )θ1(θθ 1 iii a
CM2 )θsin(θθ 2
1 iii a
CM3 )1mod()θsin()2/(θθ 1 iii ai
CM4
5.0θif),θ1(
5.0θif,θθ 1
ii
ii
ia
a
Paşii 8 - 11 reevaluează valoarea indivizilor, interschimbând imperialiştii cu coloniile
acestora, dacă este cazul. În general acest lucru se întâmplă de puţine ori în timpul explorării întrucât încă de la început cei mai buni indivizi sunt extraşi din mulţime ca imperialişti. Aceştia devin de fapt princilpala sursă de selecţie, dar nu este neglijat nici bazinul oferit de celelalte soluţii potenţiale.
În pasul 12 se aplică operatorul de interacţiune între imperialişti pentru a obţine noi indivizi valoroşi. Interacţiunea în sine introduce cu o anumită probabilitate µ generată aleator (pentru a nu diversifica populaţia până la o explorare aleatoare), un nou individ creat artificial, pe de o parte, iar pe de alta se aplică operatorul genetic de încrucişare cu un punct de tăiere generat aleator între imperialiști. Dacă noii indivizi sunt mai adaptaţi decât imperialiştii curenţi atunci aceştia vor fi înlocuiţi. Indivizii obţinuţi astfel dar neperformanţi vor fi eliminaţi.
În pasul 13 se determină cu o anumită probabilitate şansa de a aplica operaţia de competiţie. Impactul acestei operaţii asupra întregului proces de explorare este limitat, ca atare nu este neapărat necesar ca el să se desfăşoare des. În această etapă cea mai slabă colonie din cel mai slab imperiu este smulsă acestuia şi redistribuită unui alt imperiu. În (Dumitriu, 2015) se propune ca cea mai slabă colonie să fie întotdeauna dată imperiului cu cel mai bun cost. Efectul acestei acţiuni este că încet toate coloniile migrează către un singur imperiu, refăcând o singură populaţie cu un singur imperialist. De asemnea, dacă un imperiu nu mai are colonii, imperialistul în mod automat se inglobează în cel mai bun imperiu.
Totuşi uneori acest fapt poate duce la o convergenţă prematură, chiar dacă etapa de competiţie este controlată pentru a fi lentă. De aceea în paşii 14-17 se redistribuie populaţia în noi imperii respectând aceleaşi proceduri ca şi la etapa de iniţializare a populaţiei, dar având acum un nou bazin de soluţii potenţiale, puternic imbunătăţit, însă şi suficient de diversificat pentru a nu conduce explorarea într-o direcţie indicată doar de câţiva indivizi precum ar putea fi întâlnită în cazul unor algoritmi genetici.
Pentru a lărgi zona de căutare, algoritmul propus a folosit în etapa de asimilare o mișcare aparent haotică a unor colonii către imperialist. Aceste funcţii sunt preferate de diverşi cercetători precum (Bing-rui & colab., 2008; Gao & colab., 2008). Acest comportament generat de hărțile de haos prezentate în Tabelul IV.1 a dus la rezultate promiţătoare în sensul descoperirii unor metode de accelerare a atingerii valorii optimale dorite.
Algoritmul propus (Algoritmul IV.1) utilizează, de asemenea, numărul de iterații ca și condiție de stop, dar rezultatele sunt diferite în cele două cazuri considerate. Dacă numărul de iterații este mare și numărul de imperii este mic, imperiile recreate, folosind constrângerile indicate, pot genera noii indivizi valoroşi. Dacă numărul de iterații este prea mic, repetarea operațiunilor de asimilare și competiție crește șansa de a găsi soluția optimă.

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
18
IV.1.2 Rezultate experimentale Pentru a testa eficienţa algoritmului propus (Algoritmul IV.1), au fost implementaţi variaţii ale algoritmului ICA conform metodelor prezentate în capitolul II. Acestea au fost denumite simplu ICA-varianta originală, nemodificată a algoritmului, ICAAI – algoritmul ICA ce foloseşte infuzia unui imperialist creat artificial, ICACI – algoritmul ICA în care se aplică încrucişarea între imperialişti, CICA – algoritmul ICA original, dar care în etapa de asimilare foloseşte variaţia indivizilor doar schemele de haos indicate. Totodată un algoritm genetic clasic a fost implementat. Toţi algoritmii au fost testaţi pentru rezolvarea aceloraşi probleme.
Zece funcții de referință au fost folosite pentru a testa algoritmii. Aceste funcții de referință au fost propuse și acceptate la conferințele CEC’2013 ca fiind utile în testarea algoritmilor de optimizare (Xiaodong & colab., 2013a; Suganthan, 2005; Xiaodong & colab., 2013b). Aceste funcții sunt notate după cum urmează: 1F - funcția Rastrigin, 2F - Sphere, 3F -
Rosenbrok, 4F - Griewangk, 5F - Schwefel, 6F - Sphere2, F7 - Ackley, 8F - SumSqare, 9F -
Zakharov, 10F - Vincent. Toți algoritmii au fost testați pentru toate cele zece funcţii. Experimentele implicate au
variat valorile pentru numărul de imperii, numărul de țări sau numărul de iterații.
Teste de timp pentru numărul de iterații Pentru rezultatele prezentate în Tabelul IV.3 condiţia de oprire a fost la efectuarea unui
număr de 300 și respectiv 10.000 de iterații. Populația inițială generată este de 100 de indivizi, iar numărul de imperii a fost ajustat la 20% din întreaga populație. De asemenea, fiecare algoritm a fost rulat de 30 de ori pentru fiecare funcție pentru a calcula o valoare medie a timpului. În Tabelul IV.3 sunt prezentate rezultate medii pentru rulările cu 300 de epoci/
TABELUL IV. 3 VALORILE OBŢINUTE DUPĂ 300 ITERAŢII
Studiind aceste rezultate se observă că valorile obținute de la noul algoritm sunt mai aproape de valorile dorite decât cele obținute de ceilalți algoritmi, în majoritatea cazurilor.
Teste de timp legate de atingerea valoarii optime Un alt test a fost făcut pentru a determina timpul până la atingerea valorii optime pentru
fiecare funcție de referință și pentru fiecare tip de algoritm. Este evident că, în majoritatea cazurilor, noul algoritm realizează o astfel de valoare mai rapid decât alți algoritmi. Pentru aceste teste au fost folosite maxim 3000 iterații pentru fiecare algoritm.
F1 F2
Valoare medie Timp (în sec) Valoare medie Timp (în sec)
AG 0.019636433 0.018577 4.43511E-05 0.012633333
CICA 40.09056289 0.006923 4.998350858 0.005166667
ICA 4.746746708 0.039867 3.921256911 0.045066667
ICAAI 1.098034458 0.042867 3.91437E-16 0.017666667
ICACI 13.63115156 0.056667 4.87652E-17 0.021333333
New Alg 4.875330557 0.081100 2.28557E-17 0.027066667
Valoare așteptată 0 0

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
19
Figura IV. 1 Rezultatele pentru funcția de referință F1.
Figura IV. 2 Evoluția algoritmilor GA, ICA și NewAlg (300 generații, 20 țări)
Experimente privind numărul de iterații Evoluția a trei dintre algoritmii testați este prezentată în Figura IV.5 pentru 300 de
generații și un număr mic de indivizi (20 de țări) exemplificați pentru funcția F1, cu numărul de
variabile 6n . În Figura IV.6 au fost utilizați aceiași parametri pentru toți algoritmii și funcția de referință F1. Linia neagră din figura IV.5 indică tendința generală a noului algoritm de a ajunge la o soluție optimă mai rapid decât ceilalți algoritmi. O evoluție similară a fost observată pentru majoritatea funcțiilor de referință.
Teste statistice Pe baza Student’s t-Test, rezultatele experimentale au arătat valori îmbunătățite
folosind algoritmul propus în comparație cu ceilalți algoritmi utilizați în experimente.
Pentru a crea intrările pentru one-sample t - test, au fost făcute 27 de runlări consecutive pentru fiecare funcție de referință. Setările au fost pentru 300 de generații și 20 de imperii. Toate valorile de ieșire au arătat că nu există o diferență statistică semnificativă între rezultatele algoritmului propus și media optimă în cazul funcțiilor de referință F1-F10 ( t)P(T
este mai mică decât 0,05).
IV.2 Aplicații ale rețelelor neuronale artificiale (RNA) în eliberarea de medicamente
IV.2.1 Hidrogelurile Hidrogelurile sunt rețele polimerice tridimensionale hidrofile, capabile să se umfle,
reținând în interiorul rețelei lor cantități semnificative de apă sau fluide biologice (de pana la mii de ori mai mari decat greutatea lor uscată), dar rămân insolubile în soluțiile apoase datorită reticulării fizice sau chimice a lanțurilor polimerice. Capacitatea de umflare a hidrogelurilor este determinată de natura hidrofilă a lanțurilor polimerice sau de prezența unor grupări funcționale hidrofile, precum și de densitatea de reticulare.
La ora actuala, unul din principalele domenii de aplicare a hidrogelurilor este reprezentat de sistemele de eliberare controlată a medicamentelor. Dezvoltarea de noi sisteme pentru eliberarea medicamentelor pe baza de hidrogeluri biodegradabile, inteligente, biomimetice a devenit o direcție de cercetare predilectă în in industria farmaceutică.
Numeroase formulări farmaceutice cu eliberare controlată au în vedere în special o eliberare susținută a agentului terapeutic în organism, reducând frecvența administrării și făcând

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
20
procedura neinvazivă pentru pacient. Materialele poroase cum sunt hidrogelurile polimerice au capacitatea de a încărca cu ușurință medicamente și de a controla mai bine eliberarea lor (Berg & colab., 2006).
Rețelele neuronale artificiale RNA au fost utilizate ca instrumente de modelare pentru predicția comportării la eliberare a două medicamente (teofilină și ketoprofen) din sisteme de tip hidrogel poli (N-izopropil acrilamida) (PNIPAAm) / alginat de sodiu (ALG). Compoziția hidrogelurilor studiate și timpul au fost considerate ca parametri de intrare pentru modelarea procesului și au fost variate în funcție de un program experimental prestabilit, iar procentul de eliberare a medicamentului a fost parametrul de ieșire. Obiectivul studiului a fost acela de a furniza modele predictive ale problemei analizate.
IV.2.2 Procedee experimentale Pentru acest studiu s-au selectat trei sisteme de hidrogel preparate cu diferite compoziții
în ce privește raportul procentual NIPAAm/ALG, si anume 99/1, 80/20 și 75/25. Ca medicamente model pentru experimentele de eliberare in vitro au fost alese teofilina și ketoprofenul.
Teofilina este un medicament (derivat dimetil xantinic) cu o acțiune bronhodilatatoare puternică, utilizat pe scară largă în tratamentul bolilor respiratorii cum ar fi astmul acut și boala pulmonară obstructivă cronică, fiind cunoscut și pentru efectul antiinflamator și imunomodulator atunci când este administrat în doze mici și pentru a crește capacitatea de reacție la corticosteroizi (Dumitriu & colab., 2016). Ketoprofenul este un medicament antiinflamator clasic nesteroidal, analgezic și antipiretic, eficient în tratamentul artritei reumatoide și osteoartritei, spondilitei; trateaza simptomele de durere si inflamație. Ketoprofenul administrat în doze mari poate provoca leziuni ale stomacului, precum ulcer gastric și sângerare (Savage & colab., 1993), prin urmare încărcarea lui în formele de dozare cu eliberare susținută este avantajoasă, deoarece permite scăderea frecvenței de administrare a dozelor.
Investigațiile de eliberare in vitro a medicamentelor au fost realizate printr-un test standard de disoluție/dizolvare efectuat în soluție tampon fosfat de pH 7,4 ca mediu de dizolvare, la 37 oC. La intervale de timp predeterminate, au fost recoltate probe de câte 1 mL din mediul de eliberare, care au fost analizate utilizând un spectrofotometru UV-VIS HP 8450A la lungimile de undă caracteristice pentru fiecare dintre medicamentele investigate: la 271 nm pentru teofilină și respectiv la 260 nm pentru ketoprofen. Concentrațiile de medicament au fost calculate pe baza curbelor de etalonare efectuate anterior la aceleași lungimi de undă. S-au realizat câte trei experimente în fiecare caz. Rezultatele acestora au fost considerate date de intrare pentru modelarea RNA
IV.2.3 Modelarea și structura RNA Numărul de neuroni artificiali de pe un strat și numărul de straturi influențează abilitățile
de predicție. Dacă numărul de perceptroni este prea mic rețeaua va fi slab antrenată (rețeaua nu învață problema). În cazul în care perceptronii sunt prea mulți, se poate obține o suprapotrivire în rețea. Ambele situații trebuie evitate. Pentru a face acest lucru, în această lucrare a fost testat un număr diferit de perceptroni pe un strat ascuns.
În această lucrare, funcția sigmoidală binară a fost utilizată ca funcție de activare:
xexf
1
1)( , (IV.2)
unde α este un parametru care determină panta neliniarității. Pentru parametrul α s-au atribuit diferite valori între 0,5 și 4. Pentru RNA antrenată valoarea α = 2 a oferit rezultate mai bune.
Pentru acest experiment s-a utilizat o RNA având ca intrări compoziția hidrogelurilor și timpul, un strat ascuns cu un număr variabil de neuroni și stratul de ieșire care utilizează numai
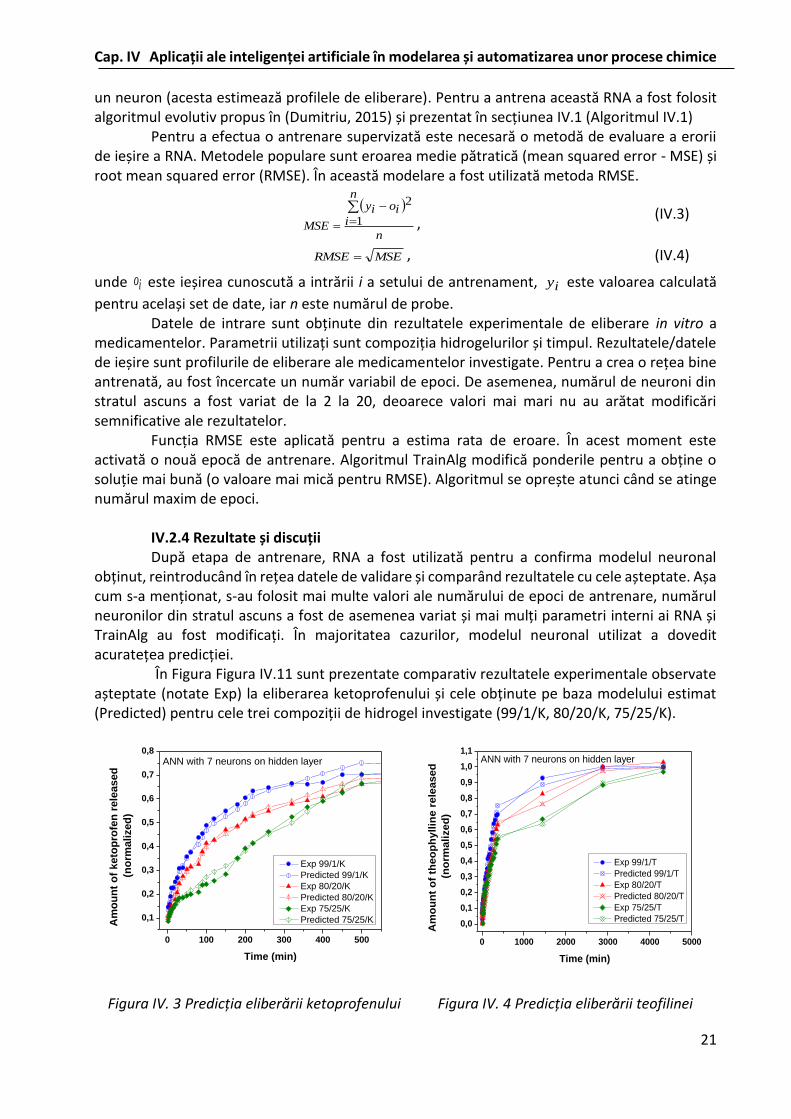
Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
21
un neuron (acesta estimează profilele de eliberare). Pentru a antrena această RNA a fost folosit algoritmul evolutiv propus în (Dumitriu, 2015) și prezentat în secțiunea IV.1 (Algoritmul IV.1)
Pentru a efectua o antrenare supervizată este necesară o metodă de evaluare a erorii de ieșire a RNA. Metodele populare sunt eroarea medie pătratică (mean squared error - MSE) și root mean squared error (RMSE). În această modelare a fost utilizată metoda RMSE.
n
n
iioiy
MSE
1
2
, (IV.3)
MSERMSE , (IV.4)
unde io este ieșirea cunoscută a intrării i a setului de antrenament, iy este valoarea calculată
pentru același set de date, iar n este numărul de probe. Datele de intrare sunt obținute din rezultatele experimentale de eliberare in vitro a
medicamentelor. Parametrii utilizați sunt compoziția hidrogelurilor și timpul. Rezultatele/datele de ieșire sunt profilurile de eliberare ale medicamentelor investigate. Pentru a crea o rețea bine antrenată, au fost încercate un număr variabil de epoci. De asemenea, numărul de neuroni din stratul ascuns a fost variat de la 2 la 20, deoarece valori mai mari nu au arătat modificări semnificative ale rezultatelor.
Funcția RMSE este aplicată pentru a estima rata de eroare. În acest moment este activată o nouă epocă de antrenare. Algoritmul TrainAlg modifică ponderile pentru a obține o soluție mai bună (o valoare mai mică pentru RMSE). Algoritmul se oprește atunci când se atinge numărul maxim de epoci.
IV.2.4 Rezultate și discuții După etapa de antrenare, RNA a fost utilizată pentru a confirma modelul neuronal
obținut, reintroducând în rețea datele de validare și comparând rezultatele cu cele așteptate. Așa cum s-a menționat, s-au folosit mai multe valori ale numărului de epoci de antrenare, numărul neuronilor din stratul ascuns a fost de asemenea variat și mai mulți parametri interni ai RNA și TrainAlg au fost modificați. În majoritatea cazurilor, modelul neuronal utilizat a dovedit acuratețea predicției.
În Figura Figura IV.11 sunt prezentate comparativ rezultatele experimentale observate așteptate (notate Exp) la eliberarea ketoprofenului și cele obținute pe baza modelului estimat (Predicted) pentru cele trei compoziții de hidrogel investigate (99/1/K, 80/20/K, 75/25/K).
0 100 200 300 400 500
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
ANN with 7 neurons on hidden layer
Exp 99/1/K
Predicted 99/1/K
Exp 80/20/K
Predicted 80/20/K
Exp 75/25/K
Predicted 75/25/KAm
ou
nt
of
keto
pro
fen
rele
ased
(no
rmali
zed
)
Time (min)
0 1000 2000 3000 4000 5000
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
Exp 99/1/T
Predicted 99/1/T
Exp 80/20/T
Predicted 80/20/T
Exp 75/25/T
Predicted 75/25/T
ANN with 7 neurons on hidden layer
Am
ou
nt
of
theo
ph
yll
ine r
ele
ased
(no
rmali
zed
)
Time (min)
Figura IV. 3 Predicția eliberării ketoprofenului Figura IV. 4 Predicția eliberării teofilinei

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
22
Profilurile comparative de eliberare a teofilinei din cele trei compoziții de hidrogel (99/1 / T, 80/20 / T, 75/25 / T) sunt prezentate în Figura IV.12.
În cazul teofilinei predicția a fost chiar
mai exactă decât pentru eliberarea ketoprofenului. Rezultatele obținute au arătat, de asemenea, o predicție exactă și pentru un număr mai
mare de neuroni pe stratul ascuns și / sau epoci de antrenare. Pentru ambele medicamente, predicția a urmat aceeași tendință ca și rezultatele obținute experimental în funcție de compoziția hidrogelurilor.
A fost studiat și timpul de antrenare. În toate cazurile, timpul este satisfăcător. Mai mult, timpii de antrenare necesari pentru ambele medicamente investigate sunt similari
IV.3 Rețelele neuronale artificiale pentru predicția comportării reologice a unor suspensii coloidale cu nanoparticule de argint
IV.3.1 Aspecte generale și tendințe recente în studiile efecutate asupra unor suspensii
coloidale cu nanoparticule de argint Evaluarea eficienței utilizării amestecurilor pe bază de alginat de sodiu și lignosulfonat
de amoniu ca matrice de dispersie pentru nanoparticulele de argint, în scopul prelucrării
suspensiilor coloidale cu argint pentru aplicații specifice a fost deasemenea studiată.
Comportamentul reologic al suspensiilor cu nanoparticule de argint obținute in situ a fost
investigat prin măsurători realizate în rotație, folosind geometria con-placă, în funcție de
compoziția dispersiei. În general, toate suspensiile cu nanoparticule studiate au arătat un
comportament ne-newtonian, prezentând o scădere puțin semnificativă a vâscozității atunci
când conținutul de nanoparticule crește. Pentru a estima teoretic datele experimentale, s-au
folosit ca instrumente de modelare rețele neurale artificiale și support vector regression (SVR).
Analiza comparativă a datelor experimentale cu rezultatele obținute prin simulare a arătat o
precizie ridicată a estimării atât prin utilizarea rețelelelor neuronale artificiale, cât și cu support
vector regression, în special pentru dependența tensiune de forfecare – viteză de forfecare.
În această lucrare, RNA și SVR au fost utilizate ca instrumente de modelare pentru predicția a doi parametri reologici importanți: tensiunea la forfecare și vâscozitatea. Compoziția sistemului, viteza de forfecare și alți parametri reologici au fost considerați ca date de intrare pentru modelarea procesului. Obiectivul a fost de a oferi modele predictive ale problemei analizate și de a indica cel mai bun model pentru o problemă specifică.
IV.3.2 Procedee experimentale La prepararea suspensiilor cu nanoparticule de argint s-au folosit ca materiale de plecare
azotatul de argint (AgNO3), alginatul de sodiu (ALG) extras din alge brune (Sigma-Aldrich) și lignosulfonatul de amoniu (ALS) (Zarnesti, România).
S-a investigat experimental comportamentul reologic al suspensiilor coloidale de argint sintetizate in situ preparate fie în soluție de alginat, fie în amestecuri de alginat / lignosulfonat cu diferite compoziții. Proprietățile reologice au fost măsurate cu ajutorul unui reometru Anton-Paar Physica MCR 301 echipat cu geometrie con-placă având diametrul de 50 mm. Vâscozitatea și tensiunea de forfecare au fost măsurate în intervalul de viteză de forfecare de la 0,01 la 200 1/s.

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
23
IV.3.2.1 Modelarea cu rețele neuronale artificiale În această lucrare experimentală a fost utilizată o RNA cu șase neuroni artificiali pe
stratul de intrare, un strat ascuns cu un număr variabil de perceptroni și doi neuroni pe stratul de ieșire (Figura IV.15).
Compoziția sistemului (conținutul de nanoparticule de argint, conținutul de lignosulfonat și alginat), viteza de forfecare, viteza și cuplul sunt datele de intrare.
Figura IV. 5 Schema rețelei neuronale RNA utilizate
Pe stratul ascuns a fost testat un număr variabil de neuroni artificiali pentru a găsi cea mai bună soluție pentru modelul RNA propus. Pe stratul de ieșire, cei doi neuroni estimează vâscozitatea și tensiunea de forfecare pentru compoziția dorită. Pentru antrenarea RNA, s-a folosit metoda Levenberg-Marquardt. Alte metode testate (gradient descendent, gradient descendent cu impuls, gradient conjugat) nu au arătat o performanță mai bună pentru această RNA. În timpul antrenării, valorile ponderilor și ale bias-urilor au fost optimizate până la minimizarea erorii predicțiilor.
IV.3.2.2 Support Vector Machine for Regresion (SVR) După cum a observat Granata în (Granata & colab., 2016), studiile asupra aplicațiilor
SVR capabile să prezică valorile reale cu mare precizie se găsesc doar într-un număr limitat în literatură.
Modelul SVR este construit folosind un set de date de antrenare, deoarece funcția care creează modelul ignoră datele apropiate de predicția modelului. Dacă erorile sunt mai mici decât ε, ele sunt ignorate, în timp ce abaterile sunt penalizate în mod liniar. Modelul SVR poate utiliza una dintre funcțiile kernel bine cunoscute, cum sunt funcțiile liniare, pătratice, gaussiene, logistice sau polinomiale. În testele experimentale realizate s-au folosit funcțiile kernel liniară și rbf.
Cu datele obținute din experimentele reologice (mai mult de 600 de înregistrări de date, fiecare dintre ele cu opt parametri măsurați) s-au creat două seturi de date. Primul set, notat
],[ ssss YXD utilizează tensiunea de forfecare ca valoare de răspuns ( ssY ). Al doilea set de date
],[ vv YXD utilizează vâscozitatea ca valoare de răspuns ( vY ). Pentru ambele, X este aceeași
colecție de date de intrare ca și în modelul RNA și este utilizată la SVR ca valoare predictor.
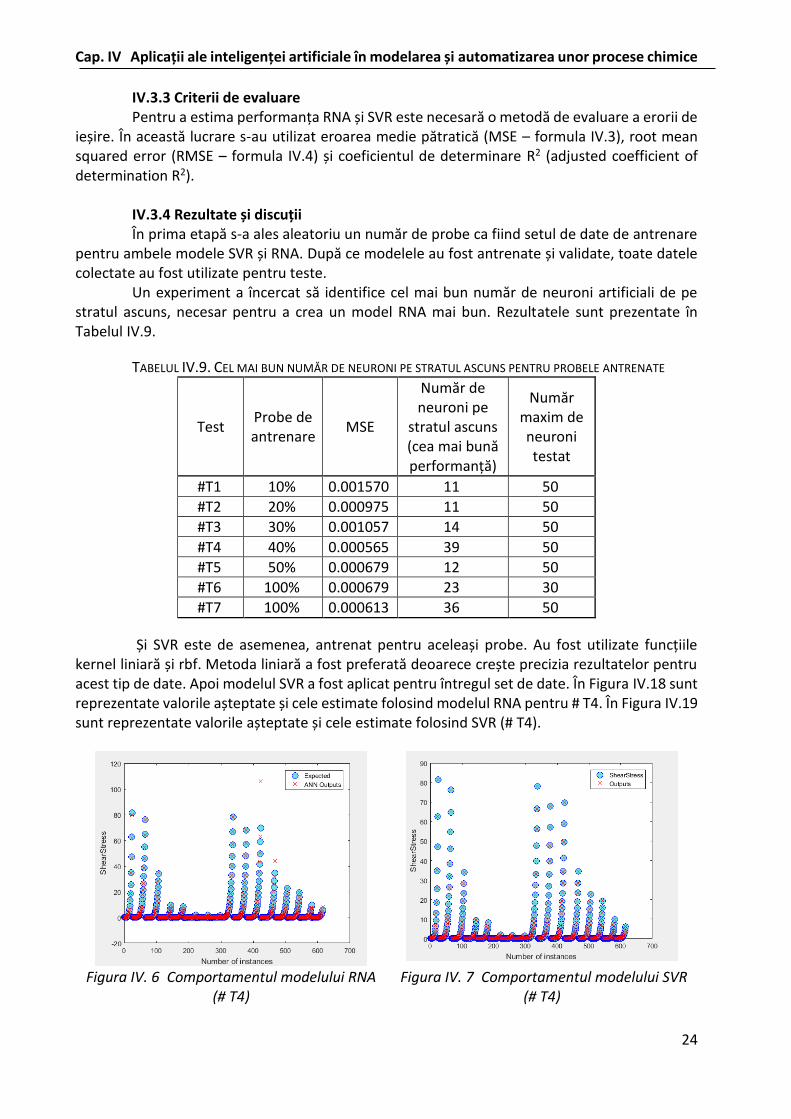
Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
24
IV.3.3 Criterii de evaluare Pentru a estima performanța RNA și SVR este necesară o metodă de evaluare a erorii de
ieșire. În această lucrare s-au utilizat eroarea medie pătratică (MSE – formula IV.3), root mean squared error (RMSE – formula IV.4) și coeficientul de determinare R2 (adjusted coefficient of determination R2).
IV.3.4 Rezultate și discuții În prima etapă s-a ales aleatoriu un număr de probe ca fiind setul de date de antrenare
pentru ambele modele SVR și RNA. După ce modelele au fost antrenate și validate, toate datele colectate au fost utilizate pentru teste.
Un experiment a încercat să identifice cel mai bun număr de neuroni artificiali de pe stratul ascuns, necesar pentru a crea un model RNA mai bun. Rezultatele sunt prezentate în Tabelul IV.9.
TABELUL IV.9. CEL MAI BUN NUMĂR DE NEURONI PE STRATUL ASCUNS PENTRU PROBELE ANTRENATE
Test Probe de antrenare
MSE
Număr de neuroni pe
stratul ascuns (cea mai bună performanță)
Număr maxim de neuroni testat
#T1 10% 0.001570 11 50
#T2 20% 0.000975 11 50
#T3 30% 0.001057 14 50
#T4 40% 0.000565 39 50
#T5 50% 0.000679 12 50
#T6 100% 0.000679 23 30
#T7 100% 0.000613 36 50
Și SVR este de asemenea, antrenat pentru aceleași probe. Au fost utilizate funcțiile kernel liniară și rbf. Metoda liniară a fost preferată deoarece crește precizia rezultatelor pentru acest tip de date. Apoi modelul SVR a fost aplicat pentru întregul set de date. În Figura IV.18 sunt reprezentate valorile așteptate și cele estimate folosind modelul RNA pentru # T4. În Figura IV.19 sunt reprezentate valorile așteptate și cele estimate folosind SVR (# T4).
Figura IV. 6 Comportamentul modelului RNA (# T4)
Figura IV. 7 Comportamentul modelului SVR (# T4)
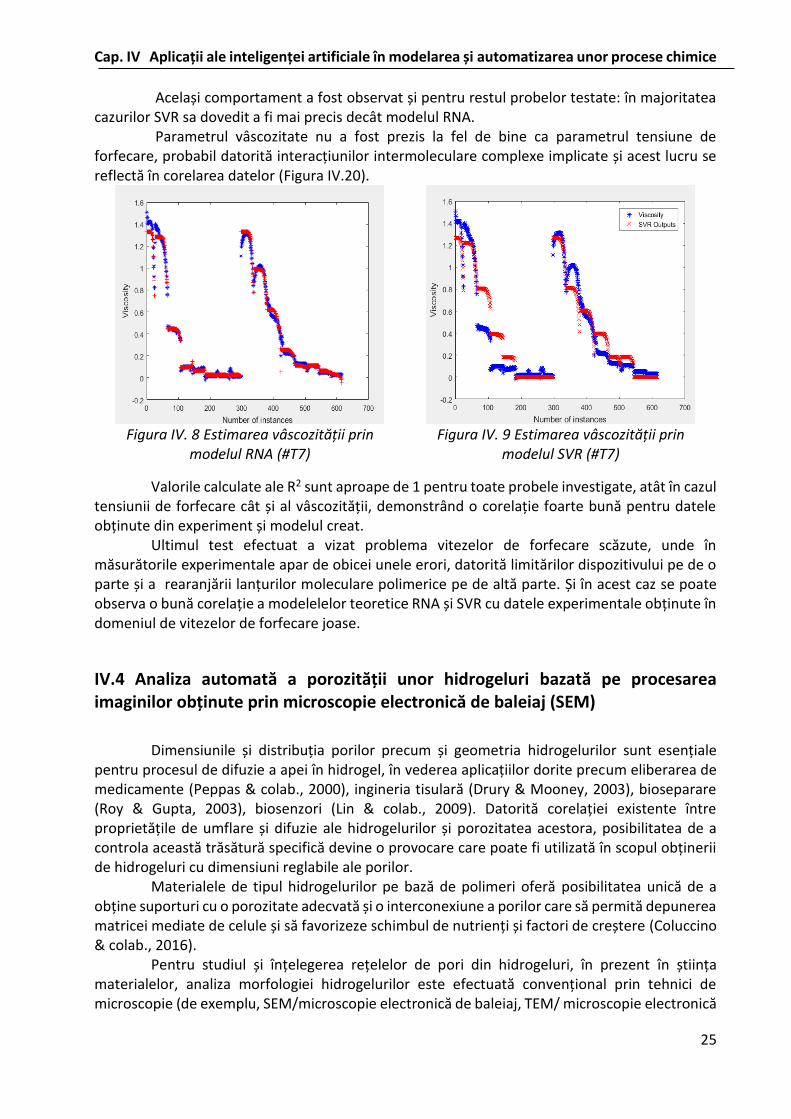
Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
25
Același comportament a fost observat și pentru restul probelor testate: în majoritatea cazurilor SVR sa dovedit a fi mai precis decât modelul RNA.
Parametrul vâscozitate nu a fost prezis la fel de bine ca parametrul tensiune de forfecare, probabil datorită interacțiunilor intermoleculare complexe implicate și acest lucru se reflectă în corelarea datelor (Figura IV.20).
Figura IV. 8 Estimarea vâscozității prin
modelul RNA (#T7) Figura IV. 9 Estimarea vâscozității prin
modelul SVR (#T7)
Valorile calculate ale R2 sunt aproape de 1 pentru toate probele investigate, atât în cazul tensiunii de forfecare cât și al vâscozității, demonstrând o corelație foarte bună pentru datele obținute din experiment și modelul creat.
Ultimul test efectuat a vizat problema vitezelor de forfecare scăzute, unde în măsurătorile experimentale apar de obicei unele erori, datorită limitărilor dispozitivului pe de o parte și a rearanjării lanțurilor moleculare polimerice pe de altă parte. Și în acest caz se poate observa o bună corelație a modelelelor teoretice RNA și SVR cu datele experimentale obținute în domeniul de vitezelor de forfecare joase.
IV.4 Analiza automată a porozității unor hidrogeluri bazată pe procesarea imaginilor obținute prin microscopie electronică de baleiaj (SEM)
Dimensiunile și distribuția porilor precum și geometria hidrogelurilor sunt esențiale
pentru procesul de difuzie a apei în hidrogel, în vederea aplicațiilor dorite precum eliberarea de medicamente (Peppas & colab., 2000), ingineria tisulară (Drury & Mooney, 2003), bioseparare (Roy & Gupta, 2003), biosenzori (Lin & colab., 2009). Datorită corelației existente între proprietățile de umflare și difuzie ale hidrogelurilor și porozitatea acestora, posibilitatea de a controla această trăsătură specifică devine o provocare care poate fi utilizată în scopul obținerii de hidrogeluri cu dimensiuni reglabile ale porilor.
Materialele de tipul hidrogelurilor pe bază de polimeri oferă posibilitatea unică de a obține suporturi cu o porozitate adecvată și o interconexiune a porilor care să permită depunerea matricei mediate de celule și să favorizeze schimbul de nutrienți și factori de creștere (Coluccino & colab., 2016).
Pentru studiul și înțelegerea rețelelor de pori din hidrogeluri, în prezent în știința materialelor, analiza morfologiei hidrogelurilor este efectuată convențional prin tehnici de microscopie (de exemplu, SEM/microscopie electronică de baleiaj, TEM/ microscopie electronică

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
26
de transmisie) folosite ca proceduri standard pentru examinarea detaliată a aspectului și dimensiunilor porilor. Aceste tehnici de analiză pot fi consumatoare de timp și au un anumit grad de subiectivitate, deoarece se bazează pe analiza vizuală prin mijloace empirice și manuale (Dunn & Schrlau, 2018; Campbell & colab., 2018). Abordarea analizei automate a imaginilor de microscopie are avantajul de a oferi informații mai rapide și mai precise comparativ cu analiza vizuală a micrografiilor SEM.
Cu scopul de a propune o analiză automată a imaginii utilă pentru caracterizarea porozității hidrogelurilor prin tehnici de prelucrare a imaginilor bazate pe micrografiile SEM, au fost analizate și propuse două metode. Prima metodă se bazează pe modelul Gaussian și clasifică porii pe baza distribuției suprafețelor lor. A doua metodă propune utilizarea criteriului J nu pentru a segmenta imaginea ci pentru pentru a clasifica porii în funcție de dimensiunile lor. Algoritmul de segmentare JSEG utilizează criteriul J ca o măsură a gradului de uniformitate a distribuției de culoare dintr-o clasă. Valoarea lui J se referă la gradul de distribuție a claselor de culori. Cu cât este mai uniformă distribuția claselor de culori, cu atât este mai mică valoarea lui J.
Studiul morfologiei hidrogelurilor a fost efectuat cu ajutorul unui microscop TESLA BS-300 SEM la o mărire de 200x. Investigația a fost efectuată pe eșantioane fracturate în azot lichid, uscate în prealabil prin înghețare. Probele de hidrogel studiate au fost acoperite cu straturi subțiri de argint/carbon, sub vid.
IV.4.1 Procesarea imaginilor A. Etapa de pre-procesare Metoda de investigare propusă utilizează imagini de microscopie SEM ca date de intrare.
Prelucrarea imaginii a fost efectuată pe opt probe de hidrogel preparate în diferite compoziții de PNIPAM / ALG și cu diferite concentrații de agent de reticulare, utilizând 11 imagini SEM selectate pentru testarea caracterizării automate a porozității. După încărcarea imaginii a fost aplicat un filtru. În general, filtrarea are rolul principal de a elimina zgomotul din imagini, dar poate fi folosit și pentru a extrage anumite caracteristici vizuale. Pentru a filtra o imagine, se aplică o operație de convoluție. Convoluția este procesul matematic care permite combinarea celor două intrări: unul este pixelul setat în imagine, iar celălalt este matricea kernel (Nixon & Aguado, 2008). Aplicând acest kernel (filtru) la o imagine, valoarea pentru fiecare pixel și pixelii vecini din imaginea originală va fi transformată.
După evaluarea mai multor tipuri de filtre, a fost preferat cel Gaussian. Acesta are avantajul de a fi circular, simetric iar marginile și liniile în diferite direcții sunt tratate la fel (Nixon & Aguado, 2008). În aceste lucrări, valorile din această distribuție sunt folosite pentru a construi o matrice de kernel 3x3, cu valoarea 5.0 inițial și apoi ajustată dinamic la valoarea cea mai potrivită.
B. Analiza imaginilor Următorul pas este de a se extrage numărul corect al porilor din imaginea SEM. Pentru
a face acest lucru se aplică diferite procese morfologice, printre care eroziunea și dilatarea. Asupra imaginilor filtrate s-au aplicat o serie de elemente de structură pentru a determina porii. Un alt avantaj al operațiunilor morfologice este posibilitatea de a fi aplicate pe imagini în nuanțe de gri, așa cum sunt imaginile SEM. Metoda propusă folosește diferite elemente structurale de formă: linie aplicată, diamant, disc, octogon, dreptunghi, pătrat. Detectarea obiectelor este sensibilă la aceste elemente de structură și la dimensiunea acestora.
Următorul pas este binarizarea imaginii pentru a extrage obiectele. Pentru aceasta este necesară o valoare de prag. Din imaginile astfel transformate este creată o listă de obiecte detectate. Multe dintre obiecte se pot regăsi în toate imaginile generate, astfel că reunirea

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
27
tuturor acestor seturi va elimina elementele duplicate. Pentru fiecare obiect detectat, se păstrează diferite proprietăți: poziția centroidului, diametrul, suprafața (în pixeli), forma obiectelor.
IV.4.2 Analiza porozității A. Clasificarea folosind modelul Gaussian
Pentru imaginea i cu iO obiecte s-au calculat valoarea medie pentru suprafețe și deviația standard. Au fost luate în considerare trei clase:
)mari (valori if 3,
medii) (valori , if 2,
)mici valori( if ,1
)(
k
k
k
o
o
o
k
A
A
A
oC , (IV.8)
unde C reprezintă clasa pentru obiectul ko , ],1[ Nk , N este numărul total de obiecte în imagine,
reprezintă media ariei tuturor obiectelor, este deviația standard, koA este aria obiectul
ik Oo . A fost utilizată o distribuție Gaussiană cu parametrii și ( R , 0 ).
Având în vedere corelația dintre dimensiunea porilor și distribuția lor în hidrogeluri cu proprietățile de difuzie dorite pentru o anumită aplicație, abordarea propusă pentru analiza imaginii oferă o alternativă avantajoasă pentru a determina cu o bună acuratețe porozitatea. În general, o probă de hidrogel cu dimensiuni și distribuții mai uniforme ale porilor va prezenta, de asemenea, proprietăți mai uniforme de transport al apei, datorită suprafeței mărite de difuzie.
B. Criteriul J În algoritmul de segmentare a imaginii JSEG, criteriul J este util pentru a caracteriza
gradul de distribuție a claselor de culoare. O distribuție mai uniformă a claselor de culoare corespunde unei valori mai mici a lui J . Dacă clasele sunt parțial suprapuse, J are o valoare mai mare (Wang, 2010; Lulio & colab., 2011). În acest studiu, inspirat de algoritmul JSEG, sunt asimilate aceste idei pentru a clasifica porii în funcție de mărimea lor și pentru a determina distribuția lor.
Pentru setul de obiecte (pori) iO detectate in imaginea 𝑖, se consideră m media tuturor
ariilor porilor. Presupunând că iO este clasificat în C clase a fost calculată și jmmedia fiecărei
clase, cu Cj ,1 . Se definesc:
2
i
k
kOo
oT mAS , (IV.12)
C
j ZojoW
jkk
mAS1
2
, (IV.13)
WS este variația totală a ariilor porilor aparținând aceleiași clase și TS reprezintă variația totală
pentru întreaga imagine. În acest context, valoarea lui J se calculează după cum urmează:
W
WT
S
SS
NJ
)(1 . (IV.14)
Pentru fiecare obiect Ci
k ZZZOo 21\ se calculează o valoare J . Obiectul ko
va fi atribuit clasei cu cea mai apropiată valoare medie a lui J . Astfel, J devine un criteriu care măsoară similitudinea elementelor unei clase.
Prin creșterea numărului de clase se obține o performanță mai bună deoarece porii sunt grupați în mai multe clase cu suprafețe similare.

Cap. IV Aplicații ale inteligenței artificiale în modelarea și automatizarea unor procese chimice
28
IV.4.3 Rezutate și discuții Deoarece înainte de clasificarea și analiza distribuției au fost eliminate elementele foarte
mici sau foarte mari, clasele care interesează sunt clasele cu un număr mai mare de obiecte (pori) și cu o variație mai mică. După cum se observă în Figura IV.28, obținută prin utilizarea modelului Gaussian, se poate considera că o distribuție a majorității porilor în clasa 1 sau 2 (pori mici sau medii) înseamnă o porozitate suficient de uniformă pentru ca proba de hidrogel să prezinte proprietăți bune de difuzie, adecvate pentru o eliberare controlată a medicamentului.
Algoritmul JSEG, pe lângă criteriul J utilizează și o valoare medie J , care este definit ca o metodă de măsurare a performanței de segmentare a imaginii și se calculează după cum urmează:
,1j
jj JNN
J (IV.15)
unde jN reprezintă numărul de obiecte din clasa j , jJ este o valoare J pentru aceeași clasă și
N reprezintă numărul total de obiecte din iO . Pentru diverse compoziții ale hidrogelurilor este necesară găsirea unei metode
automate de a distinge între distribuția uniformă a porilor, ceea ce duce la necesitatea găsirii
unei metode de cuantificare a acestei distribuții. Astfel, utilizând J se poate evalua calitatea și uniformitatea distribuției totale a porilor din fiecare imagine. Se preferă o valoare mai mică
pentru J întrucât aceasta indică o variație mai mică a porilor în acea imagine. Totodată valoarea
lui J va putea ajuta la compararea imaginilor între ele și la stabilirea celei mai utile compoziții chimice pentru hidrogeluri cu scopul de a fi utilizate în aplicații specifice. În Tabelul IV.11 sunt
afișate valorile J corespunzătoare unora dintre imaginile SEM analizate (Figura IV.30) atunci când au fost utilizate 10C clase.
Figura IV. 10 Imagini SEM pentru diferite probe de hidrogel PNIPAM/ALG
TABELUL IV.11 VALORILE J PENTRU IMAGINILE SEM ANALIZATE
Imagini Img1
(Fig.IV.30a) Img2
(Fig.IV.30b) Img3
(Fig.IV.30c) Img4
(Fig.IV.30d)
J 6.76E-04 10.46E-04 1.62E-04 0.959E-04
Ținând cont de valorile J dn tabelul IV.11 și analizând imaginile SEM corespunzătoare ilustrate în Figura IV.20, se poate concluziona că Img 4 (Figura IV.30d), cu valoarea cea mai mică
pentru J are cea mai bună distribuție a porilor.
a b
c d

29
Capitolul V Aplicații ale inteligenței artificiale în analiza datelor bazate pe semnale biologice
V.1 Evaluarea memoriei pe termen scurt pe baza încărcării cognitive folosind semnale EEG
V.1.1 Paradigmele încărcării cognitive Aplicate începând de la nivelul grădiniței, până la mediul academic universitar, noile
abordări ale actului educațional, la fel ca și metodele tradiționale necesită instrumente avansate de identificare a rezultatelor procesului de învățare. S.Martin relizează o analiză vastă în acest domeniu (Martin, 2014) și subliniază importanța unui model teoretic pentru învățare dar și importanța conceptului de teorie a încărcării cognitive (engl. Cognitive Load Theory - CLT). Dezvoltat de Sweller in 1980, CLT urmărește configurarea unor instrucțiuni de proiectare educațională bazate pe modelul arhitecturii cognitive umane care pleacă de la premiza că există o memorie de lucru de dimensiune limitată (WM) și o memorie pe termen lung de dimensiune nelimitată cu ajutorul căreia subiecții rețin scheme cognitive. Sweller a dezvoltat teoria care analizează schemele (în forma unor combinații de elemente) ca fiind structuri cognitive ce conturează baza de cunoștințe a unui individ și îi permit acestuia să perceapă, să gândească și să rezolve probleme (Sweller, 1994).
Dintr-o perspectivă pragmatică, CLT are un impact în proiectarea efectivă a materialelor educaționale care mențin un nivel minim de încărcare cognitivă pentru subiectul uman în timpul procesului de învățare (Cîmpanu & colab., 2108). CLT urmărește identificarea tehnicilor de reducere a încărcării memoriei de lucru pentru a simplifica schimbările în cadrul memoriei pe termen lung asociate schemei de achiziție.
O întrebare naturală este „În ce circumstanțe și cu ce instrumente poate fi măsurată încărcarea cognitivă într-o manieră justificată și serioasă?” (Martin, 2014). Mai mult decât atât, spre deosebire de evaluările subiective realizate de către profesori, de chestionarele completate de studenți, dar și de evaluările psihologice, EEG-ul reprezintă cea mai valoroasă și mai fundamentată metodă de evaluare a încărcării cognitive și a memoriei de lucru. Este binecunoscut că lobul frontal al creierului este asociat cu memoria pe termen scurt și ne oferă posibilitatea de a ne concentra atenția în funcție de anumiți stimuli. S-a demonstrat că lobii frontali și parietali asigură de asemenea funcțiile cognitive de nivel înalt cum sunt raționamentul și luarea de decizii. Un interes al autorului a fost acela de a verifica compatibilitatea și posibilitatea utilizării cu succes a dispozitivlor de achiziție a semnalelor de tip Eeg ce au un cost redus față de cele profesioniste în încercarea de a evalua încărcarea cognitivă a memoriei de lucru.
V.1.2 Paradigma n-back. Memoria de lucru și încărcarea cognitivă Cea mai cunoscută metodă utilizată pentru a investiga încărcarea memoriei de lucru o
reprezintă testele cognitive de tip n-back, exercițiu de memorie introdus de Wayne Kirchner. Pe parcursul unui astfel de test, participantul trebuie să ia câte o decizie pentru fiecare probă specificând dacă elementul/șablonul curent a mai fost prezentat sau nu cu n etape înainte. De obicei, valoarea lui 𝑛 variază într 1 și 3 în sensul creșterii nivelului de dificultate pentru a manipula atât cererea de spațiu de memorie pentru stocare, dar și complexitatea operațiilor efectuate pentru

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
30
actualizarea informațiilor stocate (Rac-Lubashevsky & colab., 2016). O altă metodă de a identifica nivelele de încărcare ale memoriei de lucru o reprezintă rezolvarea unor operații aritmetice simple (de tip sumă sau produs). Bineînteles, capacitatea memoriei de lucru este puternic influențată de IQ-ul unui individ dar și de capacitatea aceastuia de a-și controla nivelul de concentrare.
V.1.3 Achiziția datelor EEG Achiziția datelor EEG a fost realizată pe un eșantion compus din 20 de studenți în cadrul
studiilor de licență cu capacitate intelectuală similară. Toate experimentele realizate s-au desfășurat conform paradigmei testului n-back. Fiecare subiect a trebuit să recunoască anumite imagini sau fragmente de text afișate pe ecran cu 1, 2 sau 3 etape înainte. Secvența de tipare a fost generată în mod aleator. Toate aceste teste au fost precedate și finalizate cu o etapă de repaus cu durată similară cu a testului n-back. Pe parcursul etapei de repaus, subiectul a trebuit să stea relaxat, cu ochii închiși și să nu se gândească la nimic. Câteva calcule aritmetice simple au fost efectuate pentru a compara nivelul de încărcare cognitivă obținut cu cel înregistrat în cazul testelor de tip n-back.
Sistemul principal de achiziție constă dintr-un amplificator Vamp 16ch și o cască EasyCap de la Brain Products. Rata de eșantionare a acestui dispozitiv de achiziție EEG este de 512Hz. Electrozii utilizați (F7, F3, Fp1, Fp2, F4, F8,T8, T7, Fz, P8, P4, Pz, P3 și P7) au fost plasați conform Sistemului Internațional 10-20.
O parte din experimente au fost realizate cu ajutorul căștii wireless Emotiv Epoc+ de la EMOTIV. Acest sistem de achiziție de putere scăzută implică de asemenea și un număr redus de electrozi (P4, Pz și P3 lipsind din configurația precedentă), dar are avantajul de a fi ușor de folosit într-un mediu educațional. Pentru achiziția și preprocesarea semnalelor EEG a fost utilizată aplicația OpenVibe. Undele cerebrale achiziționate au fost preprocesate prin filtrare trece-bandă pentru gamele de frevențe permise de cele două dispozitive EEG (0.5-100Hz) și prin filtrare trece-bandă pentru extragerea benzilor de frecvență (Theta, Alpha, Beta și Gamma). Artefacte cum ar fi clipirea, mișcări ale mușchilor sau saturarea amplificatorului au fost eliminate cu ajutorul filtrelor Savitzki-Golay pentru netezire. Filtre Notch au fost aplicate pentru a elimina zgomotul de rețea (50Hz).
V.1.4 Analiza și clasificarea datelor Setul de date astfel achiziționat și preprocesat a fost structurat sub forma 𝐷 = [𝑋, 𝑌],
𝐷𝑁×(𝑀+1). Baza de date 𝐷 cuprinde atributele înregistrate în timpul testelor 𝑋𝑁×𝑀 și clasele asociate
𝑌𝑁×1. Având la dispoziție aceste informații și clasele cu care se pot asocia, scopul experimentului a fost de a dezvolta un model sau indicator capabil să identifice clasa asociată unui anumit semnal EEG. Pentru aceasta, au fost evaluați doi clasificatori mașini cu vectori suport (SVM) și păduri de arbori de decizie generați aleatori (RF). Pe lângă acești doi clasificatori au mai fost calculați și câțiva indicatori statistici.
Toate experimentele au fost realizate pe două seturi de date, înregistrate cu ajutorul celor două dispozitive de achiziție a semnalelor EEG: setul Brain Products (BP) și setul Emotiv Epoc+ (EM). În cadrul primului set în 𝑋 regăsim 𝑁 = 77440 înregistrări pentru 𝑀 = 12 atribute numerice extrase pentru benzile Alpha, Beta și Gamma:
𝑥𝐵𝑃 = {𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛼𝑇8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8 , 𝛽𝑇8 , 𝛾𝐹3 , 𝛾𝐹7 , 𝛾𝐹8 , 𝛾𝑇8}, (V.1)
corespunzătoare celor patru nivele de încărcare cognitive și anume: stare de repaus, n-back-1, n-back-2 și n-back-3, codificate cu valori de la 0 la 3 în Y.
În cazul setului de date EM, matricea X este compusă din 𝑁𝐸𝑀 = 32450 înregistrări pentru 𝑀 = 12 atribute numerice extrase pentru benzile Alpha și Beta:
𝑥𝐸𝑀 = {𝛼𝐴𝐹3 , 𝛼𝐴𝐹4 , 𝛼𝐹3 , 𝛼𝐹4 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛽𝐴𝐹3 , 𝛽𝐴𝐹4 , 𝛽𝐹3 , 𝛽𝐹4 , 𝛽𝐹8 , 𝛽𝑇8}, (V.2)

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
31
asociate spre trei nivele de încărcare cognitivă: repaus, n-back-2 și n-back-3, prin intermediul valorilor 0, 2 și 3 în 𝑌. Valorile nedefinite ale atributelor în cadrul unui eșantion sunt înlocuite cu 0. Setările experimentale referitoare la selecția atributelor sunt prezentate în Tabelul V.1.
TABELUL V.1. SELECȚIA ATRIBUTELOR PENTRU EXPERIMENTE
Attribute Settings
Inputs Classes Attributes
Bra
in
Pro
du
cts 𝐴𝑆1 12 4 𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛼𝑇8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8 , 𝛽𝑇8 , 𝛾𝐹3 , 𝛾𝐹7 , 𝛾𝐹8 , 𝛾𝑇8
𝐴𝑆2 8 4 𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛼𝑇8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8 , 𝛽𝑇8
𝐴𝑆3 9 4 𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8 , 𝛾𝐹3 , 𝛾𝐹7 , 𝛾𝐹8
𝐴𝑆4 6 4 𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛼𝑇8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8 , 𝛽𝑇8
Emo
tive
EP
OC
𝐴𝑆5 12 3 𝛼𝐴𝐹3 , 𝛼𝐴𝐹4 , 𝛼𝐹3 , 𝛼𝐹4 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛽𝐴𝐹3 , 𝛽𝐴𝐹4 , 𝛽𝐹3 , 𝛽𝐹4 , 𝛽𝐹8 , 𝛽𝑇8
𝐴𝑆6 6 3 𝛼𝐹3 , 𝛼𝐹7 , 𝛼𝐹8 , 𝛽𝐹3 , 𝛽𝐹7 , 𝛽𝐹8
V.1.5 Indicatori pentru măsurarea încărcării cognitive Deoarece datele EEG înregistrate la o rată de eșantionare 𝑓𝑠 = 512𝐻𝑧, segmentul EEG cu
lungimea de o secundă va conține 𝑛𝑠 = 512 înregistrări 𝑋𝑠 = {𝑥𝑠𝑗|𝑗 = 1, 𝑛𝑠̅̅ ̅̅ ̅̅ }. În acest demers, au
fost comparate valorile medii (AVG), rădăcinii medii pătratice (RMS) și cros-corelația (CCR) pentru fiecare caz specificat în Tabelul V.1. Acești indicatori au fost calculați astfel:
𝐴𝑉𝐺 =1
𝑛𝑠∑ 𝑥𝑠𝑗
𝑛𝑠
𝑗=1, (V.4)
𝑅𝑀𝑆 = √1
𝑛𝑠∑ 𝑥𝑠𝑗
2𝑛𝑠
𝑗=1 , (V.5)
𝐶𝐶𝑅 = ∑ 𝑥𝑠[𝑝] ∙ 𝑟𝑒𝑠𝑡[𝑛𝑠 + 𝑝]∞
𝑝=−∞, (V.6)
unde rest reprezintă inactivitatea medie înregistrată și folsită ca reper pentru calculul indicatorului CCR în ecuația (V.6).
V.1.6 Rezultate experimentale Indicatorii statistici prezentați anterior au fost calculați pentru segmente EEG cu lungimea
de o secundă. Performanțele fiecărui criteriu au fost examinate pentru diferite unde EEG (Alpha, Beta și Gamma pentru setul BP; și doar Alpha și Beta pentru setul de date EM) pentru diferite canale conform setărilor indicate în Tabelul V.1. În urma constatărilor experimentale s-a remarcat că pentru canalele de achiziție localizate frontal F3, F7, F8 sensibilitatea relativ la nivelul de încărcarea cognitivă este ridicată, spre deosebire de electrodul poziționat pe lobul temporal T8.
Atributele de tip Gamma oferă informații valoroase pentru procesul de clasificare al activităților de tip n-back. Undele Gamma sunt responsabile cu formarea ideilor, cu limbajul, cu procesarea informațiilor în memorie, dar și cu diferite tipuri de învățare. Valoarea medie AVG calculată pentru semnalele EEG indică trei nivele diferite pentru dificultatea asociată activităților comparate, și anume n-back-1, n-back-2 și n-back-3. Fiecare activitate a fost divizată în ferestre de lungime 𝑇 = 1 secundă fără a se suprapune, rezultând 𝑛𝑠 = 20 de segmente. Simultan cu creșterea nivelului de dificultate al activității, valoarea medie a semnalului EEG tinde să crească, permițând

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
32
distingerea clară a fiecărui test de tip n-back. În cazul informațiilor din setul EM, media valorilor semnalelor scade cu creșterea nivelului de dificultate.
Clasificatorii multi-clasă RF și SVM au fost antrenați și testați. Numărul atributelor implicate
pentru fiecare clasificator au variat conform listelor incluse în Tabelul V.1. Pentru toate aceste
scenarii, ambii clasificatori au fost antrenați utilizând același set de eșantioane generate în mod
aleator, în timp ce testarea a fost efectuată pe seturile complete. Cantitatea de informații utilizată
pentru antrenare a variat de la 10% la 20%.
Pentru o selecție optimală a atributelor semnalelor EEG, modelele RF și SVM și-au
demonstrat eficiența, fiind capabili să obțină o eroare de clasificare de aproape 0% atât pentru
antrenare cât și pentru testare. În situația în care atributele Gamma sunt ignorate în etapa de
antrenare, acuratețea clasificării va fi vizibil afectată. Clasificatorul RF se remarcă față de SVM ca și
performanțe.
Pentru scenariile experimentale propuse s-au înregistrat valorile medii ale ratei de eroare
și a ariilor de sub curba pentru ambii clasificatori pe parcursul a cinci rulări distincte pentru aceleași
date de intrare. Indicatorul AUC reprezintă probabilitatea ca un eveniment pozitiv să fie clasificat ca
fiind pozitiv. AUC a fost ales pentru a evalua performanța clasificatorilor. Pentru modelul ideal, AUC
are valoarea 1, însă un model având AUC mai mare de 0.9 reflectă acuratețea algoritmului. Pentru
algoritmul SVM valorile indicatorului AUC înregistrate s-au situat în intervalul [0.997; 1], în timp ce
pentru RF valoarea sa a fost 1 pentru toate cazurile de test.
V.2 Analiza performanțelor dispozitivelor de achiziție EEG
Folosind aceleași proceduri, date și notații ca cele explicate în secțiunile V.1.2, V.1.3 și V.1.4, doi algoritmi de grupare supervizată au fost antrenați și testați conform scenariilor notate cu 𝑅𝐹𝑖 și 𝑆𝑉𝑀𝑖. Numărul de trăsături utilizate de fiecare algoritm variază conform Tabelului V.2. Pentru toate aceste scenarii, ambii algoritmi au fost antrenați pe același set de date și testați pe întregul set achiziționat. Scenariile de test utilizate în experimente sunt indicate în Tabelul V.3. Dimensiunea setului de antrenare variază între 10% și 30% din dimensiunea întregului set de date (Cîmpanu & colab., 2017a).
Primul set de experimente urmărește evidențierea importanței și corelației dintre atributele implicate în procedura de clasificare. Fiecare clasificator este analizat în conformitate cu performanțele obținute, în raport cu eroarea de clasificare sau timpul de execuție. Acestea au fost utilizate în testare pentru cazurile #1-#5, cu scopul de a identifica cel mai potrivit model. Un alt scenariu de test vizat măsurarea timpilor de execuție înregistrați atât pentru RF cât și pentru SVM pentru toate selecțiile prezentate (Cîmpanu & colab., 2017a).
TABELUL V.2. CONFIGURAREA ALGORITMILOR RF ȘI SVM PENTRU ANTRENARE
Metoda de clasificare Numărul de intrări
Atributele utilizate
𝑅𝐹1(𝛼, 𝛽, 𝛾) 12 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛼𝑇8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛽𝑇8, 𝛾𝐹3, 𝛾𝐹7, 𝛾𝐹8, 𝛾𝑇8
𝑅𝐹2(𝛼, 𝛽) 8 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛼𝑇8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛽𝑇8
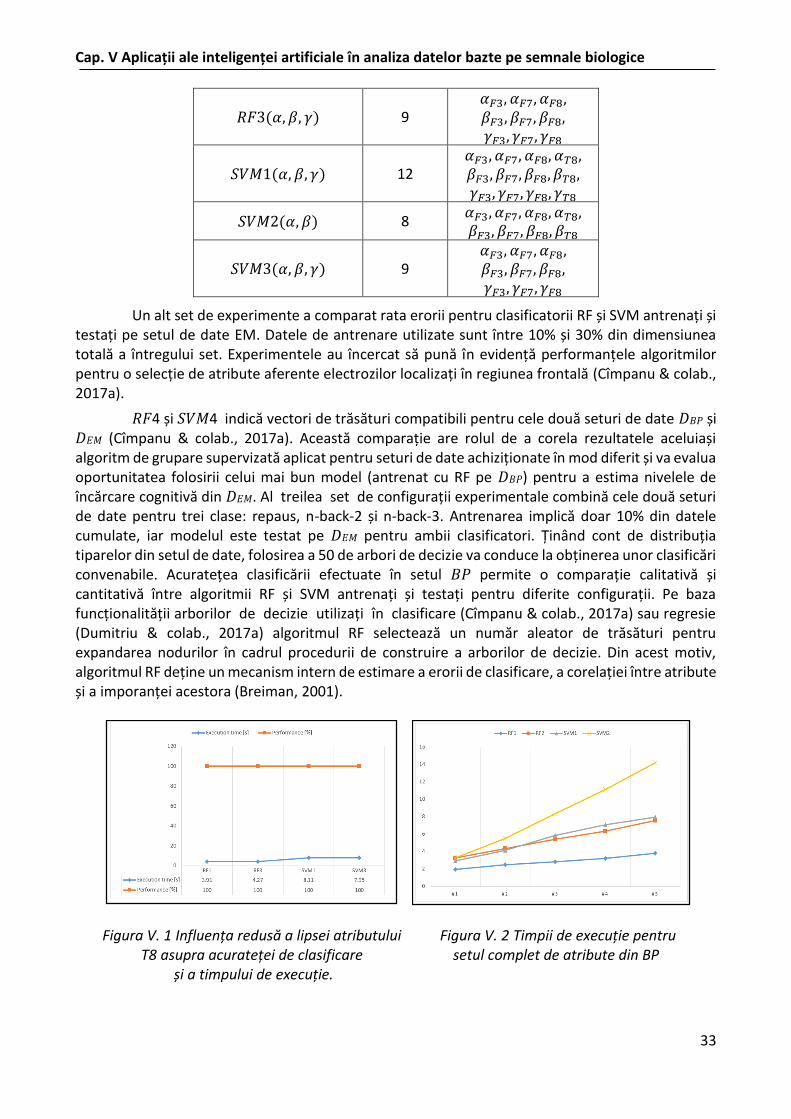
Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
33
𝑅𝐹3(𝛼, 𝛽, 𝛾) 9 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛾𝐹3, 𝛾𝐹7, 𝛾𝐹8
𝑆𝑉𝑀1(𝛼, 𝛽, 𝛾) 12 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛼𝑇8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛽𝑇8, 𝛾𝐹3, 𝛾𝐹7, 𝛾𝐹8, 𝛾𝑇8
𝑆𝑉𝑀2(𝛼, 𝛽) 8 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛼𝑇8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛽𝑇8
𝑆𝑉𝑀3(𝛼, 𝛽, 𝛾) 9 𝛼𝐹3, 𝛼𝐹7, 𝛼𝐹8, 𝛽𝐹3, 𝛽𝐹7, 𝛽𝐹8, 𝛾𝐹3, 𝛾𝐹7, 𝛾𝐹8
Un alt set de experimente a comparat rata erorii pentru clasificatorii RF și SVM antrenați și testați pe setul de date EM. Datele de antrenare utilizate sunt între 10% și 30% din dimensiunea totală a întregului set. Experimentele au încercat să pună în evidență performanțele algoritmilor pentru o selecție de atribute aferente electrozilor localizați în regiunea frontală (Cîmpanu & colab., 2017a).
𝑅𝐹4 și 𝑆𝑉𝑀4 indică vectori de trăsături compatibili pentru cele două seturi de date 𝐷𝐵𝑃 și 𝐷𝐸𝑀 (Cîmpanu & colab., 2017a). Această comparație are rolul de a corela rezultatele aceluiași algoritm de grupare supervizată aplicat pentru seturi de date achiziționate în mod diferit și va evalua oportunitatea folosirii celui mai bun model (antrenat cu RF pe 𝐷𝐵𝑃) pentru a estima nivelele de încărcare cognitivă din 𝐷𝐸𝑀. Al treilea set de configurații experimentale combină cele două seturi de date pentru trei clase: repaus, n-back-2 și n-back-3. Antrenarea implică doar 10% din datele cumulate, iar modelul este testat pe 𝐷𝐸𝑀 pentru ambii clasificatori. Ținând cont de distribuția tiparelor din setul de date, folosirea a 50 de arbori de decizie va conduce la obținerea unor clasificări convenabile. Acuratețea clasificării efectuate în setul 𝐵𝑃 permite o comparație calitativă și cantitativă între algoritmii RF și SVM antrenați și testați pentru diferite configurații. Pe baza funcționalității arborilor de decizie utilizați în clasificare (Cîmpanu & colab., 2017a) sau regresie (Dumitriu & colab., 2017a) algoritmul RF selectează un număr aleator de trăsături pentru expandarea nodurilor în cadrul procedurii de construire a arborilor de decizie. Din acest motiv, algoritmul RF deține un mecanism intern de estimare a erorii de clasificare, a corelației între atribute și a imporanței acestora (Breiman, 2001).
Figura V. 1 Influența redusă a lipsei atributului T8 asupra acurateței de clasificare
și a timpului de execuție.
Figura V. 2 Timpii de execuție pentru setul complet de atribute din BP
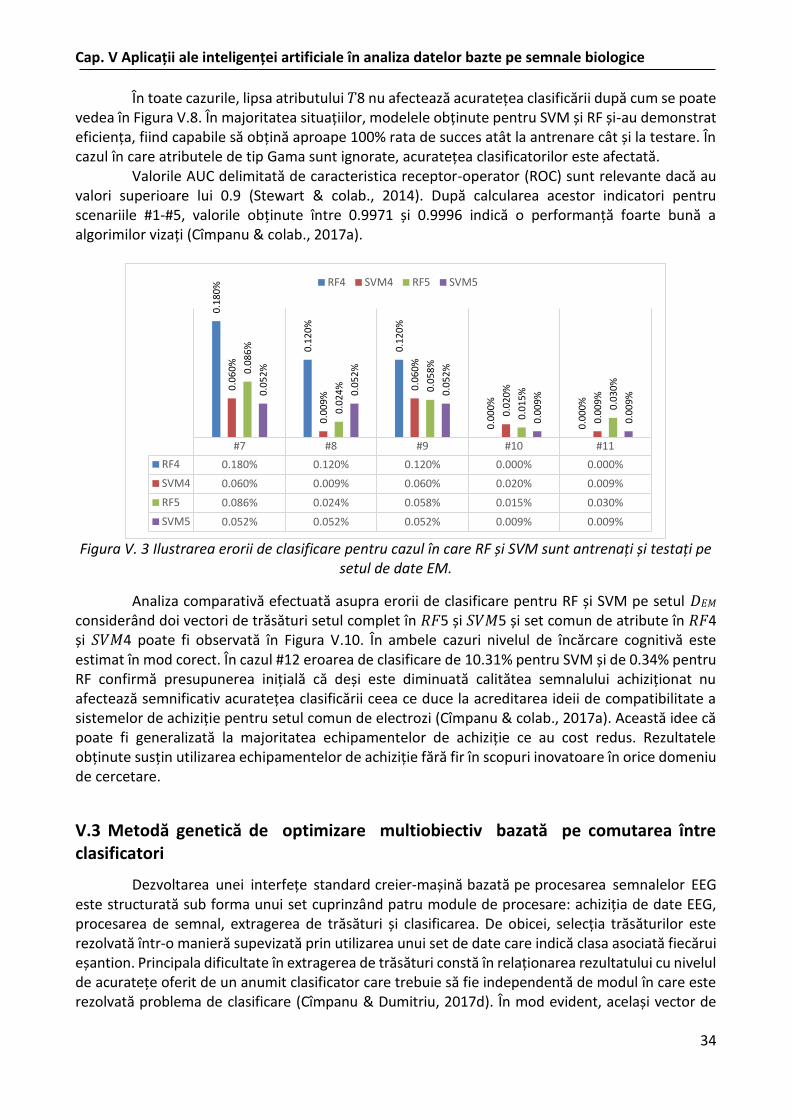
Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
34
În toate cazurile, lipsa atributului 𝑇8 nu afectează acuratețea clasificării după cum se poate vedea în Figura V.8. În majoritatea situațiilor, modelele obținute pentru SVM și RF și-au demonstrat eficiența, fiind capabile să obțină aproape 100% rata de succes atât la antrenare cât și la testare. În cazul în care atributele de tip Gama sunt ignorate, acuratețea clasificatorilor este afectată.
Valorile AUC delimitată de caracteristica receptor-operator (ROC) sunt relevante dacă au valori superioare lui 0.9 (Stewart & colab., 2014). După calcularea acestor indicatori pentru scenariile #1-#5, valorile obținute între 0.9971 și 0.9996 indică o performanță foarte bună a algorimilor vizați (Cîmpanu & colab., 2017a).
Figura V. 3 Ilustrarea erorii de clasificare pentru cazul în care RF și SVM sunt antrenați și testați pe
setul de date EM.
Analiza comparativă efectuată asupra erorii de clasificare pentru RF și SVM pe setul 𝐷𝐸𝑀 considerând doi vectori de trăsături setul complet în 𝑅𝐹5 și 𝑆𝑉𝑀5 și set comun de atribute în 𝑅𝐹4 și 𝑆𝑉𝑀4 poate fi observată în Figura V.10. În ambele cazuri nivelul de încărcare cognitivă este estimat în mod corect. În cazul #12 eroarea de clasificare de 10.31% pentru SVM și de 0.34% pentru RF confirmă presupunerea inițială că deși este diminuată calitătea semnalului achiziționat nu afectează semnificativ acuratețea clasificării ceea ce duce la acreditarea ideii de compatibilitate a sistemelor de achiziție pentru setul comun de electrozi (Cîmpanu & colab., 2017a). Această idee că poate fi generalizată la majoritatea echipamentelor de achiziție ce au cost redus. Rezultatele obținute susțin utilizarea echipamentelor de achiziție fără fir în scopuri inovatoare în orice domeniu de cercetare.
V.3 Metodă genetică de optimizare multiobiectiv bazată pe comutarea între clasificatori
Dezvoltarea unei interfețe standard creier-mașină bazată pe procesarea semnalelor EEG este structurată sub forma unui set cuprinzând patru module de procesare: achiziția de date EEG, procesarea de semnal, extragerea de trăsături și clasificarea. De obicei, selecția trăsăturilor este rezolvată într-o manieră supevizată prin utilizarea unui set de date care indică clasa asociată fiecărui eșantion. Principala dificultate în extragerea de trăsături constă în relaționarea rezultatului cu nivelul de acuratețe oferit de un anumit clasificator care trebuie să fie independentă de modul în care este rezolvată problema de clasificare (Cîmpanu & Dumitriu, 2017d). În mod evident, același vector de
#7 #8 #9 #10 #11
RF4 0.180% 0.120% 0.120% 0.000% 0.000%
SVM4 0.060% 0.009% 0.060% 0.020% 0.009%
RF5 0.086% 0.024% 0.058% 0.015% 0.030%
SVM5 0.052% 0.052% 0.052% 0.009% 0.009%
0.1
80
%
0.1
20
%
0.1
20
%
0.0
00
%
0.0
00
%
0.0
60
%
0.0
09
%
0.0
60
%
0.0
20
%
0.0
09
%
0.0
86
%
0.0
24
% 0.0
58
%
0.0
15
%
0.0
30
%
0.0
52
%
0.0
52
%
0.0
52
%
0.0
09
%
0.0
09
%
RF4 SVM4 RF5 SVM5

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
35
atribute poate genera performanțe diferite de clasificare când se utilizează clasificatori diferiți. Extinderea analizei pentru toate combinațiile posibile de atribute, este dificil de efectuat din
punct de vedere computațional atunci când se utilizează un număr ridicat de atribute. Pentru cazul experimentelor implicate, dimnesiunea vectorului complet conține 56 de trăsături ceea ce înseamnă un spațiu de căutare de aproximativ 7.2∙1016 soluții posibile. Extragerea de trăsături presupune evaluarea calității fiecărui vector de trăsături prin desemnarea unui clasificator care să opereze pe subsetul de atribute selecționate de vectorul respectiv. Gradul de acuratețe obținut de clasificator este asociat vectorului de trăsături, deși rezultatul este clar influențat de metoda de clasificare. În mod evident, evaluarea este una costisitoare din punct de vedere computațional și repetarea evaluărilor pentru clasificatori diferiți nu este o soluție rezonabilă.
O soluție propusă în acest subcapitol prezintă un algoritm genetic cu comutații efectuate între clasificatori cu scopul îmbunătățirii relevanței evaluărilor în procedura de extragere de trăsături. Algoritmul genetic comută periodic între RF și SVM. La fiecare generație, soluțiile sunt verificate cu ajutorul unui singur clasificator, fără a crește semnificativ timpul de execuție al procedurii de extragere de trăsături. O astfel de verificarea dublă permite încurajarea soluțiilor care asigură rezultatele cele mai bune conform ambilor clasificatori, reducând elementele specifice introduse de fiecare dintre aceștia.
V.3.1 Achiziția și preprocesarea setului de date Un grup format din 5 studenți voluntari, având performanțe cognitive similare au fost
implicați în teste de încărcare a memoriei de lucrufolosind paradigma testelor de memorie de tip n-back (n=2, 3) însoțite de perioade de repaus total. Testele de memorie vizuală de tip n-back reprezintă o măsură standard eficientă de evaluare a performanțelor memoriei de lucru. Durata unei sesiuni de înregistrare a semnalelor EEG a fost de aproximativ 60 de minute, incluzând antrenarea, încercările și pauzele. Fiecare etapă a avut o durată similară. Din datele înregistrate au fost menținute doar înregistrările încercărilor reușite (încercările cu rată de succes peste 85%), celelalte fiind eliminate din setul de antrenare sub pretextul inconsistenței informațiilor oferite (Cîmpanu & colab., 2017b). Achiziția datelor a fost realizată cu ajutorul unei căști de tip EasyCap cu electrozi pasivi umezi conectați la un amplificator Vamp 16ch de la Brain Products. Datele au fost achiziționate cu o rată de eșantionare de 512Hz, de la 14 electrozi și anume: FP1, FP2, F3, F4, F7, F8, P3, P4, P7, P8, C3, C4, O1 și O2, amplasaţi conform sistemului internațional 10-20.
OpenVibe a fost utilizată atât pentru etapa de achiziție, cât și pentru etapa de preprocesare a datelor EEG. Semnalele EEG achiziționate au fost preprocesate cu filtre trece-bandă (0.5-100Hz). Filtre de tip Notch sunt utilizate pentru eliminarea interferențelor induse de frecvența rețelei (50Hz). Principalele benzi de frecvență sunt extrase cu ajutorul filtrelor trece-bandă conform gamei de frecvență în care sunt definite (delta 0-4Hz, theta 4-7Hz, alfa 8-15Hz, beta 16-31Hz și gama 32-100Hz). În final filtrele Savitzky-Golay pentru netezire sunt folosite pentru eliminarea artefactelor datorate clipirilor sau mișcărilor musculaturii feței. Transformata Fourier FFT a fost aplicată pentru a transforma datele achiziționate din domeniul timp în domeniul frecvență.
Datele sunt organizate într-o bază 𝐷 = [𝑋, 𝑌], unde 𝐷𝑁×(𝑀+1) cuprinde atributele datelor EEG înregistrate 𝑋𝑁×𝑀 pentru 𝑀 = 56 atribute, însoțite de etichetarea claselor din care fac parte în vectorul coloană 𝑌𝑁×1. Aceste clase indică tipul de activitate cognitivă: repaus, 2-back și 3-back prin intermediul atributelor semnalului EEG preluate pe 14 canale și divizat în 4 benzi de frecvență – alfa, beta, gama și theta. În acest studiu s-au folosit 𝑁 = 73020 date. Toate procedurile de antrenare au fost efectuate pe un set de 20% din datele achiziționate reprezenând 14604 de informații selectate în mod aleator. Validarea s-a fost efectuată pe întregul set de date.

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
36
V.3.2 Algoritm genetic cu comutare pentru selecția de trăsături După cum s-a menționat deja, problema de optimizare este rezolvată cu ajutorul
algoritmilor genetici. Fiecare soluție candidat indică prezența (𝑓 = 1) sau absența (𝑓 = 0) unui anumit atribut prin intermediul unui cromozom binar de lungime 𝑀 = 56 de forma:
],..,,..,,..,,..[14114114141 ffffffffx . (V.7)
În relația (V.7), 𝛼, 𝛽, 𝛾 și 𝜃 ilustrează undele Alfa, Beta, Gama și Theta ale semnalului achiziționat pe cele 14 canale și anume: FP1, F7, F3, C3, P3, P7, O1, O2, FP2, F8, F4, C4, P4 și P8 (Cîmpanu & colab., 2017b).
Algoritmul V.1 Algoritm genetic de optimizare bazat pe comutare
Generează aleatoriu populația inițială conținând 𝐼𝑁𝐷 indivizi codificați conform (V.7) Selectează tipul de clasificator (RF sau SVM) pentru maxim 𝐺𝐸𝑁 generații execută:
La fiecare 𝐺𝐸𝑁𝑐 generații comută între tipurile de clasificatori. Calculează valorile obiectiv ale soluțiilor în conformitate cu clasificatorul adoptat și
asociază valorile fitness prin intermediul rangurilor soluțiilor. Selectează 𝐼𝑁𝐷/2 indivizi pentru recombinare cu selecție stohastică universală. Generează 𝐼𝑁𝐷/2 copii folosind încrucișarea discretă, cu probabilitate 𝑃𝑐 = 0.7. Aplică mici variații asupra materialului genetic al copiilor cu ajutorul mutațiilor cu
probailitatea 1.0mP
Calculează valorile fitness ale copiilor. Selectează 𝐼𝑁𝐷/2 indivizi pentru recombinare cu selecție stohastică universală.
Sfârșit pentru
Selecția trăsăturilor relevante este efectuată în concordanță cu minimizarea următoarelor funcții obiectiv:
100)(
)(
N
xCCSNxCERR , (V.8)
N
i ifxNSF1
)( , (V.9)
unde 𝑥 reprezintă o soluție candidat conform (V.7), 𝑁 este numărul total de date, 𝐶𝐸𝑅𝑅 indică eroarea de clasificare, iar 𝐶𝐶𝑆(𝑥) reprezintă numărul de tipare correct clasificate, iar 𝑁𝑆𝐹 contorizează numărul total de atribute implicate în procesul de clasificare.
Algoritmul genetic exclude gradual trăsăturile din 𝑥 prin minimizarea numărului de trăsături selectate 𝑁𝑆𝐹. Relevanța atributelor păstrate rezultă din minimizarea erorii de clasificare 𝐶𝐸𝑅𝑅. Valorile 𝐶𝐸𝑅𝑅 sunt calculate prin integrarea antrenării unui clasificator în procesul de evaluare al fiecărui cromozom. În continuare se va nota cu RFCERR eroarea de clasificare obținută de
clasificatorul RF și cu SVMCERR cea pentru clasificatorul SVM (Cîmpanu & colab., 2017b).
V.3.3 Rezultate experimentale Dubla verificare a acurateței de clasificare este realizată prin comutări periodice între
diferiți clasificatori. Implementarea mecanismului de comutare implică o simplă modificare a unui algoritm genetic standard. Este evident că acest mecanism de comutare este compatibil cu orice tip de clasificator și cu orice număr de clasificatori alternativi implicați. Soluțiile validate de toți clasificatorii folosiți vor avea asociate probabilități de selecție ridicate (Cîmpanu & colab., 2017b).
Schema propusă este compatibilă atât cu optimizări mono-obiectiv cât și cu optimizări multiobiectiv. Mecanismul de comutare poate fi exemplificat pentru diverse configurații ale unui

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
37
algoritm genetic aplicat pentru extragerea de trăsături datorită compatibilității existente. Procedura standard de asociere a rangurilor pentru abordările multiobiectiv prezentată în
acest studiu este NSGA-ul propus de Deb (MOO-NSGA). MOO-NSGA (Deb, 2011) este aplicat fără alte mecanisme de comutare. Variantele ulterioare de optimizare MOO-COM1 și MOO-COM2 includ mecanisme de comutare între cele două tipuri de clasificatori. Atunci când este aplicat pe seturi de date de dimensiune mare, descrise printr-un număr mare de atribute, MOO-COM1 poate să reducă atât numărul atributelor selectate cât și dependența de un anumit tip de clasificator mai eficient decat MOO-NSGA. Cea de-a doua variantă de asociere a rangurilor, exploatează faptul că mecanismul de comutare necesită reevaluarea tuturor soluțiilor pentru compatibilitatea la nivel de acuratețe de clasificare cu noul clasificator adoptat pentru generațiile în cadrul cărora este activat acest mecanism (Cîmpanu & colab., 2017b). Cât timp atât 𝐶𝐸𝑅𝑅𝑅𝐹 cât și 𝐶𝐸𝑅𝑅𝑆𝑉𝑀 sunt disponibile, valorile respective pot fi utilizate pentru o validare consistentă. Mai exact, în cadrul generațiilor în care are loc comutarea, rangurile sunt asignate în conformitate cu numărul de trăsături selectate 𝑁𝑆𝐹, 𝐶𝐸𝑅𝑅𝑅𝐹 și 𝐶𝐸𝑅𝑅𝑆𝑉𝑀.
V.4 Metodă evolutivă de selecție a atributelor EEG folosind extensii temporale
V.4.1 Selecția de trăsături din semnale EEG Majoritatea aplicațiilor bioinformatice se reduc la probleme de procesare de date constând
în clasificări supervizate sau nesupervizate în cadrul unor seturi de dimensiune foarte mare. Aproape toate aplicațiile din acest domeniu folosesc proceduri de selecție pentru eliminarea atributelor irelevante (Martin-Smith & colab., 2017).
Considerând dimensiunea spațiului subseturilor potențiale ce ar trebui explorat, utilizarea algoritmilor genetici este recomandată. Mai mult, aceștia pot gestiona o optimizare de tip multiobiectiv prin evaluarea rafinată a vectorilor de trăsături din mai multe perspective.
În acest subcapitol, selecția de trăsături este definită în raport cu minimizarea erorii de clasificare, dar și cu numărul de trăsături selectate. Cromozomii sunt construiți în concordanță cu o reprezentare care să permită extinderea setului de valori al trăsăturilor curente prin adăugarea valorilor anterioare ale acelorași trăsături, oferind așadar o imagine mai clară a dinamicii activităților mentale. De obicei, dinamica este caracterizată de atribute care indică anvelopa semnalului EEG pentru anumite forme de undă obținute după filtrarea semnalului. Din acest motiv, un singur vector de trăsături va cuprinde informații despre semnalul EEG din eșantioane consecutive. O descriere rafinată a semnalului EEG este oferită prin introducerea valorilor anterioare ale atributelor în setul curent, aceste variații oferind clasificatorului informații pe parcursul unei ferestre temporale extinse. Această expansiune aduce însă dezavantajul creșterii dimensiunii setului de trăsături potențiale dar și a spațiului de explorat. În acest context, se va utiliza o codificare compactată folosind valori întregi și se vor utiliza două tehnici care să conducă la o explorare rapidă și eficientă. În primul rând, structura classificatorului încorporat este crescută gradual. În al doilea rând, eroarea de clasificare este diminuată prin introducerea unei funcții obiectiv dinamice care să permită evaluarea complexității vectorului de trăsături selectate.
V.4.2 Achiziția datelor EEG Datele EEG au fost înregistrate conform unui scenariu standard care a constat în efectuarea
unui set de operații matematice de către 10 voluntari studenți în ciclul de licență – cinci băieți și cinci fete cu capacități de învățare similare. Examinatorul înaintează câte un item din setul compus din calcule aritmetice simple constând în adunări de numere din două cifre (math2+2) urmate de adunări de numere compuse din două și din trei cifre (math3+2). Aceste două tipuri de calcule

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
38
corespund la două nivele de încărcare cognitivă, similar modului cum sesiunile de relaxare totală (rest) corespund unui nivel scăzut de încărcare cognitivă.
Problemele au fost prezentate în mod secvențial fiecărui subiect de test care trebuie să rostească răspunsul cu voce tare. Fiecare experiment aritmetic este descompus într-o serie de 20 de calcule generate în mod aleator. Stimulii vizuali au fost proiectați în fața fiecărui subiect la o distanță de 60 cm și menținuți pe ecran pentru 40 de secunde. În acest interval, subiectul de test trebuia să citească, să evalueze și să dea un răspuns. Fiecare sesiune de încărcare cognitivă a cuprins perioade de antrenare, încercări și repaus a durat aproximativ 20 de minute. Pentru fiecare subiect de test au fost efectuate mai multe înregistrări. Toate încercările nereușite, dar și sesiunile în cadrul cărora subiectul de test și-a pierdut concentrarea au fost eliminate din setul final.
V.4.3 Preprocesarea datelor EEG și extragerea de trăsături Datele EEG au fost achiziționate în cadrul sesiunilor experimentale utilizând echipamentul
EasyCap cu electrozi umezi pasivi conectat la un amplificator V-amp cu 16 canale. Datele au fost achiziționate la o rată de eșantionare de 512Hz considerând 14 locații pe scalp după cum urmează:
{𝐹𝑃1, 𝐹𝑃2, 𝐹3, 𝐹4, 𝐹7, 𝐹8, 𝑃3, 𝑃4, 𝑃7, 𝑃8, 𝐶3, 𝐶4, 𝑂1, 𝑂2}, (V.10) localizate conform Sistemului Internațional 10-20. Atât pentru achiziție, cât și pentru etapa de preprocesare a fost utilizată aplicația OpenVibe. Setul original de atribute a fost extins prin adăugarea valorilor de la momentele anterioare, iar procedura de extragere de trăsături a fost rezolvată folosind MATLAB.
Toate înregistrările au fost preprocesate prin filtrare trece bandă între 0.5 Hz și 100 Hz. Zgomotul indus de frecvența rețelei în jurul frecvenței de 50 Hz a fost eliminat folosind un filtru de tip Notch. Formele de undă asociate cu principalele benzi de frecvență au fost extrase folosind filtre trece-bandă. Amplificările scurte de saturație, clipitul sau mișcările musculare au fost eliminate folosind un filtru de netezire Savitzky-Golay. Primele 10%, dar și ultimele 10% eșantioane au fost eliminate pentru a evita problemele de sincronizare. Undele de tip delta (0.5 Hz; 4 Hz] sunt eliminate. O trăsătură este definită ca anvelopa fiecarei forme de undă extrasă din semnalul aferent unui electrod. Datele achiziționate și preprocesate sunt organizate într-o tabelă 𝐷 = [𝑋, 𝑌], unde 𝐷𝑁×(𝑀+1) conține valori reale asociate celor 𝑀 atribute 𝑋𝑁×𝑀, respectiv clasei aferente 𝑌𝑁×1.
Valorile din 𝑌 ilustrează nivelul de încărcare cognitivă și anume: repaus, math2+2 sau math3+2.
V.4.4 Metodă evolutivă pentru selecția de trăsături Metoda este proiectată sub forma unei selecții de trăsături de tip global bazată pe
clasificatori de tip RF. Acest tip de clasificator a fost ales pe baza unor investigații anterioare privind capabilitatea unei selecții de clasificatori precum AdaBoost, kNN, NB, RF, SVM, etc. de a gestiona semnale de tip EEG cu acuratețe sporită și într-un interval de timp rezonabil (Cîmpanu & colab., 2018a). Cercetările anterioare au arătat că minimizarea individuală a erorii de clasificare și a numărului de trăsături limitează capacitatea exploratorie a procedurii (Cîmpanu & colab., 2017b; Cîmpanu & colab., 2017c). Procedura de optimizare prezentată în cele ce urmează propune evitarea dezavantajului inerent al optimizărilor mono-obiectiv prin optimizarea concomitentă a erorii de clasificare și a numărului de atribute selectate. Schema generală a algoritmului este prezentată în (Algoritmul V. 2).
Optimizarea multiobiectiv este rezolvată utilizând un algoritm genetic cu codificare în mulțimea numerelor naturale. Mai exact, fiecare cromozom este obținut prin concatenarea a patru subșiruri de câte 14 gene corespunzând formelor de undă alfa, beta, gamma și theta filtrate de pe cele 14 locații anterior menționate. Codificarea adoptată este mai exact o codificare în baza 4 și are rolul de a indica prin intermediul alelelor dacă un atribut este selectat și dacă se folosesc valori

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
39
adiționale ale acestuia de la momente de timp anterioare. Un astfel de cromozom de lungime fixă este definit după cum urmează:
𝐶 = [𝑔1, 𝑔2, … , 𝑔𝑀], (V.11) unde 𝑔𝑖 cu 𝑖 = 1,𝑚̅̅ ̅̅ ̅̅ și 𝑀 = 56 este gena asociată trăsăturii 𝑖 din 𝐷. Decodificarea genei 𝑔𝑖 se face după cum urmează:
𝑔𝑖 =
{
0, 𝑒𝑙𝑖𝑚𝑖𝑛ă 𝑓(𝑘) 1, 𝑠𝑒𝑙𝑒𝑐𝑡𝑒𝑎𝑧ă 𝑓𝑖(𝑘) 2, 𝑠𝑒𝑙𝑒𝑐𝑡𝑒𝑎𝑧ă 𝑓𝑖(𝑘)ș𝑖 𝑓𝑖(𝑘 − 1)
3, 𝑠𝑒𝑙𝑒𝑐𝑡𝑒𝑧ă 𝑓𝑖(𝑘), 𝑓𝑖(𝑘 − 1) ș𝑖 𝑓𝑖(𝑘 − 2)
, (V.12)
unde 𝑓𝑖(𝑘) indică valoarea atributului 𝑖 de la momentul de timp 𝑘 al sesiunii înregistrate. În cea de-a doua ecuație, 𝑓𝑖(𝑘) indică valoarea curentă a atributului 𝑖, în timp ce 𝑓𝑖(𝑘 − 1) și 𝑓𝑖(𝑘 − 2) indică valorile de la momentele de timp anterioare ale aceleiași trăsături.
Selectarea celor mai reprezentative trăsături EEG pentru identificarea nivelelor de încărcare cognitivă este realizată urmărind minimizarea următoarelor funcții obiectiv:
𝑀𝑅(𝐕) =𝑁 − 𝐶𝐶(𝐕)
𝑁, (V.13)
𝑁𝐹(𝐕) = [∑𝑔𝑖𝑃
𝑀
𝑖=1
], (V.14)
unde 𝐕 indică vectorul de trăsături selectate, 𝑁 este numărul de eșantioane disponibile, 𝐶𝐶(𝐕) indică numărul de eșantioane clasificate corect, [∎] indică partea întreagă a unui număr și 𝑃 ≥ 1 un parametru de tip întreg care indică nivelul de detaliu aplicat pentru al doilea obiectiv.
În cadrul procedurii de optimizare multiobiectiv, 𝑀𝑅 garantează selecția celor mai relevante trăsături, în timp ce 𝑁𝐹 asigură selecția unui număr redus de atribute. Procedura de optimizare multiobiectiv va trata diferit acești vectori de trăsături doar dacă valorile lor obiectiv pentru 𝑀𝑅 sunt distincte. Astfel, valori mari ale lui 𝑃 indică preferința pentru minimizarea lui 𝑀𝑅, în timp ce 𝑃 = 1 indică aprecierea în mod egal a celor două obiective.
Algoritmul V.2 Optimizare multiobiectiv folosită pentru selecția de trăsături
Generează aleatoriu o populație de 𝑁𝐼𝑁𝐷 indivizi conform relațiilor (V.11) și (V.12). Evaluează indivizii din populația inițială conform relațiilor (V.13) și (V.14). Se va aplica un clasificator de tip RF configurat cu 𝑁𝑇 arbori și antrenat pe 5% din datele din set. pentru 𝐺 generații execută:
- Asociază valorile fitness folosind NSGA; - Selectează 𝑁𝐼𝑁𝐷/2 indivizi pentru recombinare, prin intermediul selecției
stohastice universale; - Generează 𝑁𝐼𝑁𝐷/2 copii, aplicând operatorul de încrucișare discretă cu
probabilitate de 0.7, urmat de operatorul de murație aleatoare uniformă cu o probabilitate de 0.1;
- Calculează valorile fitness ale copiilor și inserează cei mai buni 𝑁𝐼𝑁𝐷/4 dintre ei în populație prin înlocuirea soluțiilor slab adaptate existente;
- Conform procedurii de selecție și generației curente, actualizează 𝑁𝑇, 𝑃 sau ambii parametri dacă este necesar;
- Dacă 𝑁𝑇 sau 𝑃 au fost actualizați, atunci reevaluează toți indivizii în conformitate cu relațiile (V.13) și (V.14) pentru nole valori ale lui 𝑁𝑇 și 𝑃.
sfârșit pentru Alege rezultatul algoritmului din centrul frontului Pareto non-dominat.

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
40
Pe parcursul procedurii evolutive, parametrul 𝑃 poate fi variat de asemenea. În cadrul soluției propuse, 𝑃 este inițializat cu o valoare suficient de mare și redus la fiecare 𝐺𝑃 generații cu o cantitate predefinită, notată 𝐷𝑃. Această reducere graduală a lui 𝑃 permite intensificarea explorării în vederea minimizării lui 𝑀𝑅 în cadrul primelor generații. După eliminarea soluțiilor cu rate mari ale erorii de clasificare, structura indivizilor capătă importanță sporită datorită diminuării valorii lui 𝑃. Utilizarea unor valori foarte mari pentru parametrul 𝑃 nu este recomandată, întrucât se poate observa că simplificarea vectorului de trăsături poate conduce la minimizarea lui 𝑀𝑅 atunci când cele două funcții obiectiv sunt slab conflictuale.
Evaluarea erorii de clasificare presupune antrenarea unui clasificator de tip RF pentru fiecare cromozom. Pentru aceasta, numărul de arbori 𝑁𝑇 din structura clasificatorului este configurat dinamic. Este avantajos să se înceapă de la valori reduse pentru 𝑁𝑇 care pot accelera evaluarea indivizilor din primele populații. Deoarece aceste populații sunt diversificate și pot conține multe soluții inutile, asocierea rangurilor este rezolvată pe baza valorile brute ale lui 𝑀𝑅. Pe parcursul buclei evolutive, 𝑁𝑇 este crescut gradual, cu o cantitate prestabilită 𝐷𝑁𝑇, o dată la 𝐺𝑁𝑇 generații pentru a spori relevanța evaluării lui 𝑀𝑅. Aceasta se traduce prin creșterea timpului de execuție necesar pentru (V.13), deși efortul suplimentar este cheltuit pentru a discrimina cei mai valoroși indivizi similari. Pentru reducerea riscului de a elimina vectori de trăsături folositori datorită proiectării inadecvate a clasificatorului, valorile inițiale ale lui 𝑁𝑇 nu trebuie să fie foarte mici.
V.5 Analiza tehnicilor de clasificare a emoțiilor
V.5.1 Interfaţa om - calculator Realizările existente în domeniul interacțiunii om-calculator (engl. Human Computer
Interface - HCI) încearcă să atingă o relație naturală între actorii implicați. Estimările automate și fiabile ale stărilor afective, în special din semnalele fiziologice, au primit o atenţie deosebită în ultimul deceniu. Din punct de vedere al măsurilor fiziologice, evaluarea emoțiilor beneficiază de senzații pure, nealterate în contrast cu măsurile faciale sau vocale care pot fi simulate. De aceea, în acest subcapitol sunt analizate diferite scenarii bazate pe măsuri de evaluare fiziologică pentru a estima starea afectivă a unei persoane. Analiza se efectuează pe datele obținute de la senzorii Eye-Tracker (ET), precum și cei obţinuţi pentru ritmul cardiac (HR) și activitatea electro-dermică (EDA), în experimente bazate pe stimuli vizuali. În acest scop, se face o comparație între metodele ce clasificare cu ajutorul algoritmilor AdaBoost (AB), KNN, analiza liniară discriminantă (LDA) și SVM, care examinează entropiile ca trăsături principale ale clasificării.
Spațiul emoțional de excitare a valenței 2D reprezintă un standard acceptat pe scară largă, conform căruia emoțiile sunt caracterizate prin intensitatea și nivelul de excitare a lor (Russell, 1980). Valenţa ilustrează plăcerea (variind de la negativ la pozitiv), iar excitația denotă nivelul de activare (variind de la scăzut / calm la înalt / interesant) (Jerritta & colab., 2011). Anumiți indicatori ai activării ANS folosiți în mod obișnuit sunt ritmul cardiac, tensiunea arterială, activitatea electro-dermală, rata respiratorie, electromiografia și temperatura (iMotions, 2018). Pe lângă aceste măsurători utilizate și în identificarea biometrică, informații semnificative pot fi furnizate de sistemele de urmărire a ochilor în ceea ce privește dimensiunea pupilei, clipirea sau mișcările oculare în cazul activării emoției sau gândirii (Loewenfeld, 1993).
Într-o abordare multimodală care implică măsurarea ET, EDA și HR, datele fiziologice brute sunt serii de timp cu caracteristici diferite. În acest studiu, entropiile domeniului de timp sunt utilizate ca atribute: entropia aproximativă (ApEn) și entropia eșantionului (SampEn). ApEn este o proprietate statistică folosită pentru a cuantifica complexitatea sau neregularitatea unui semnal și descrie rata de producere a informațiilor noi. SampEn prezentat în (Liang & colab., 2015) se bazează

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
41
pe ApEn, dar se deosebește de acesta, deoarece auto-potrivirile sunt eliminate și pot fi aplicate cu succes la seturile de date largi.
Mai jos sunt prezentate metodele de recunoașterea stării emoționale propuse, utilizând proceduri de clasificare bazate pe măsuri fiziologice. Evaluarea stării afective este analizată în diferite scenarii folosind entropiile domeniului de timp ca atribute și comparând performanțele AB, LDA, KNN și SVM.
V.5.2 Achiziţia şi preprocesarea datelor În această abordare multimodală, time stamp-ul UNIX înregistrat pentru fiecare semnal
brut de la orice senzor a fost utilizat pentru sincronizarea datelor ET, EDA și HR. Semnalele obținute au fost filtrate și netezite, iar apoi ApEn și SampEn calculate au fost utilizate ca şi trăsături pentru clasificare.
Stimulii utilizați pentru evaluarea excitării emoționale sunt selectați din International Affective Picture System (IAPS) furnizat de National Institute of Mental Health Center for Emotion and Attention de la Universitatea din Florida (CSEA, 2018). IAPS oferă accesul academic la seturi mari de stimuli vizuali utilizați în investigațiile experimentale HCI. Aceste imagini au asociate evaluări ale valenței și excitării, fiind capabile să genereze activarea emoțională - cum ar fi placerea, starea neutră sau nemulțumirea - asemănătoare condițiilor reale (Silva, 2011).
Un grup de 10 voluntari (compus din 6 femei și 4 bărbați) a fost implicat în experimentele de activare emoțională pe baza stimulilor vizuali. Fiecare sesiune experimentală a implicat prezentarea a 20 de stimuli vizuali (imagini) distribuite în câmpul emoțional. Toate cele 166 de imagini din baza de date IAPS au fost selectate pentru a fi plăcute sau neplăcute pentru a crea emoții și neutre pentru starea de calm. Cu toate acestea, semnalele fiziologice și datele obținute de către ET reflectă numai intensitatea emoțională, nu valența (negativă sau pozitivă).
A. Urmărirea mişcării ochilor Dispozitivul EyeTribe 101 Eye Tracker a fost folosit pentru toate experimentele ET. Acest
dispozitiv de urmărire a ochilor la distanță are o precizie de 0,4° și obține informații la o rată de eșantionare de 30 Hz. Informațiile ET sunt colectate de la dispozitivul de urmărire a ochilor folosind o aplicație C# care integrează EyeTribe SDK și generează informații precum timestamp, dimensiunea pupilei pentru ambii ochi, coordonatele cardinale și coordonatele medii ale punctelor fixate de ochiul drept și stâng, precum şi dacă poziţia a fost fixată mai mult timp. Deoarece mărimea pupilei ochiului este sensibilă la luminozitatea și poziția utilizatorului, a fost aplicată o linearizare a mărimii puilei (procent din diferența dintre valorile cele mai mari și cele mai mici). În principal, variația mărimii pupilei la stimulii video este folosită ca măsură a stării emoționale. Pentru setul de date ET având în vedere ambii ochi, mărimea pupilei, SampEn și ApEn au fost calculate ca trăsături pentru clasificare. Au fost extrase două atribute suplimentare pentru îmbunătăţirea acurateței clasificării, și anume lungimea traseului parcurs de privire asupra imaginii și numărul de puncte fixate de ochi.
B. Raspunsul galvanic al pielii Activitatea electro-dermală (EDA), denumită și conductanța pielii sau răspunsul galvanic al
pielii (engl. Galvanic Skin Response - GSR), este o măsură esențială a modului în care stimulul emoțional sau sarcina cognitivă acționează sistemul nervos autonom, EDA reflectând conductivitatea electrică a pielii în legătură cu transpirația emoțională. Cu toate acestea, ca și alți parametri fiziologici, EDA măsoară doar nivelul de excitare, dar nu poate detecta valența care poate fi fie pozitivă, fie negativă. În acest studiu, senzorul Shimmer3 GSR + Unit (Shimmer, 2018) a fost utilizat pentru a obține date despre ritmul cardiac și activitatea electrodermală cu o rată de 16Hz. Instrumentul software asociat achiziţionează datele brute împreună cu momentul de achiziție.

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
42
Ulterior aceste date au fost sincronizate cu evenimentele sau cu alte înregistrări. Indicii de entropie a domeniului de timp au fost calculați pentru fiecare imagine în toate scenariile de testare.
C. Ritmul cardiac Având în vedere că ritmul cardiac reflectă efortul fizic sau cognitiv al unui subiect, precum
și starea emoției (iMotions, 2018), în acest studiu au fost utilizate semnalele HR achiziționate cu senzorul Shimmer3 GSR + utilizat de asemenea pentru EDA. Variația frecvenței cardiace (HRV) este o metodă de evaluare a efectelor stresului sau efortului unei persoane, măsurată ca un decalaj de timp între bătăile inimii. În seria de timp dată de perioadele ritmului cardiac, diferenţele succesive a rădăcinii pătratice (engl. Root Mean Squared Successive Difference - RMSSD) reprezintă o măsură în domeniul timp a variabilității perioadei cardiace, fiind adecvată pentru descrierea înregistrărilor pe perioade scurte, cum sunt cele utilizate în aceste experimente.
V.5.3 Analiza şi clasificarea datelor Analiza efectuată privește evaluarea performanțelor clasificatorilor: AdaBoost, KNN, LDA
și SVM în timp ce se încearcă să se distingă între stările emoționale plăcute, neplăcute și neutre. Deoarece agenți cum ar fi luminozitatea mediului, localizarea subiectului și oboseala sunt factori vitali care influențează reacția ochiului, pentru a îmbunătăți acuratețea clasificării, au fost utilizate și alte atribute în afară de valorile entropiei. Prin urmare, procedura de clasificare din setul de date ET utilizează atribute ca SampEn și ApEn calculate atât pentru pozițiile ochilor, cât și pentru media lor, pentru drumul parcurs de pupilă la vizionarea imaginii (engl. Pathfinder) precum şi pentru poziţia fixată îndelung. Pentru HR și EDA, fiecare model de clasificator utilizează valorile entropiei ca atribute.
La început, AdaBoost(AB) atribuie o distribuție uniformă a ponderilor la fiecare probă și calculează eroarea pentru fiecare clasificator. Ulterior, greutatea fiecărui clasificator este actualizată, iar numărul de modele este crescut până când precizia predicției din setul de date de antrenament este aproape de valorile optimizate. În această lucrare, AdaBoost folosește o combinație liniară de 100 de arbori de decizie.
KNN este un algoritm de învățare neparametric, lent bazat pe asociații și analogii. KNN este preferată atunci când nu există cunoștințe anterioare privind distribuția datelor. În partea exprimentală au fost utilizate ca măsuri pentru distanțe: distanța Euclidiană, distanța Minkowski, indicele de corelație, distanța City-Block, funcția de similitudine cosinus, distanța Hamming și indexul Jaccard.
LDA folosește o tehnică de reducere a dimensiunilor în etapa de pre-procesare a clasificării. LDA calculează diferite funcții liniare ale atributelor pentru a identifica o anumită clasă. Această procedură nu necesită multe rulări, reușind să genereze într-o singură etapă un bun model de clasificare pentru prezicerea calității de membru al grupului în noul eșantion de observare. Pentru fiecare grupare, LDA presupune utilizarea variabilelor normal distribuite cu matrice de covarianță egale. Pentru a face diferența între grupări, LDA folosește o funcție de discriminare liniară care trece prin centroizii acestora. Funcția de clasă care obține cel mai mare punctaj reprezintă clasa prezisă (Cortes & Vapnik, 1995).
Unul dintre cele mai importante avantaje ale clasificatorului SVM îl constituie capacitatea sa de a gestiona date neliniare. Utilizarea funcțiilor kernel simplifică realizarea unor rezultate precise în problemele de identificare multiclasă (Vito & colab., 2013). Fiind suficient de rezistent la date inconsistente, SVM rezolvă o problemă de clasificare neliniară transformându-l într-o clasificare liniară, dar în alt spațiu dimensional. În etapa experimentală, pentru configurația SVM sunt utilizate mai multe funcții ale kernel-ului, fiind preferat un kernel liniar.
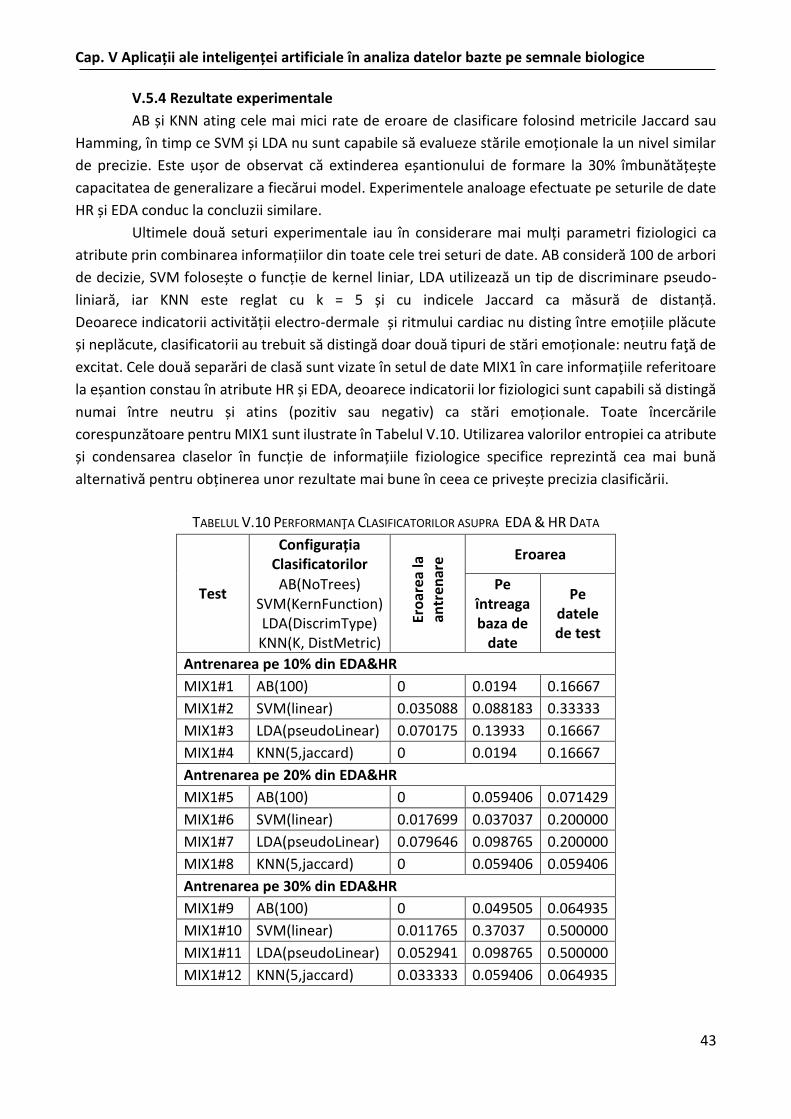
Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
43
V.5.4 Rezultate experimentale
AB și KNN ating cele mai mici rate de eroare de clasificare folosind metricile Jaccard sau
Hamming, în timp ce SVM și LDA nu sunt capabile să evalueze stările emoționale la un nivel similar
de precizie. Este ușor de observat că extinderea eșantionului de formare la 30% îmbunătățește
capacitatea de generalizare a fiecărui model. Experimentele analoage efectuate pe seturile de date
HR și EDA conduc la concluzii similare.
Ultimele două seturi experimentale iau în considerare mai mulți parametri fiziologici ca
atribute prin combinarea informațiilor din toate cele trei seturi de date. AB consideră 100 de arbori
de decizie, SVM folosește o funcție de kernel liniar, LDA utilizează un tip de discriminare pseudo-
liniară, iar KNN este reglat cu k = 5 și cu indicele Jaccard ca măsură de distanță.
Deoarece indicatorii activității electro-dermale și ritmului cardiac nu disting între emoțiile plăcute
și neplăcute, clasificatorii au trebuit să distingă doar două tipuri de stări emoționale: neutru faţă de
excitat. Cele două separări de clasă sunt vizate în setul de date MIX1 în care informațiile referitoare
la eșantion constau în atribute HR și EDA, deoarece indicatorii lor fiziologici sunt capabili să distingă
numai între neutru și atins (pozitiv sau negativ) ca stări emoționale. Toate încercările
corespunzătoare pentru MIX1 sunt ilustrate în Tabelul V.10. Utilizarea valorilor entropiei ca atribute
și condensarea claselor în funcție de informațiile fiziologice specifice reprezintă cea mai bună
alternativă pentru obținerea unor rezultate mai bune în ceea ce privește precizia clasificării.
TABELUL V.10 PERFORMANŢA CLASIFICATORILOR ASUPRA EDA & HR DATA
Test
Configurația Clasificatorilor
Ero
area
la
antr
enar
e Eroarea
AB(NoTrees) SVM(KernFunction) LDA(DiscrimType) KNN(K, DistMetric)
Pe întreaga baza de
date
Pe datele de test
Antrenarea pe 10% din EDA&HR
MIX1#1 AB(100) 0 0.0194 0.16667
MIX1#2 SVM(linear) 0.035088 0.088183 0.33333
MIX1#3 LDA(pseudoLinear) 0.070175 0.13933 0.16667
MIX1#4 KNN(5,jaccard) 0 0.0194 0.16667
Antrenarea pe 20% din EDA&HR
MIX1#5 AB(100) 0 0.059406 0.071429
MIX1#6 SVM(linear) 0.017699 0.037037 0.200000
MIX1#7 LDA(pseudoLinear) 0.079646 0.098765 0.200000
MIX1#8 KNN(5,jaccard) 0 0.059406 0.059406
Antrenarea pe 30% din EDA&HR
MIX1#9 AB(100) 0 0.049505 0.064935
MIX1#10 SVM(linear) 0.011765 0.37037 0.500000
MIX1#11 LDA(pseudoLinear) 0.052941 0.098765 0.500000
MIX1#12 KNN(5,jaccard) 0.033333 0.059406 0.064935

Cap. V Aplicații ale inteligenței artificiale în analiza datelor bazte pe semnale biologice
44
Având în vedere rezultatele obținute, agregarea atributelor din toate seturile de date indicate de MIX2 permite separarea dintre stările emoționale plăcute și neplăcute care nu au putut fi atinse cu gruparea de atribute MIX1. Această combinație de atribute îmbunătățește precizia modelelor de clasificare propuse, precum și sporește capacitatea lor de generalizare oferind rezultate promițătoare în timp ce se evaluează noi eșantioane de date. Performanța generală a măsurilor fiziologice mixte împuternicește ideea ce afirmă că gruparea de atribute are performanțe mai bune decât tipurile de atribute independente.
Senzitivitatea și precizia au fost calculate pentru clasificatorii antrenaţi pe 30% din setul de eșantionare. Pentru setul de date EDA și LDA, au fost identificate imagini plăcute cu o precizie de 40% și o senzitivitate de 41%, în timp ce pentru setul de date EDA și clasificatorul KNN precizia atinge 99%; iar senzitivitatea 90%. În setul de date HR, rata de rapel atinge 75% pentru AB, 64% pentru SVM, 70% pentru LDA și 100% pentru KNN. KNN configurat cu metrica de distanță Jaccard reprezintă o alternativă viabilă în acest caz. Pentru imaginile neutre, rata de rapel a KNN a ajuns la 85%, iar precizia a ajuns la 100%, în timp ce în cazul imaginilor neplăcute, rata de rapel a fost de 74%, iar precizia a fost de 96%.
Evaluarea stării emoționale a fost efectuată ca o problemă de clasificare folosind tehnici cunoscute: AB, KNN, LDA și SVM. O particularitate a acestui studiu este extragerea entropiilor domeniului de timp, și anume entropia aproximativă și entropia eșantionului ca trăsături de clasificare pentru toate seturile de date. Având avantajele de a fi simplu, dar şi foarte eficient, rapid și flexibil, pentru că poate fi combinat cu orice algoritm de învățare, AdaBoost obține cea mai bună performanță globală în identificarea stărilor emoționale.

45
Capitolul VI Concluzii generale
Obiectivele principale ale acestei teze au fost, pe de o parte dezvoltarea unor metode sau algoritmi pentru accelerarea atingerii soluţiilor optimale în problemele de modelare sau analiză a datelor bazate pe serii de timp, iar pe de altă parte investigarea aplicării acestora asupra unor probleme de prognoză a evoluției unor procese chimice, respectiv de selecție a trăsăturilor relevante pentru clasificarea semnalelor biologice.
Rezultatele prezentate în cadrul acestei teze au fost diseminate în 17 lucrări din care 14 publicate sau prezentate și 3 în curs de publicare. Două dintre acestea sunt publicate într-o revistă OpenAccess indexată de CEEOL, opt lucrări au fost publicate în volumele unor conferințe internaționale, toate indexate în IEEE Xplore, şapte fiind indexate ISI Proceedings, alte patru lucrări au fost prezentate în cadrul unor conferințe naționale, o lucrare este trimisă spre publicare în volumului unei conferințe internaționale indexate ISI Proceedings, o alta este în curs de elaborare în dorinţa de a fi trimisă spre publicare într-o revistă indexată ISI şi o a treia este în curs de elaborare în dorinţa de a fi publicată într-o revistă cotată CNCSIS B+. Prezentarea detaliată a acestora poate fi consultată în anexa “Lista publicațiilor”.
Rezultatele ştiinţifice prezentate în capitolele IV și V răspund obiectivelor stabilite. La obţinerea lor autorul acestei teze a lucrat pe toată durata stagiului doctoral.
În acest capitol sunt evidenţiate principalele contribuţii ale autorului în crearea unor noi
metode evolutive de explorare şi contextul în care acestea pot fi utilizate. Crearea unui algoritm evolutiv pentru investigarea şi soluţionarea unor probleme
de optimizare prin adaptarea unor mecanisme (precum încrucișarea sau utilizarea unor elemente din teoria haosului) algoritmului imperialist competitiv (ICA). Mai multe metode şi operatori au fost combinaţi în (Dumitriu, 2015) pentru a accelera timpul în care acesta poate ajunge la o valoarea optimală dorită. Astfel:
Optimizarea operatorul de asimilare pentru a introduce indivizi noi, cu potenţial genetic pentru a încuraja o explorare mai eficientă a spaţiului de căutare. Pentru aceasta s-au aplicat o serie de scheme utilizate în teoria haosului. Efectul imediat a fost o scădere a numărului de epoci necesare până la atingerea unei anumite valori dorite;
Introducerea operatorului de interacţiune între imperialişti prin care aceştia schimbă între ei material genetic, simultan cu injectarea controlată a unui individ creat artificial poate aduce un plus de valoare bazinului de soluţii potenţiale, prin inserarea de material genetic nou;
Minimizarea mutării haotice a celei mai slabe colonii între diverse imperii prin utilizarea operatorului competiție a dus la reducerea timpului de rulare. Oricum efectul acestui operator era minimalist, aşa că trimiterea celei mai slabe colonii la cel mai puternic imperiu asigură convergenţa într-un singur imperiu a populaţiei la un moment dat;
Redivizarea în mai multe imperii în cazul când toate coloniile converg către un singur imperiu, pentru a nu risca o convergenţă prematură sau o explorare limitată a spaţiului de soluţii potenţiale;
Pentru diversele operaţii s-au utilizat cele mai potrivite relaţii găsite în literatură,

Cap. VI Concluzii
46
multe dintre ele evoluând de-a lungul timpului în urma cercetărilor efectuate de diferiți autori.
Investigarea metodelor de eliberare de medicament sau a unor comportamente
reologice a dus la crearea unor metode de modelare pentru predicția comportamentului fizico-chimic al unor sisteme polimerice. Astfel în (Dumitriu, Dumitriu, Manta, 2016; Dumitriu, Dumitriu, Cîmpanu, 2017a) sunt ajustate metodele de antrenare a unor reţele neuronale pe de o parte şi sunt investigate pe de altă parte metode de modelare bazate pe mașini cu vectori suport pentru regresie. Aplicaţiile au fost scrise în C++ şi Matlab. Reducerea timpilor de antrenare a fost de asemenea investigată, alături de reducerea erorii dintre valorile de prognozate și cele observate. Metodele propuse privesc și determinarea unui număr acceptabil de neuroni pe stratul ascuns al rețelei pentru ca modelul final poată oferi valori cât mai bune. Astfel:
Rezultatele simulării eliberării de medicamente (teofilina și ketoprofenul) folosind reţele neuronale artificiale sunt în concordanță cu datele experimentale efectuate in vitro atunci când sunt utilizate hidrogeluri de tip poli (N-izopropil acrilamida)/alginat de sodiu (PNIPAAm/ALG). Acestea prezintă o comportare de eliberare prelungită a medicamentului, ceea ce este confirmat și de simulările efectuate cu modelele propuse (Dumitriu, Dumitriu, Manta, 2016);
Pentru simularea comportamentului reologic al unor suspensii coloidale cu nanoparticule de argint obținute in situ s-au utilizat atât RNA cât și SVM pentru regresie. Modelele create pentru a prognoza acest comportament a condus la obţinerea unor rezultate a căror acurateţe este foarte bună în special pentru dependența tensiune de forfecare – viteză de forfecare (Dumitriu, Dumitriu, Cîmpanu, 2017a).
Pentru determinarea distribuției porilor s-a creat o procedură de analiză automată
a porozității unor hidrogeluri bazată pe procesarea imaginilor obținute prin microscopie electronică de baleiaj (SEM). În general, o probă de hidrogel cu dimensiuni și distribuții uniforme ale porilor va prezenta, de asemenea, proprietăți uniforme de transport al apei, datorită suprafeței mărite de difuzie, ceea ce poate fi util în eliberarea controlată de medicamente. Astfel, au fost propuse două metode de estimare a prozității: una bazată pe modelul gaussian și o a doua bazată pe criteriul J. Totodată este propus și un indicator de performanță pentru estimarea distribuției uniforme porilor (Dumitriu, Dumitriu, Manta, 2019).
Crearea unor algoritmi genetici de optimizare a selecției de trăsături relevante utilizând semnale EEG cu scopul identificării nivelelor de încărcare cognitivă. Pentru aceasta s-au utilizat teste de încărcare a memoriei de lucru (teste aritmetice și paradigme de tip n-back). Trăsăturile, reprezentate de anvelpa semnalelor EEG, au fost selectate prin metode multiobiectiv având două criterii de atins: minimizarea erorii de clasificare și minimizarea numărului de trăsături selectate. Rezultatele au fost publicate în (Cîmpanu, Ferariu, Ungureanu, Dumitriu, 2017b; Cîmpanu, Ferariu, Dumitriu, Ungureanu, 2017c; Ferariu, Cîmpanu, Dumitriu, Ungureanu, 2018). Astfel, doi algoritmi au fost propuși:
O metodă de optimizare pentru selecția trăsăturilor relevante din semnalele EEG cu comutare între clasificatori ce implică comutarea între metode diferite de clasificare (RF și SVM) cu scopul de a diminua efectele individuale pe care un clasificator anume le aduce căutării. În acest mod se asigură o selecție obiectivă a trăsăturilor (Cîmpanu, Ferariu, Ungureanu, Dumitriu, 2017b; Cîmpanu, Ferariu, Dumitriu, Ungureanu, 2017c);

Cap. VI Concluzii
47
O metodă de optimizare pentru selecția trăsăturilor relevante din semnalele EEG bazată pe utilizarea extensiilor temporale. Aceasta pleacă de la ideea că dinamica activităților mentale depinde și de acțiunile anterioare. De aceea cromozomii au fost creați în așa fel încât valorile precedente ale atributelor sunt reținute în același vector, ceea ce asigură informații suplimentare clasificatorului legate de variația semnalelor EEG. Deși avantajoasă din punct de vedere a clasificării, apar probleme legate de creșterea spațiului de explorare. Pentru a evita acest lucru, s-a utilizat o codificare discretă în baza patru a cromozomilor. Totodată, pentru a atenua efectele nedorite a creșterii dimensiunii spațiului de explorare s-au propus două metode care să eficientizeze explorarea spațiului de căutare (Ferariu, Cîmpanu, Dumitriu, Ungureanu, 2018):
Creșterea graduală a complexității modelului de clasificare; Configurarea dinamică a parametrilor funcției obiectiv.
Investigarea performanțelor algoritmilor de învățare supervizată utilizați în
determinarea nivelelor de încărcare cognitivă folosind semnale EEG achiziționate în cadrul
experimentelor efectuate utilizând paradigma n-back ( 3,1n ) sau calcule matematice simple,
dar a căror dificultate crește gradual, a vizat ilustrarea importanței selectării intuitive a trăsăturilor utilizate pentru clasificare, precum și analiza comparativă a performanțelor obținute pentru seturi de date achiziționate cu dispozitive diferite (Ungureanu, Cîmpanu, Dumitriu, Manta, 2017; Cîmpanu, Ungureanu, Manta, Dumitriu, 2017a; Dumitriu & Cîmpanu, 2017). Au fost analizate și comparate performanțele unor metode diferite de clasificare (KNN, NB, AdaBoost, SVM sau RF) pentru identificarea nivelelor de încărcare a memoriei de lucru (Cîmpanu, Dumitriu, Ungureanu, 2018a).
În cadrul investigațiilor s-a efectuat și o analiză statistică a semnalelor EEG ce pot
discrimina între diferite nivele de încărcare cognitivă. Atât pentru a diferenția între nivelele de încărcare cognitivă cât și pentru a identifica relevanța trăsăturilor considerate, s-au utilizat indicatori statistici precum: valoarea medie, RMSE, intercorelația. Analiza a reliefat dificultatea de selecție utilizând metode de tip filtru, justificând astfel căutarea altor metode (Ungureanu, Cîmpanu, Dumitriu, Manta, 2017).
Estimarea stărilor afective pe baza analizei semnalelor fiziologice umane precum
activitatea electrodermală, variaţia ritmului cardiac sau urmărirea acţiunilor pupilei a fost de asemenea investigată. Pentru a determina starea afectivă a unei persoane, s-au utilizat o serie de parametri fiziologici. Folosind senzori de monitorizare a activității electrodermale, a privirii sau a pulsului, subiecţii au efectuat experimente bazate pe stimuli vizuali. Datele achiziţionate au fost prelucrate şi analizate comparând rezultatul unor algoritmi de învăţare cunoscuţi precum: KNN, AdaBoost, SVM sau LDA. Pentru a estima starea afectivă s-a utilizat o abordare multimodală folosind atributele EDA, HR și ET și s-a investigat utilizarea entropiilor semnalelor (Sample Entropy și Approximate Entropy) ca trăsături principale pentru clasificare, ceea ce este o idee nouă de analiză a emoțiilor. Deşi promiţătoare, aceste metode trebuie analizate împreună cu date EEG în dorinţa de a obţine o acurateţe ridicată (Dumitriu, Ungureanu, Cîmpanu, Manta, 2018).
.

48
Lista publicațiilor
I. Articole publicate în volumele unor conferințe indexate ISI Proceedings:
1. Tiberius Dumitriu, “A Novel Hybrid Approach of Evolutionary Algorithm Based on Imperialist Competitive Algorithm”, Proceedings of 2015 19th International Conference on System Theory, Control and Computing (ICSTCC), October 14-16, 2015, Cheile Grădistei - Fundata Resort, România, pp. 140-146, IEEE Catalog Number: CFP1536P-USB, ISBN: 978-1-4799-8480-0; DOI: 10.1109/ICSTCC.2015.7321283
2. Tiberius Dumitriu, Raluca Petronela Dumitriu, Vasile-Ion Manta, “Application of Artificial Neural Networks for modeling drug release from a bicomponent hydrogel system”, 20th International Conference on System Theory, Control and Computing (ICSTCC), October 13-15, Sinaia 2016, Romania, pp. 675-680, IEEE Catalog Number: CFP1636P-ART, ISBN 978-1-5090-2720-0, DOI: 10.1109/ICSTCC.2016.7790744
3. Corina Cîmpanu, Florina Ungureanu, Vasile Ion Manta and Tiberius Dumitriu, “A Comparative Study on Classification of Working Memory Tasks Using EEG Signals”, CSCS21: The 21th International Conference on Control Systems and Computer Science, Bucharest, Romania, 29-31 May 2017. ISBN: 978-1-5386-1839-4; (PoD) ISBN: 978-1-5386-1840-0; ISSN: 2379-0482; DOI: 10.1109/ CSCS.2017.41
4. Corina Cîmpanu, Lavinia Ferariu, Tiberius Dumitriu and Florina Ungureanu, “Multi-Objective Optimization of Feature Selection Procedure for EEG Signals Classification”, 6th edition of the International Conference on e-Health and Bioengineering, EHB 2017, 22-24 June 2017, ISBN: 978-1-5386-0358-1; ISBN: 978-1-5386-1514-0; DOI: 10.1109/EHB.2017.7995454
5. Tiberius Dumitriu, Raluca Petronela Dumitriu and Corina Cîmpanu, “Artificial neural networks and support vector regression modeling for prediction of some silver colloidal suspensions rheological behavior”, ICSTCC 2017, 21st International Conference on System Theory, Control and Computing October 19 - 21, 2017, Sinaia, Romania, 2017. ISBN: 978-1-5386-3842-2; DOI: 10.1109/ ICSTCC.2017.8107105;
6. Corina Cîmpanu, Lavinia Ferariu, Florina Ungureanu and Tiberius Dumitriu, “Genetic Feature Selection for Large EEG Data with Commutation between Multiple Classifiers”, ICSTCC 2017, 21st International Conference on System Theory, Control and Computing October 19 - 21, 2017, Sinaia, Romania, 2017. ISBN: 978-1-5386-0358-1, DOI: 10.1109/ICSTCC.2017.8107104.
II. Articole publicate în volumele unor jurnale indexate de CEEOL
1. Florina Ungureanu, Corina Cîmpanu, Tiberius Dumitriu, and Vasile Ion Manta, “Cognitive Load and Short Term Memory Evaluation Based on EEG Techniques”, The 13th eLearning and Software for Education Conference, ELSE 2017, vol. 2, pp. 217- 224, ISSN: 2066-026X, ISSN-L: 2066-026X, ISSN CD: 2343-7669, April 27-28, Bucharest, Romania, 2017.
2. Corina Cîmpanu, Tiberius Dumitriu, and Florina Ungureanu, “Instructional Design Based on the Assessment of Cognitive Load and Working Memory Load”, The 14th eLearning and Software for Education Conference, ELSE 2018, vol. 2, pp.54-61, April 19-20, Bucharest, Romania, 2018. (indexat și ISI Proceedings)

Lista publicațiilor
49
III. Articole publicate în volumele unor conferințe indexate IEEE Xplore
1. Tiberius Dumitriu, Corina Cîmpanu, Florina Ungureanu, Vasile-Ion Manta, “Experimental Analysis of Emotion Classification Techniques,Proceedings”, 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing, ICCP 2018, 6 - 8 September 2018 Cluj, Romania, 8516647, pp. 63-70, DOI: 10.1109/ICCP.2018.8516647
2. Lavinia Ferariu, Corina Cîmpanu, Tiberius Dumitriu, Florina Ungureanu, “EEG multi-objective feature selection using temporal extension“, Proceedings of the 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing, ICCP 2018 6 - 8 September 2018 Cluj, Romania, 8516613, pp. 105-110, DOI: 10.1109/ICCP.2018.8516613
IV. Lucrări publicate în volumele unor conferințe naționale
1. Corina Cîmpanu and Tiberius Dumitriu, “Comparative Study on EEG Signals Classification and Multi-Objective Optimization of Feature Selection”, First Conference of the TUIASI Doctoral School, CSD 2017, May 29-30, Iasi, Romania, 2017.
2. Tiberius Dumitriu and Corina Cîmpanu, “The Assessment of Short Term Memory and Cognitive Load using EEG Techniques”, First Conference of the TUIASI Doctoral School, CSD 2017, May 29-30, Iasi, Romania, 2017.
3. Corina Cîmpanu, Lavinia Ferariu, Tiberius Dumitriu and Florina Ungureanu, “A Comparison of Ranking Methods Used in Multiobjective Optimization for Feature
Selection in EEG Signals”, Conference of the TUIASI Doctoral School 2nd Edition, CSD 2018, May 23-24, 2018, Iasi, Romania, 2018.
4. Corina Cîmpanu, Lavinia Ferariu, Tiberius Dumitriu and Florina Ungureanu, “On the Impact of a Classification Model in EEG Feature Selection for Cognitive Load Assessment”,
Conference of the TUIASI Doctoral School 2nd Edition, CSD 2018, May 23-24, 2018, Iasi, Romania, 2018.
V. Lucrări în curs de publicare sau elaborare
1. Corina Cîmpanu, Lavinia Ferariu, Tiberius Dumitriu and Florina Ungureanu, “Feature Selection in EEG Signals via Multi-Objective Genetic Algorithm with Fuzzy Fitness Assignment Scheme“, Journal of Control Engineering and Applied Informatics, în lucru, 2019.
2. Tiberius Dumitriu, Raluca Petronela Dumitriu, Vasile-Ion Manta, “Automated hydrogel porosity analysis based on scanning electron microscopy image processing“, The 7th edition of the International Conference on e-Health and Bioengineering, EHB 2019, în lucru, 2019.
3. Tiberius Dumitriu, “Feature selection for EEG data using Imperialist Competitive Algorithm“, Buletinul Institutului Politehnic din Iaşi, în lucru, 2019.
VI. Proiecte
1. Natural sense of vision through acoustics and haptics (Sound of Vision), grant H2020-PHC-26_2014, Nr. 643636, perioada 01.01.2015 -31.12.2017, buget UTI 424709.5 EUR, Responsabil UTI, prof.dr.ing. Vasile Manta - proiect Horizon 2020, membru, anul 2017.
2. POSDRU/125/5.1/S/125723 “ACTIV pe Piata Muncii: Abilitati si Competente Tehnice pentru Integrare si Valorificare pe Piata Muncii”, expert pe termen lung.

50
Bibliografie selectivă
Abdel Aal M.A., Alsawy A.A. and Hefny H.A. (2017), “EEG-Based Emotion Recognition Using a Wrapper-Based
Feature Selection Method”, in Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Springer, 247-256, 2017.
Anghelache C., Manole Al. (2012), “Seriile dinamice / cronologice (de timp)”, Revista română de statistică nr. 10 / 2012, 78-87.
Atashpaz-Gargari E., Lucas C. (2007), “Imperialist competitive algorithm an algorithm for optimization inspired by imperialist competition”, IEEE Congress on Evolutionary Computation (CEC 2007), pp 4661-4667, 2007.
Atashpaz-Gargari E. (2008), “Imperialist competitive algorithm (ICA).”, http://www.mathworks.com /matlabcentral/fileexchange/22046-imperialist-competitive-algorithm-ica, 2008 (online, accesat 2019).
Berg M.C., Zhai L., Cohen R.E., Rubner M.F. (2006), “Controlled Drug Release from Porous Polyelectrolyte Multilayers”, Biomacromolecules,Vol.7, No.1, 357-364, 2006.
Bing-rui C., Xia-ting F. (2008), "Self-adapting Chaos-genetic Hybrid Algorithm with Mixed congruential
Method", Forth International Conference on Natural Computation,18-22,October, 2008, Jinan, China, 674-67. Breiman, L. (2001), “Random forests. Machine Learning”, 45(1), 5-32. doi:10.1023/ A:1010933404324, 2001. Campbell A., Murray P., Yakushina E., Marshall S., Ion W. (2018), “New methods for automatic quantification
of microstructural features using digital image processing”, Mater. Design 141, 395–406, 2018. Cîmpanu C., Ungureanu F., Manta V.I., Dumitriu T. (2017a), “A Comparative Study on Classification of
Working Memory Tasks Using EEG Signals”, The 21th International Conference on Control Systems and Computer Science, CSCS21, May 29-31, 2017, Bucharest, Romania, 245-251, ISBN: 978-1-5386-1839-4; ISSN: 2379-0482, doi: 10.1109/CSCS.2017.41, 2017.
Cîmpanu C., Ferariu L., Ungureanu F., Dumitriu T. (2017b), “Genetic Feature Selection for Large EEG Data with Commutation between Multiple Classifiers”, The 21st International Conference on System Theory, Control and Computing, ICSTCC 2017, October 19-21, Sinaia, Romania, 434-437, ISBN: 978-1-5386-0358-1, doi: 10.1109/ICSTCC.2017.8107104, 2017.
Cîmpanu C., Ferariu L., Dumitriu T., Ungureanu F. (2017c), “Multi-Objective Optimization of Feature Selection Procedure for EEG Signals Classification”, 6th edition of the International Conference on e-Health and Bioengineering, EHB 2017, 434-437, ISBN: 978-1-5386-0358-1, doi: 10.1109/EHB.2017.7995454, June 22-24, Sinaia, Romania, 2017.
Cîmpanu C. and Dumitriu T., (2017d). “Comparative Study on EEG Signals Classification and Multi-Objective Optimization of Feature Selection”, First Conference of the TUIASI Doctoral School, CSD 2017, May 29-30, Iasi, Romania.
Cîmpanu C., Dumitriu T., Ungureanu F. (2018a), “Instructional Design Based on the Assessment of Cognitive Load and Working Memory Load”, The 14th eLearning and Software for Education Conference, ELSE 2018, vol. 2, 54-61, April 19-20, Bucharest, Romania, doi: 10.12753/2066-026X-18-078, 2018.
Cîmpanu C., Ferariu L., Dumitriu T., Ungureanu F., (2018b). ”A Comparison of Ranking Methods Used in Multiobjective Optimization for Feature Selection in EEG Signals”, Conference of the TUIASI Doctoral School 2nd Edition, CSD 2018, May 23-24, Iasi, Romania.
Cîmpanu C., Ferariu L., Dumitriu T., Ungureanu F., (2018c). ”On the Impact of a Classification Model in EEG Feature Selection for Cognitive Load Assessment”, Conference of the TUIASI Doctoral School 2nd Edition, CSD 2018, May 23-24, Iasi, Romania.
Clerc M., Kennedy J. (2002), “The particle swarm—Explosion, stability, and convergence in a multidimensional complex space.”, IEEE Transaction Evolut. Comput., vol. 6, 58–73, 2002.
Coluccino L., Stagnaro P., Vassalli M., Scaglione S. (2016), “Bioactive TGF-β1/HA alginate-based scaffolds for osteochondral tissue repair: Design, realization and multilevel characterization”, J. Appl. Biomater. Func.14, 42–52.
Cortes C., Vapnik V.N. (1995), “Support-vector networks”, Machine Learning. 20 (3), 273–297, 1995. CSEA, Center for Emotion and Attention, University of Florida, http://csea.phhp.ufl.edu /index.html. Deb K., (2011). “Multi-Objective Optimization using Evolutionary Algorithms”, Wiley. Deng H., Sun Y., Chang Y., Han J. (2015), ”Probabilistic Models for Classification”, in ed. Aggarawal C.C., Data
Classification: Algorithms and Applications, 65-86, CRC Press, Taylor&Francis, 2015. Duan H., Xu C., Liu S., Shao S. (2010), “Template matching using chaotic imperialist competitive algorithm”,
Pattern Recognition Letters, vol. 31, 1868–1875, 2010. Dumitriu T. (2015), “A Novel Hybrid Approach of Evolutionary Algorithm Based on Imperialist Competitive
Algorithm”, Proceedings of 2015 19th International Conference on System Theory, Control and Computing, October 14-16, ICSTCC 2015, Cheile Grădistei - Fundata Resort, România, 140-146, IEEE Catalog Number: CFP1536P-USB, ISBN: 978-1-4799-8480-0; doi: 10.1109/ICSTCC.2015.7321283, 2015.

Referințe bibliografice
51
Dumitriu T., Dumitriu R.P., Manta V.I. (2016), “Application of Artificial Neural Networks for modeling drug release from a bicomponent hydrogel system”, 20th International Conference on System Theory, Control and Computing (ICSTCC), October 13-15, Sinaia, Romania, 675-680, 2016.
Dumitriu T., Dumitriu R.P., and Cîmpanu C. (2017), „Artificial neural networks and support vector regression modeling for prediction of some silver colloidal suspensions rheological behavior”, ICSTCC 2017, 21st International Conference on System Theory, Control and Computing October 19 - 21, 2017, Sinaia, Romania, ISBN: 978-1-5386-3842-2, doi: 10.1109/ICSTCC.2017.8107105, 2017.
Dumitriu T. and Cîmpanu C., (2017). ”The Assessment of Short Term Memory and Cognitive Load using EEG Techniques”, First Conference of the TUIASI Doctoral School, CSD 2017, May 29-30, Iasi, Romania.
Dumitriu T., Ungureanu F., Cîmpanu C., Manta V.I. (2018), “Experimental Analysis of Emotion Classification Techniques”, The IEEE 14th International Conference on Intelligent Computer Communication and Processing, ICCP 2018, September, 6-8, Cluj, Romania, doi: 10.1109/ICCP.2018.8516647.
Dumitriu T., Dumitriu R.P., Manta V.I. (2019), “Automated hydrogel porosity analysis based on scanning electron microscopy image processing”, The 7th edition of the International Conference on e-Health and Bioengineering, EHB 2019, în lucru, 2019.
Dunn R.M., Schrlau M.G. (2018), “Numerical processing of CNT arrays using 3D image processing of SEM Images”, Robot. CIM. Int. Manuf. 53, 21–27, 2018.
Drury J.L., Mooney D.J. (2003), “Hydrogels for tissue engineering: scaffold design variables and applications”, Biomaterials 24, 4337–4351, 2003.
Ferariu L. (2013), “Sisteme Inteligente Hibride”, Conpress, Bucuresti, 2013 Ferariu L., Cîmpanu C., Dumitriu T., Ungureanu F. (2018), “EEG Multi-Objective Feature Selection Using
Temporal Extension”, The IEEE 14th International Conference on Intelligent Computer Communication and Processing, ICCP 2018, Cluj, Romania, 2018, September, 6-8, Cluj, Romania, ISBN: 978-1-5386-8445-0, doi: 10.1109/ICCP.2018.8516613, 2018.
Gao M., Xu J., Tian J. and Wu H. (2008), "Path Planning for Mobile Robot based on Chaos Genetic Algorithm",
Forth International Conference on Natural Computation,18-22,October, 2008, Jinan, China, 409-413, 2008. Gao W.F., Liu S.Y., Huang L.L. (2012), “A global best artificial bee colony algorithm for global optimization.”,
J. Comput. Appl. Math. 2012, vol. 236, 2741–2753, 2012. Granata F., Gargano R. and de Marinis G. (2016), “Support Vector Regression for Rainfall-Runoff Modeling in
Urban Drainage: A Comparison with the EPA’s Storm Water Management Model”, Water 2016, 8(3), 69. Hebb D.O (1049), “The Organization of Behavior; a neuropsychological theory”, Wiley: New York; 1949. Holland J.H. (1975), “Adoption in Natural and Artificial Systems”, Michigan Press, 1975. iMotions (2018), “Human Behavior – The Complete Pocket” Guide, available at https://imotions.com/guides/,
ultima vizită mai 2018. Jerritta S., Murugappan M., Nagarajan R, Khairunizam W. (2011), “Physiological Signals Based Human
Emotion Recognition: A Review”, IEEE 7th International Colloquium on Signal Processing and its Applications, 410-415, 2011.
Leon F. (2006), “Inteligenţa Artificială, principii, tehnici, aplicaţii”, Tehnopress, Iaşi, 2006. Liang Z., Li J., Xia X., Wang Y., Li X., He J., Bai Y. (2018), “Long-Range Temporal Correlations of Patients in
Minimally Conscious State Modulated by Spinal Cord Stimulation”, Frontiers in Physiology, 2018, DOI: 10.3389/fphys.2018.01511.
Liang Z., Wang Y., Sun X., Li D., Voss L. J., Sleigh J.W., Hagihira S. and Li X. (2015), “EEG entropy measures in anesthesia”, Frontiers in Computational Neuroscience, 9, 16, 2015.
Lin G., Chang S., Kuo C.-H., Magda J., Solzbacher F. (2009), “Free swelling and confined smart hydrogels for applications in chemomechanical sensors for physiological monitoring”, Sensor. Actuat. B-Chem. 136, 186–195.
Lin J.L., Tsai Y.H., Yu C.Y. and Li M.S. (2012), “Interaction Enhanced Imperialist Competitive Algorithms”, Algorithms,vol. 5, 433-448, 2012.
Lin J. L., Cho C. W., Chuan H. C. (2013), “Imperialist Competitive Algorithms with Perturbed Moves for Global Optimization”, Applied Mechanics and Materials, vol. 284-287, 3135-3139, Jan. 2013
Loewenfeld E. (1993), “The Pupil: Anatomy, Physiology, and Clinical Applications”, University of Iowa Press. Lulio L. C., Tronco M. L., Porto A. J. V. (2011), “JSEG Algorithm and Statistical ANN Image Segmentation
Techniques for Natural Scenes”, Cap 18 in Image Segmentation, Ed. by Pei-Gee Ho, InTech (ISBN 978-953-307-228-9), 343-364, 2011.
Martin, S. (2014), “Measuring cognitive load and cognition: Metrics for technology-enhanced learning.” Educational Research and Evaluation, 20(7-8), 592-621. doi:10.1080/ 13803611.2014.997140, 2014.

Referințe bibliografice
52
Martín-Smith P., Ortega J., Asensio-Cuber J., Gan J.Q. and Ortiz A. (2017), “A supervised filter method for multi-objective feature selection in EEG classification based on multi-resolution analysis for BCI”, in Neurocomputing 250, 45–56, 2017.
MDA (2010) – “Mic Dicționar Academic”, Academia Română, ediția a II-a revizuită, editura Univers Enciclopedic Gold, 2010.
Minsky M., Papert S. (1969), “Perceptrons: An lntroduction to Computational Geometry”, MIT Press, Cambridge, Mass., 1969.
Mutasim A.K., Tipu R.S., Bashar M.R., Islam M.K. and Amin M.A. (2018), “Computational Intelligence for Pattern Recognition in EEG Signals”, in Computational Intelligence for Pattern Recognition in EEG Signals, Part of the Studies in Computational Intelligence book series (SCI),Springer, volume 777, 291-320, 2018.
Nixon M. S., Aguado A. S. (2008), “Feature Extraction and Image Processing”. Academic Press, 2008. Peppas N.A., Bures P., Leobandung W., Ichikawa H. (2000), “Hydrogels in pharmaceutical formulations”, Eur.
J. Pharm. Biopharm. 50, 27–46, 2000. Peretó J., Bada J. L., Lazcano A. (2009), “Charles Darwin and the Origin of Life”, Origins of Life and Evolution
of the Biosphere, Springer, 39(5): 395–406, 2009. Rac-Lubashevsky, R. and Kessler, Y. (2016), “Decomposing the n-back task: An individual differences study
using the reference-back paradigm”. Neuropsychologia, 90, 190-199. doi:10.1016/j.neuropsychologia.2016.07.013. Ramezania F., Shahriar Lotfib (2013), “Social-Based Algorithm (SBA)”, in Applied Soft Computing, vol. 1, 2837–
2856, 2013. Roy I., Gupta M.N. (2003), “Smart polymeric materials: emerging biochemical applications”, Chem. Biol. 10,
1161–1171, 2003. Savage R.L., Moller P.W., Ballantyne C.L., Wells J.E. (1993), “Arthritis. Rheum.”, Vol.36, No.1, 84-90, 1993. Schapire R., Freund Y. (2012), “Boosting” Foundations and Algorithms, MIT, ISBN: 9780262017183, 2012. ***Shimmer 3GRS (2018), http://www.shimmersensing.com/products/GSR-optical-pulse-development-kit,
last visit May 2018. Silva J. R. (2011), “International Affective Picture System (IAPS) In Chile: A Cross-Cultural Adaptation And
Validation Study”, Terapia Psicológica, Vol. 29, Nº 2, 251-25, 2011. Stewart A.X., Nuthmann A., Sanguinetti G., (2014). “Single-trial classification of EEG in a visual object task
using ICA and machine learning”, Journal of Neuroscience Methods, vol. 228, 1–14. Suganthan P. N., Hansen N., Liang J. J., Deb K., Chen Y. -P., Auger A., Tiwari S. (2005), “Problem Definitions
and Evaluati on Criteria for the CEC 2005 Special Session on Real-Parameter Optimization” in Technical Report, Nanyang Technological University, Singapore And KanGAL Report Number 2005005 (Kanpur Genetic Algorithms Laboratory, IIT Kanpur), May 2005.
Sweller, J. (1994), “Cognitive load theory, learning difficulty, and instructional design. Learning and Instruction”, 4(4), 295-312. doi:10.1016/0959-4752(94)90003-5, 1994.
Ungureanu F., Cîmpanu C., Dumitriu T., Manta V.I. (2017), “Cognitive Load and Short Term Memory Evaluation Based on EEG Techniques”, The 13th eLearning and Software for Education Conference, ELSE 2017, vol. 2, 217-224, ISSN: 2066-026X, ISSN-L: 2066-026X, ISSN CD: 2343-7669, April 27-28, Bucharest, Romania, 2017.
Vito E.d., Umanità V., Villa S. (2013), “An extension of Mercer theorem to matrix-valued measurable kernels”, Applied and Computational Harmonic Analysis, vol. 34, issue 3, 339-351, 2013.
Xiaodong Li, Ke Tang, Mohammad N. Omidvar, Zhenyu Yang, and Kai Qin (2013a), “Benchmark Functions for the CEC’2013 Special Session and Competition on Large-Scale Global Optimization”, http://goanna.cs.rmit.edu.au/~xiaodong/cec13-lsgo/competition/cec2013-lsgo-benchmark-tech-report.pdf, 2013.
Xiaodong Li, Andries Engelbrecht, Michael G. Epitropakis (2013b), “Benchmark Functions for CEC’2013 Special Session and Competition on Niching Methods for Multimodal Function Optimization”, http://goanna.cs.rmit.edu.au/~xiaodong/cec13-niching/competition/cec2013-niching-benchmark-tech-report.pdf.
Zhang X. (2012), “The Application of Imperialist Competitive Algorithm based on Chaos Theory in Perceptron Neural Network”, 2012 International Conference on Solid State Devices and Materials Science, Physics Procedia, vol. 25, 536 – 542, 2012.
Zhang Y., Wu L. (2011), “Optimal multi-level thresholding based on maximum tsallis entropy via an artificial bee colony approach.”, Entropy, vol. 13, 841–859, 2011.
Zong Y. and Jianhua Z. (2017), “Subject-generic EEG Feature Selection for Emotion Classification via Transfer Recursive Feature Elimination”, Procedings of The 36th Chinese Control onference, China, 11005-11010, 2017.
Wang S., Yang H. (2013), ”Comparison among Methods of Ensemble Learning”, IEEE International Symposium on Biometrics and Security Technologies, 286-290, 2013.
Wang Y.-H. (2010), “Tutorial: Image Segmentation”, Graduate Institute of Communication Engineering, National Taiwan University, Taipei, Taiwan, ROC., 2010.