referat ii platforme pentru · 2013-10-10 · platforme pentru analiza şi generarea semnalului...
TRANSCRIPT

Academia Română
Secţia Ştiinţa şi Tehnologia Informaţiei
Institutul de Cercetări pentru Inteligenţă Artificială
REFERAT II
PLATFORME PENTRU
ANALIZA ŞI GENERAREA
SEMNALULUI VOCAL
Coordonator ştiinţific: Prof. Dr. Ioan Dan TUFIŞ
Membru Corespondent al Academiei Romane
Doctorand: Tiberiu BOROŞ

Platforme pentru analiza şi generarea semnalului vocal
2
Cuprins
1. Introducere .................................................................................................................. 3
1.1. Vorbirea umană .................................................................................................... 3
1.2. Sisteme TTS ......................................................................................................... 6
2. Arhitectura sistemelor TTS ......................................................................................... 8
2.1. Prelucrarea limbajului natural .............................................................................. 8
2.1.1. Normalizarea textelor ................................................................................... 8
2.1.2. Analiza morfologică ................................................................................... 10
2.1.3. Transcrierea fonetică .................................................................................. 13
2.1.4. Sinteza prozodică ........................................................................................ 14
2.2. Sinteza vorbirii ................................................................................................... 15
2.2.1. Sinteza concatenativă ................................................................................. 15
2.2.2. Algoritmi de modificare prozodică a segmentelor acustice ....................... 16
2.2.3. Metode de evaluare a sistemelor TTS ........................................................ 19
3. Aplicaţii de sinteză a vorbirii .................................................................................... 22
3.1. Aplicaţii comerciale ........................................................................................... 22
3.2. Aplicaţii gratuite ................................................................................................ 22
3.3. Evaluarea sistemelor .......................................................................................... 22
4. Concluzii ................................................................................................................... 24
5. Referinţe bibliografice............................................................................................... 25

Platforme pentru analiza şi generarea semnalului vocal
3
1. Introducere
În prezenta lucrare, evidenţiez o serie de aspecte legate de sinteza vorbirii pornind de la
text, incluzând elemente de prelucrare a limbajului natural, prelucrare digitală a semnalelor şi
metode de evaluare a sistemelor TTS (text-to speech).
Primul capitol este unul introductiv, în care prezint elemente teoretice legate de modul de
producere a vorbirii umane şi de caracteristicile acustice ale diferitelor sunete din limba
română.
1.1. Vorbirea umană Vorbirea este un proces de comunicare specific omului care se dezvoltă de-a lungul
timpului. Din punct de vedere fizic, vorbirea începe prin producerea unui flux de aer pornind
din plămâni sau diafragmă, care trece prin laringe unde este modulat de corzile vocale. Acest
pas se numeşte fonaţie şi determină înălţimea şi tonul vocii. Există patru corzi vocale (două
superioare şi două inferioare), între care se află o deschizătură (glota interligamentoasă),
diferită ca dimensiuni pentru bărbaţi şi femei. Activitatea corzilor vocale este stimulată şi
dirijată de către sistemul nervos central. Faringele ajustează direcţia fluxului de aerul spre
cavitatea bucală, spre cavitatea nazală sau spre amândouă simultan, aerul fiind astfel filtrat
de gură, nas şi gât – proces numit articulare.
Ca o consecinţă a acestei fiziologii, se observă unele caracteristici ale spectrului vorbirii
în domeniul frecvenţă. În primul rând, oscilaţia glotei determină o frecvenţă fundamentală
(F0) şi o serie de armonici. Valorile armonicilor sunt multipli ai F0. Localizarea frecvenţei
fundamentale este dependentă de vorbitor şi în mod direct responsabilă de înălţimea vocii.
Diferite foneme (cea mai mică unitate sonoră a limbii, care are funcţia de a diferenția
cuvintele între ele, precum și formele gramaticale ale aceluiași cuvânt) (în special vocalele)
au regiuni caracteristice de energie ridicată în cadrul spectrului. Aceste regiuni de vârf sunt
numite formanţi (Fant, 1970) şi localizarea lor poate fi folosită atât pentru identificarea
fonemelor cât şi a vorbitorului. Toată energia spectrului vocal se regăseşte intre 0 și 4kHz, iar
dincolo de 10kHz, în afara intervalului neexistând practic nici un fel de energie. De altfel,
aceasta este unul din motivele pentru care este este preferată rata de eşantionare de 8kHz în
sistemele de telefonie.
În majoritatea limbilor din lume, inventarul de foneme este împărţit în două mari
categorii:
1. Consoanele, care sunt articulate cu ajutorul obstacolelor formate de componentele
cavităţii bucale în calea fluxului de aer.
2. Vocalele sunt articulate fără obstacole.
La rândul lor, sunetele pot fi împărţite în subgrupuri. În cazul limbii române există
următoarea clasificare a sunetelor din punct de vedere articulatoriu (Burileanu, 1999):
1. Vocalele: se disting prin înălţime (dată de frecvenţa fundamentală) şi prin timbru
(reprezentat prin conţinutul de armonici care se alătură frecvenţei fundamentale).
a. În funcţie de unghiul de deschidere a maxilarelor (apertura):
i. Vocale deschise: a
ii. Vocale medii (semideschise): e, ă, o

Platforme pentru analiza şi generarea semnalului vocal
4
iii. Vocale închise: i, î (â), u
b. În funcţie de localizarea lor, deci de locul de articulare (punctul din
cavitatea bucală în care se creează spaţiul optim de rezonanţă, realizat prin
diferitele poziţii pe care le ia muşchiul lingual):
i. Vocale anterioare: e, i
ii. Vocale centrale (neutre): a, ă, î (â)
iii. Vocale posterioare (postpalatale): o, u
c. După modul în care sunt însoţite sau nu de rotunjirea buzelor:
i. Vocale labializate (rotunjite): o, u
ii. Vocale nelabializate: a, e, i, ă, î (â)
Vocale
Deschidere
Închise
Cvasiînchise
Semiînchise
Mijlocii
Semideschise
Cvasideschise
Deschise
Anterioritate
Anterioare Semianterioare Centrale Semiposterioare Posterioare
i y ɨ ʉ ɯ u
ɤ o
ʌ ɔ
ɑ ɒ
äa ɶ
æ
ɛ œ
ɪ ʏ ʊ
ɘ ɵe ø
ə
ɜ ɞ
ɐ
Figura 1.1 - Clasificarea vocalelor după deschidere, loc de articulare şi rotunjire
2. Consoanele: De asemenea şi consoanele sunt împărţie în consoane sonante şi
nesonante.
a. Clasificarea consoanelor nesonante:
i. După modul de articulare:
1. Consoane oclusive (explozive, sau plozive): p, b, t, d, c, g, ch,
gh (produse prin închiderea completă a canalului fonator şi
apoi deschiderea sa bruscă);
2. Consoane fricative (constrictive): f, v, s, z, ş, j, h (sunt
consoane produse printr-o îngustare a canalului fonator);
3. Consoane semioclusive (africate): ţ, c(e/i), g(e/i) (sunt
consoane ce au un început oclusiv, dar un final fricativ).

Platforme pentru analiza şi generarea semnalului vocal
5
ii. După locul de articulare (locul din cavitatea bucală unde se creează
obstacolul):
1. Consoane bilabiale: p, b;
2. Consoane labio-dentale: f, v;
3. Consoane dentale (alveorare): t, d, s, z, ţ;
4. Consoane prepalatale (anteropalatale): ş, j, c(e/i), g(e/i);
5. Consoane palatale: ch, gh;
6. Consoane velare (postpalatale): c, g;
7. Consoane laringale (glotale): h;
iii. După sonoritate (pronunţia unei consoane este însoţită sau nu de
vibraţia coardelor vocale):
1. Consoane sonore: b, d, g, gh, v, z, j, g(e/i);
2. Consoane nesonore (surde): p, t, c, ch, f, s, ş, h, c(e/i), ţ;
b. Clasificarea consoanelor sonante: această clasă de consoane reprezintă o
categorie distinctă care are caracteristici comune atât cu vocalele cât şi cu
consoanele. Astfel, la articularea lor predomină tonurile muzicale, zgomotele
specifice consoanelor fiind mai slab. Ca şi consoanele nesonante, ele nu
primesc accent în silabă.
i. În funcţie de modul de articulare:
1. Sonante oclusive: m, n;
2. Sonante lichide: l;
3. Sonante vibrante: r.
ii. În funcţie de locul de articulare
1. Sonante bilabiale: m;
2. Sonante dentale: n, r;
3. Sonante laterale: l.
iii. În funcţie de timbru:
1. Sonante nazale: m, n;
2. Sonante orale: l, r.
Modul de
articulare Lo
cul
de
art
icu
lare
Bilabiale Labiodentale Dentale Prepalatale Palatale Velare Laringiale
Su
rde
So
no
re
Su
rde
So
no
re
Su
rde
So
no
re
Su
rde
So
no
re
Su
rde
So
no
re
Su
rde
So
no
re
Su
rde
So
no
re
Nes
on
an
te
Oclusive p b t d ch gh k g
Semioclusive ţ ce/ci ge/gi
Constrictive f v s z ş j h
Son
an
te
Ocluzive nazale m n
Lichide Laterale l
Vibrante r Tabel 1.1 - Clasificarea consoanelor după locul şi modul de articulare

Platforme pentru analiza şi generarea semnalului vocal
6
1.2. Sisteme TTS Sistemele TTS (text-to-speech) sunt folosite pentru a sintetiza voce plecând de la un
anumit text. La baza lor stau o multitudine de procese, care includ elemente de prelucrare a
limbajului natural şi prelucrare digitală a semnalelor, şi care sunt absolut necesare pentru a
obţine rezultatul dorit.
În cazul sistemelor TTS unul dintre cele mai importante aspecte este calitatea vocii
sintetizate, aceasta fiind determinată mai ales de inteligibilitate şi naturaleţe.
Inteligibilitatea reflectă nivelul de înţelegere a mesajului transmis. În situaţiile în care
este vorba de un interlocutor uman informaţiile de natură vizuală ajută mult la descifrarea
mesajului. În cazul sistemelor TTS, în absenţa altor indicii vizuale, inteligibilitatea este dată
de claritatea vocii sintetizate şi de efectul de învăţare apărut ca rezultat al folosirii îndelungate
a sistemului.
Naturaleţea măsoară gradul de asemănare între vocea sintetizată şi vocea umană.
Alte atribute de natură tehnică utilizate pentru evaluarea calitativă a unui sistem TTS
sunt:
1. Întârzierea: Timpul necesar unui sistem TTS din momentul în care a primit o
comandă până când vocea este sintetizată. Această caracteristică este foarte
importantă pentru sistemele interactive (în mod uzual decalajul trebuie să fie sub
200ms).
2. Memoria ocupată: Pentru sinteza bazată pe reguli, nivelul de memorie ocupat este
mic în comparaţie cu sistemele concatenative care necesită de sute de ori mai multă
memorie (Huang et al., 2001).
3. Resurse ocupate: Gradul de ocupare al sistemului pe care rulează aplicaţia TTS în
timpul procesului de sinteză, este un factor important când se doreşte sinteza
simultană a mai multor texte pe un singur calculator (cum este cazul sistemelor
client-server).
4. Viteză variabilă: În anumite cazuri se poate cere posibilitatea de a controla viteza de
pronunţie a cuvintelor. Lipsa acestei facilităţi este un impediment pentru sistemele
bazate pe concatenare în care nu se pot modifica segmentele acustice preînregistrate.
În astfel de sisteme, se poate obţine o viteză variabilă doar dacă există un număr
mare de înregistrări, la viteze diferite.
Exită o serie de metode propuse de-a lungul anilor pentru sinteza vorbirii. Alegerea uneia
dintre ele determină implicit valorile atributelor enumerate mai sus. Metodele pot fi
clasificate, după modul în care este obţinut semnalul vocal, în două categori: sintetizatoare
bazate pe reguli şi sintetizatoare bazate pe corpus.
Sinteza formantică şi sinteza articulatorie intră în categoria sintetizatoarelor bazate pe
reguli. Sinteza formantică modelează frecvenţa fundamentală şi frecvenţele formanţilor după
un set de reguli, utilizând un set de filtre aplicate pe trenurile de impulsuri (zonele sonore)
sau pe zgomot alb (zonele nesonore) şi modificând parametrii filtrelor pentru a modela
elementele prozodice. Sinteza articulatorie modelează toate efectele fiziologice implicate în
formarea semnalului vocal.

Platforme pentru analiza şi generarea semnalului vocal
7
Sinteza concatenativă şi sinteza parametrică statistică intră în categoria
sintetizatoarelor bazate pe corpus.
Sinteza concatenativă foloseşte segmente acustice extrase din vorbirea naturală pe care le
concatenează pentru a obţine vocea sintetizată. Inventarul şi tipul unităţilor folosite în sinteza
concatenativă înfluenţează domeniul în care sistemele TTS pot fi aplicate. Din punct de
vedere al adaptării la un anumit domeniu, sinteza concatenativă poate fi clasificată în
specializată sau generală. Din punct de vedere al intervenţiei asupra intervalului acustic
sinteza concatenativă poate fi clasificată în sinteză care modifică segmentele acustice şi în
sinteză concatenativă care nu modifică modifică segmentele acustice. În continuare sunt
prezentate avantajele şi dezavantajele acestor tipuri de sinteză concatenativă (Huang et al.,
2001):
1. Sinteza concatenativă specializată pe un anumit domeniu se aplică pentru un inventar
limitat de propoziţii ce urmează a fi sintetizate. Această abordare are rezultate bune
din punct de vedere al inteligibiliăţii şi naturaleţii vocii, însă numărul mic de
segmente acustice preînregistrate face ca acest tip de sinteză să nu poată fi utilizat
pentru un sistem generic. Acest tip de sistem TTS concatenativ este cel folosit în
majoritatea sistemelor de navigaţie GPS.
2. Sinteza concatenativă fără modificarea segmentelor acustice este utilă în cazul în care
este vorba de un sistem TTS specializat pe un anumit domeniu deoarece se poate
stabili apriori prozodia necesară pentru diferitele segmentele acustice şi acestea pot fi
înregistrate ca atare. Dacă se încearcă folosirea acestei metode într-un sistem TTS
generic, rezultatele obţinute sunt foarte slabe deoarece elementele prozodice sunt
responsabile atât pentru naturaleţea şi inteligibilitatea vocii cât şi pentru transmiterea
corectă a mesajului.
3. Sinteza concatenativă cu modificarea segmentelor acustice permite o flexibilitate
crescută din perspectiva alegerii candidaţilor pentru concatenare, datorită faptului că
elementele de prozodie pot fi modelate prin modificarea segmentelor acustice
preînregistrate.
Sinteza parametrică statistică foloseşte un corpus preînregistrat din care extrage un set de
parametrii grupaţi după context şi caracteristici prozodice. Cel mai cunoscut sistem care
foloseşte Modele Markov Ascunse pentru modelarea parametrilor este HMM-based Speech
Synthesis System sau H Triple S (HTS) (Zen et al., 2007). Avantajul major al folosirii acestei
metode este dat de faptul că se pot încerca mai multe contururi pentru F0 fără a afecta
naturaleţea vocii obţinute.

Platforme pentru analiza şi generarea semnalului vocal
8
2. Arhitectura sistemelor TTS
Un sistem de sinteză a vorbirii este format din două componente importante:
1. Un modul de prelucrare a limbajului natural (NLP) folosit pentru a obţine o
transcriere fonetică şi a extrage elemente de prozodie.
2. Un modul de prelucrare digitală a semnalului care se ocupă de sinteza vorbirii.
Figura 2.1 reprezintă schema bloc a modulului NLP.
Modul NLP
Analiză text
PreprocesareAnalizor
morfologic
Analizor
contextual
Analizor
prozodic
Transcriere
fonetică
Generare de
elemente de
prosodie
Text DSP
Figura 2.1 - Modul NLP (adaptată după A Short Introduction to Text-to-Speech Synthesis)
De regulă, textul care trebuie sintetizat este iniţial supus unei preprocesări, care elimină
simboluri incompatibile cu sistemul TTS (caractere care nu pot fi transformate în voce, de
exemplu: ‘(‘, ‘)’, ‘`’, ‘[‘) etc., transformă secvenţele de numere în cuvinte, (de exemplu 1002
o mie doi), tratează formule matematice, etc. (Ordean, 2009; Dutoit, 1999) (acest proces
va fi detaliat în capitolul 2.1.1).
Transcrierea fonetică este un pas important în orice sistem TTS, dar acest lucru nu poate
fi realizat fără o adnotare morfologică a cuvintelor (pentru rezolvarea problemei cuvintelor
omografe), lucru realizat automat cu ajutorul unui POS tagger (detaliat în capitolul 2.1.3).
Percepţia sunetelor din punct de vedere fizic este influențată de trei factori importanți:
volumul care este o măsură a intensității sunetului, frecvenței componentei fundamentale a
sunetului cunoscută sub numele de înălțime a vocii și timbrul care reprezintă conținutul
armonic al semnalului. Astfel, impunerea elementelor de prozodie se referă la modificarea
frecvenţei fundamentale, a energiei semnalului şi a duratei de pronunţie (detaliat în capitolul
2.1.4).
2.1. Prelucrarea limbajului natural
2.1.1. Normalizarea textelor
Majoritatea textelor includ abrevieri, dialoguri amestecate cu naraţiune, grafice şi figuri
numerotate, ecuaţii matematice, adrese de e-mail cu caractere speciale, date calendaristice
etc. Normalizarea textului este esenţială în orice sistem TTS, iar problema ei inversă se aplică
în cazul sistemelor de dictare, pentru reconstituirea textului din cuvintele recunoscute.
Procesul de normalizare începe prin identificarea expresiilor şi a tipului acestora
(abreviere, dată, număr etc.) urmată de extinderea textului iniţial prin adăugare de taguri
SNOR (Standard Normalized Orthographic Representation).
În continuare vom prezenta câteva probleme în normalizarea textelor.
a. Caracterul ‘.’ situat la finalul unui cuvânt este un indiciu că grupul de litere precedent
ar putea fi o abreviere sau un acronim. Cu toate acestea el poate fi omis în anumite
cazuri din greşeli de ortografie sau pur şi simplu datorită faptului că anumite

Platforme pentru analiza şi generarea semnalului vocal
9
acronime nu sunt urmate de punct în special dacă ele sunt scrise cu majuscule. Un
astfel de exemplu este regăsit în fragmentul „[...]vor contura imaginea LRC ca
entitate supraindividuală[...]”, în care grupul de litere “LRC” este un acronim pentru
“limba română contemporană” şi rezolvarea este dată de transcrierea fonetică
corespunzătoare (“lerece”) sau expansiunea sa în cuvintele componente. Alte
modalităţi de a detecta acronime sunt:
i. Considerarea cuvintelor din afara vocabularului ca și candidate ale
acestei categorii poate reprezenta o metodă, însă acest lucru nu este
determinist;
ii. Scrierea cu majuscule a literelor unui cuvânt face din acest cuvânt un
candidat bun chiar şi în absenţa caracterului ‘.’. Însă un cuvânt scris
cu majuscule nu este în mod obligatoriu un acronim chiar dacă acesta
este în afara vocabularului. De exemplu, în anumite formulare este
obligatorie scrierea numelor proprii cu majuscule acestea fiind în
general cuvinte din afara vocabularului;
iii. Cuvintele formate doar din consoane sunt atipice în multe limbi,
motiv pentru care există şanse destul de mari ca aceste cuvinte să fie
acronime.
În cazul abrevierilor:
iv. Grupurile de litere aflate la finalul unor valori numerice pot reprezenta
unităţi de măsură (de exemplu “13cm”, unde “cm””centimetri”).
v. Există şi acronime care nu sunt formate din caractere de la ‘a’ la ‘z’
cum este situaţia „ 15” ”, în care caracterul ‘ ” ’ este un simbol pentru
inci.
Chiar şi după identificarea unei abrevieri sau acronim, rămâne problema expansiunii.
O variantă este citirea pe litere a cuvântului aşa cum este cazul „LRC””lerece” dar
acest lucru nu este întotdeanuna satisfăcător mai ales că anumite abrevieri cer
neapărat extinderea lor. În situaţia “[…]dl. George[…]”, un utilizator nu va fi
mulţumit să audă citirea “dele George”, sistemul fiind nevoit să ia decizia de a
extinde abrevierea “dl.” “domnul”. O soluţie în acest sens este utilizarea unei
liste de abrevieri şi acronime, dar şi aici putem avea de-a face cu ambiguităţi. Un
exemplu este grupul de litere “AG” care poate să fie atât o abreviere pentru cuvântul
„argint” cât şi pentru cuvântul “Argeş”.
b. Tratarea numerelor este o altă problemă a sistemelor TTS. Există situaţii în care
numerele au o semnificaţie cantitativă, moment în care normalizarea lor se face
respectând un anumit set de reguli sau cazuri în care ele reprezintă un identificator
(număr de telefon, cod, adresă poştală etc.) caz în care normalizarea acestora trebuie
să respecte alt set de reguli.
i. În situaţia “Sondajul s-a desfăşurat pe un număr de 1247 de
persoane”, grupul de cifre “1247” exprimă o valoare cantitativă şi
normalizarea sau extinderea se face prin grupul de cuvinte ”o mie
douăsute patruzeci şi şapte”.
ii. Pe de altă parte în cazurile “interior 1217” sau “cod de acces 2233”,
grupul de cifire reprezintă un număr de telefon, respectiv un cod. În

Platforme pentru analiza şi generarea semnalului vocal
10
această situaţie este de preferat normalizarea “1217” “unu doi unu
şapte”, “2233” “doi doi trei trei”.
Ambiguităţi pot să apară atât la identificare (de exemplu numerele separate de ‘.’, ‘-‘
sau de ‘/’ pot forma o dată calendaristică, acest lucru fiind discutat în continuare la
punctul c) dar şi la diferenţierea între situaţiile expuse la punctele i şi ii.
c. Tratarea expresiilor de timp este o problemă puţin mai simplă acestea apărând în
general, sub formate bine determinate. O neclaritate intervine în cazul scrierii
restrânse, în care “’11” poate reprezenta atât anul 2011 cât şi 1911, această
informaţie fiind direct dependentă de context. Odată identificate aceste expresii,
regulile de normalizare sunt simple şi bine determinate: ”01.01.2012””întâi
ianuarie două mii doisprezece”, “11:45” “unsprezece patruzeci şi cinci” sau
pentru o naturaleţe mai mare “doisprezece fără un sfert”.
d. La cele prezentate se adaugă tratarea expresiilor matematice, a valorilor monetare,
a formulelor chimice etc.
O parte din cazurile neclare cu care se confruntă un sistem TTS pot fi rezolvate cu
ajutorul tehnicilor de prelucrare a limbajului natural (capitolul 2.1.2).
2.1.2. Analiza morfologică
Analiza morfologică constituie un domeniu de interes pentru prelucrarea limbajului
natural având şi o aplicabilitate directă în sistemele TTS pentru:
a. Determinarea graniţelor dintre propoziţii;
b. Dezambiguizarea omografelor care nu sunt omofone: această problema se
referă la cuvinte cu aceeaşi scriere, dar cu pronunţie diferită. În principiu
aceste cuvinte se diferenţiază prin partea de vorbire asociată, motiv pentru
care în cele mai multe cazuri este suficientă utilizarea unui POS (part-of-
speech) Tagger asupra textului;
c. Idetificarea tipului de propoziţie: acest proces este esenţial pentru stabilirea
elementelor macroprozodice la nivel de propoziţie;
d. Determinarea grupurilor sintactice: este utilă pentru modulul prozodic în
stabilirea lungimii segmentelor şi a duratei pauzelor în vorbire.
2.1.2.1. Determinarea graniţelor dintre propoziţii
Determinarea graniţelor dintre propoziţii nu este un procedeu simplu în principal pentru
că:
- punctul este folosit atât în abrevieri cât şi ca separator între propoziţii;
- cratima se foloseşte ca delimitator între propoziţii dar şi în anumite cuvinte compuse;
- în unele cazuri caractere precum ‘:’, ‘,’, ‘;’ separă ceea ce trebuie privit ca fiind o
propoziţie.
Un algoritm euristic simplu funcţionează în felul următor (Manning şi Schütze, 1999):
- Se pun separatori la întâlnirea ‘.’, ‘? ’, ‘! ’;
- Se descalifică un punct dacă:
o Este precedat de o abreviere recunoscută care în mod normal nu apare ca
şi cuvânt de final;

Platforme pentru analiza şi generarea semnalului vocal
11
o Este precedat de o abreviere cunoscută şi nu este urmat de un cuvânt scris
cu literă mare;
o Se descalifică un ‘?’ dacă este urmat de un cuvânt cu literă mică;
- Se pot luat în considerare şi alţi separatori de propoziţie.
2.1.2.2. Dezambiguizarea omografelor care nu sunt omofone
Omografele neomofone sunt cuvinte cu aceeaşi scriere şi pronunţie diferită. Din acest
motiv este important ca un sistem TTS să poată distinge între formele acestora. Diferenţierea
se face în principal prin partea de vorbire asociată, însă în limba română există variante
verbale ale aceluiaşi cuvânt la timpuri diferite (prezent, imperfect sau perfect simplu) sau
chiar variante substantivale cu sensuri diferite la care tagger-ul s-ar putea să nu aibă
informaţia de discriminare. Câteva exemple se regăsesc în tabelul 2.1.
Pronunţie 1 Pronunţie 2 Explicaţie
abdică abdică
Aceeaşi parte de vorbire abjură abjură
abrogă abrogă
castele castele
boli boli Părţi de vorbire diferite
acele acele Tabel 2.1 Câteva exemple de omografe neomofone
Practic, părţile de vorbire sunt cuvinte care au acelaşi comportament sinctactic. Cele mai
importante părţi de vorbire sunt substantivul, pronumele, verbul şi adjectivul. Cel mai bun
test pentru a verifica dacă un cuvânt aparţine de aceeaşi clasă cu alte cuvinte este testul de
înlocuire: Băiatul cel {cuminte, blond…} este în casă. Pentru stabilirea automată a părţii de
vorbire se aplică POS Tagging-ul care are ca rezultat asocierea unui descriptor morfosintactic
(MSD) fiecărui cuvânt. Acesta este un şir de caractere în care fiecare poziţie corespunde unui
atribut iar caracterul de pe poziţia respectivă indică valoarea atributului:
1. Primul caracter indică partea de vorbire;
2. Următoarele n caractere codează valoarea fiecărui atribut (persoană, număr, gen etc.);
3. Dacă un atribut nu se aplică în cazul respectiv, atunci se foloseşte caracterul ‘-‘.
Pentru codarea lexiconului românesc este necesar un număr de 614 etichete MSD (Tufiş
et al., 2007).
Cuvintele sunt împărţite în două mari categorii: categorii deschise (la care se pot adăuga
mereu cuvinte noi) din care fac parte substantivele, adjectivele și verbele; categoriile
funcţionale sau închise.
În continuare vom prezenta un model statistic de POS Tagging. În acest model privim
secvenţa de tag-uri din text ca pe un lanţ Markovian. El are următoarele două proprietăţi:
Orizont limitat:
Invarianţa în timp: ( | ) ( | )
Asta înseamnă ca tagul unui cuvânt depinde doar de tagul anterior (orizont limitat) şi
dependenţa nu se schimbă în timp (invarianţa în timp). Cu alte cuvinte, dacă probabilitatea

Platforme pentru analiza şi generarea semnalului vocal
12
apariţiei unui verb după un pronume, la începutul propoziţiei este de 0.2%, atunci acest lucru
nu se schimbă în timp, indiferent de tag-urile pe care le asociem.
Notaţii:
= cuvântul de la poziţia i.
= tag-ul de la poziţia i
= cuvintele care apar de la poziţia i până la poziţia i+m
= tagurile care apar de la poziţia i până la poziţia i+m
= cuvântul din lexicon de pe poziţia l
= tag-ul din tagset de pe poziţia j
= numărul de apariţii pentru cuvântul respectiv în corpusul de antrenare
= numărul de apariţii pentru tag-ul respectiv în corpusul de antrenare
= numărul de apariţii pentru primul tag, urmat de al doilea tag
= numărul de apariţii pentru tag-ul respectiv în corpusul de antrenare
T = numărul de tag-uri din corpus
W = numărul de cuvinte din lexicon
n = lungimea propoziţiei
este estimat din frecvenţele relative ale diferitelor tag-uri care urmează altor tag-
uri(ecuaţia 2.1)
( | )
(2.1)
Cu aceste estimări, putem calcula probabilităţile unei secvenţe particulare de taguri. În
practică problema este găsirea celei mai probabile secvenţă de taguri pentru o secvenţă
observabilă de cuvinte. Putem calcula probabilitatea de emisie a unui cuvânt de către o stare
anume a sistemului, prin folosirea estimării Maximum Likelihood:
( | )
(2.2)
Acum, singura problemă este găsirea secvenţei optime , pentru o secvenţă de cuvinte
, aplicând regula lui Bayes:
| )
| )
| )
(2.3)
Pe lângă proprietatea orizontului limitat, se mai fac încă două presupuneri despre
cuvinte:
- Cuvintele sunt independente unul faţă de celălalt;
- Identitatea unui cuvânt depinde doar de tagul său.
| ) ( ) ∏ ( )
( ) ( )
∏
( ) ( )
∏[ ]
Deci formula finală este:

Platforme pentru analiza şi generarea semnalului vocal
13
| ) ∏ [ ]
(2.4)
Algoritmul de antrenare pentru un sistem Markov vizibil, dat fiind un corpus adnotat este
(Manning şi Schutze, 1999):
for all tags do
for all tags do
( | )
end
end
for all tags do
for all words do
( | )
end
end
Un algoritm bun pentru găsirea secvenţei optime de tag-uri pentru o propoziţie de
lungime n este agloritmul Viterbi. Este un agloritm inductiv, în care la fiecare pas, se
păstrează cea mai bună soluţie de până în momentul respectiv.
Pseudocodul este dat în continuare:
for t≠ PUNCT for i:=1 to n step 1 do
for all tags do
[
| | ]
[
| | ]
end
end
for j:=n to 1 step -1 do
end
P(
2.1.3. Transcrierea fonetică
Un element important pentru orice sistem TTS, este reprezentat de transcrierea fonetică.
În cazul limbilor cu ortografie fonetică (un exemplu este limba română) conversia de la litere
la sunete (L2P) este o operaţie simplă, dar pentru alte limbi acest lucru devine mai complicat.
În astfel de situaţii se pot folosi lexicoane însă, indiferent de dimensiunea lor, vor exista
întotdeauna cuvinte în afara vocabularului (OOV) pentru care este nevoie de o metodă
automată de L2P.
Pentru conversia L2P este necesară o metodă de a surprinde acele reguli dependente de
limbă, care fac legătura între litere şi sunete. Regulile pot fi introduse manual de un lingvist
sau pot fi deduse automat dintr-un set de perechi de cuvinte şi transcrieri fonetice ale
acestora. În general algoritmul expectation-maximization (EM) este folosit pentru detectarea
celor mai probabile perechi între litere şi sunete în procesul de aliniere (Black et al. 1998;
Jiampojamarn et al. 2008; Pagel et al. 1998).
O metodă de a obţine transcrierea fonetică a cuvintelor OOV se bazează pe tratarea
acestei probleme ca şi cum ar fi una de POS Tagging. Astfel, litere sau grupuri de litere sunt
tratate ca nişte cuvinte independente. Folosind sisteme Markov se obţin părţi de vorbire, care

Platforme pentru analiza şi generarea semnalului vocal
14
reprezintă de fapt transcrierea fonetică a cuvântului format din concatenarea sirului de
caractere observabil. Rezultatele obţinute pentru limba engleză sunt destul de slabe,
accurateţea la nivel de cuvânt fiind de aproximativ 40% (Taylor, 2005).
O altă abordare posibilă este utilizarea arborilor de decizie, această metodă având
performanţe mai bune în ceea ce priveşte acurateţea, care este de aproximativ 60% pentru
limba engleză (Pagel et al. 1998).
Pentru limba română au exista mai multe abordări în rezolvarea problemei L2P,
folosindu-se rețele neurale (Burileanu et al., 1999b; Josef et al., 2009) sau metode bazate pe
reguli (Toma et al., 2009; Ungureanu et al., 2011)
2.1.4. Sinteza prozodică
Din punct de vedere acustic sinteza prozodică impune modelarea pauzelor, a înălţimii
vocii, a duratei fonemelor şi a energiei semnalului vocal.
Toate aceste elemente sunt foarte importante pentru a transmite mesajul. În cazul unui
vorbitor uman aceste elemente codifică mai mult decât sensul strict al cuvintelor din
propoziție. Ele pot da informații atât despre starea vorbitorului (plictiseală, nervozitate,
entuziasm) cât și despre contextul propoziției. Mai mult, utilizarea incorectă a lor duce la
ambiguități de întelegere a mesajului. Vom reveni asupra aspectelor legate de înțelegerea
mesajului mai târziu în acest capitol.
Informația pe care un sistem TTS o poate folosi în sinteza prozodică se rezumă în
general la elemente superficiale care țin de părțile de vorbire ale cuvintelor, de punctuația
utilizată, de lungimea propozițiilor și foarte rar de context.
Sinteza prozodică are două nivele:
a. La nivel macroprozodic, propozițiile se împart în fraze prozodice. Conturul
frecvenței fundamentale este generat pentru acestea și între ele se pot introduce
pauze, pot avea loc modificări de înălțime a vocii sau lungirea anumitor silabe finale
din cuvinte terminale. Aici se ține cont de punctuația utilizată la finalul propoziției
pentru a stabili tipul acesteia: declarativă, interogativă, exclamativă sau imperativă.
În plus se pot adăuga marcatori pentru scoaterea în evidență a numitor cuvinte.
b. La nivel microprozodic se ține cont de lugimea tipică a fonemelor și de poziția
accentului.
Modulul prozodic combină ieșirile analizatoarelor microprozodic și macroprozodic,
stabilind informația de durată, înălțime și energie pentru fiecare fonem. În anumite cazuri,
unui singur fonem i se pot adăuga mai multe puncte în conturul frecvenței fundamentale.
Sistemele actuale sunt statistice sau bazate pe reguli, cele din urmă regulile putând fi
introduse manual sau deduse dintr-un corpus mare adnotat corespunzător.
În continuare voi prezenta fiecare dintre trasăturile ce trebuie modelate și rolul lor:
a. Înălțimea vocii este cel mai expresiv element de prozodie fiind utilizat pentru a
transmite sentimentele vorbitorului despre ceea ce spune, sau, în anumite limbi chiar
pentru a face diferenţa între cuvinte. De exemplu, în cazul chinezei mandarine există
patru contururi bine definite de tonalităţi utilizate pentru a distinge între cuvinte
(Huang et al.,).
În majoritatea limbilor emoţia, atenţia şi starea vorbitorului pot fi deduse din
elementele de prozodie. Astfel, variaţia foarte mică a tonului în timpul vorbirii,

Platforme pentru analiza şi generarea semnalului vocal
15
indică plictiseală, o stare de nervozitate reprimată sau depresie; vorbirea rapidă
transmite entuziasm etc.
În urma analizei macroprozodice, ținând cont de tipul propozițiilor (declarative,
imperative etc.), se stabilește conturul frecvenței fundamentale. Acestă informație
este combinată cu cea obținută în analiza microprozodică pentru fiecare fonem în
parte.
b. Pauzele joacă un rol important în transmiterea corectă a conținutului unui mesaj. În
general, cuvintele se pronunță legat unul de altul, ele fiind separate de pauze numai
dacă cerințele legate de limbaj impun acest lucru. Scopul principal al modulului
prozodic este de a stabili locul în care trebuie să apară pauzele, durata lor fiind pe loc
secundar. Sistemul nu trebuie să introducă pauze acolo unde nu este cazul, deorece
poate genera ambiguități. Un exemplu de folosire incorectă a pauzelor în vorbire este
dat de mesajul transmis de următoarele două propoziții:
i. “Nu e aici” cu înțelesul că un obiect sau o persoană nu se află în locul
respectiv.
ii. “Nu, e aici” cu înțelesul ca o persoană sau obiect se află în acel loc.
Semnele de punctuație oferă un indiciu bun pentru separarea frazelor prozodice și
introducerea de pauze în vorbire. Cu toate acestea în anumite situații este necesară o
analiză semantică foarte bună pentru a detecta granițele dintre frazele prozodice
nemarcate cu semne de punctuație.
c. Durata fonemelor este de cele mai multe ori legată de conturul lui F0, având în
comun multe atribute care le determină pe amândouă, dar din motive pragmatice cele
două probleme sunt tratate separat (Wang, 1999). Deși o analiză semantică este de
preferat în cazul determinării duratei fonemelor, studiile au arătat că, cel puțin pentru
anumite limbi, o analiză limitată de context este suficientă în majoritatea situaţiilor
pentru a obține rezultate acceptabile (Plumpe și Meredith, 1999). Astfel, se folosește
o fereastră limitată de context, centrată pe fonem, a cărei durată trebuie stabilită și se
ține cont de următoarele atribute: identitatea fonemului, prezența accentului lexical,
fonemul din stânga și fonemul din dreapta.
d. Accentuarea cuvintelor în frază este un fenomen legat de procesul de transmitere
corectă a mesajului. Unele sisteme utilizează pentru determinarea cuvintelor
accentuate un model format din tipul propoziției, partea de vorbire a cuvântului și un
istoric contextual de cuvinte care au fost accentuate înainte.
Un sistem complet de sinteză prozodică pentru limba română, foloseşte metode bazate pe
reguli pentru preprocesarea textelor, silabificare şi modelarea conturului F0, metode statistice
pentru poziţionarea accentului şi utilizează reţele neurale pentru transcrierea fonetică
(Burileanu şi Negrescu, 2006).
2.2. Sinteza vorbirii
2.2.1. Sinteza concatenativă
Metodele de sinteză bazate pe corpus obţin cele mai bune rezultate în materie de
inteligibilitate şi naturaleţe a vocii sintetizate. În sinteza concatenativă, vocea este sintetizată

Platforme pentru analiza şi generarea semnalului vocal
16
prin redarea unor segmente acustice, care sunt selectate din corpus după criterii legate de
context şi prozodie.
Există o serie de elemente care trebuie luate în calcul în momentul în care se construiește
un sistem TTS bazat pe concatenare (Huang et al., 2001):
a. Tipul de unități acustice ce urmează a fi folosit. Astfel, se pot utiliza foneme,
difoneme (unități acustice fomate din perechi de foneme alăturate), trifoneme
(trei foneme alăturate), silabe, cuvinte sau propoziții.
b. Modul în care urmează să se realizeze inventarul acustic în funcție de un set
de propoziții deja existent (nu în toate situațiile se pot obține suficiente unități
acustice); sau în cazul în care se fac înregistrări noi, trebuie stabilit ce anume
se va înregistra.
c. Cum se va alege cea mai bună secvență de unități acustice pentru a se potrivi
atât cu textul cât și cu prozodia acestuia.
d. Cum se va modifica prozodia segmentelor alese pentru a obține rezultatul
dorit.
Considerând că inventarul fonetic al unei limbi are dimensiunea N, numărul de difoneme
necesar pentru a sintetiza orice cuvânt din limba țintă este teoretic N2, iar în cazul
trifonemelor N3. Cu toate acestea numărul de astfel de unități este mult mai mic, deoarce nu
toate combinațiile sunt posibile. De exemplu pentru limba română se poate utiliza un inventar
redus de 630 de difoneme (Burileanu și Negrescu, 2006).
În momentul concatenării pot apărea anumite discontinuități la nivel spectral sau
prozodic care nu pot fi evitate. Pentru a reduce efectul produs de acestea, este recomandată
folosirea unor unități acustice cu lungime mai mare. Este de menționat că o discontinuitate la
nivelul unei vocale este mai observabilă decât la nivelul unei consoane fricative, iar o
discontinuitatea aflată în interiorul unei silabe este mai perceptibilă decât o discontinuitate
aflată la granița dintre două silabe.
Generalitatea unui sistem TTS se referă la posibilitatea utilizării lui în sinteza unui text
arbitrar. De exemplu, într-un sistem de asistare GPS indicațiile pe care acesta le dă se rezumă
la câteva tipuri de propoziții, direcții și numere. În astfel de situații, unitățile acustice alese
pot să fie fraze sau cuvinte.
Alegerea optimă a unităţilor folosite în concatenare se face în general cu algoritmul
Viterbi, încercând minimizarea unei funcţii formată din două costuri: costul de model şi
costul de concatenare. Costul de model este calculat în funcţie de diferenţele prozodice ale
segmentului folosit şi cele impuse de context, iar costul de concatenare măsoară cât de bine
se vor potrivi două segmente acustice adiacente. În practică, costul de concatenare are un rol
foarte important în asigurarea calităţii vocii obţinute, fiind obiectul mai multor studii de-a
lungul anilor (Pantazis et al. 2005; Black şi Hunt, 1996; Vepa şi King, 2004).
2.2.2. Algoritmi de modificare prozodică a segmentelor acustice
Datorită variației prozodice foarte mari, de la un context la altul, unitățile acustice
extrase în momentul creării bazei de date nu sunt întotdeauna potrivite pentru sinteza unui
anumit text arbitrat. Pentru a compensa acestu lucru este necesară modificarea energiei, a
duratei și a înălțimii vocii pentru segmentele utilizate în concatenare.
Platforme pentru analiza şi generarea semnalului vocal
17
Modificarea energiei se realizează direct prin operația de înmulțire. Pentru durată și
înălțime lucrurile sunt mai complicate. Algoritmii descriși în continuare sunt folosiți pentru
modificarea prozodică a segmentelor acustice folosite în concatenare (Huang et al., 2001).
SOLA
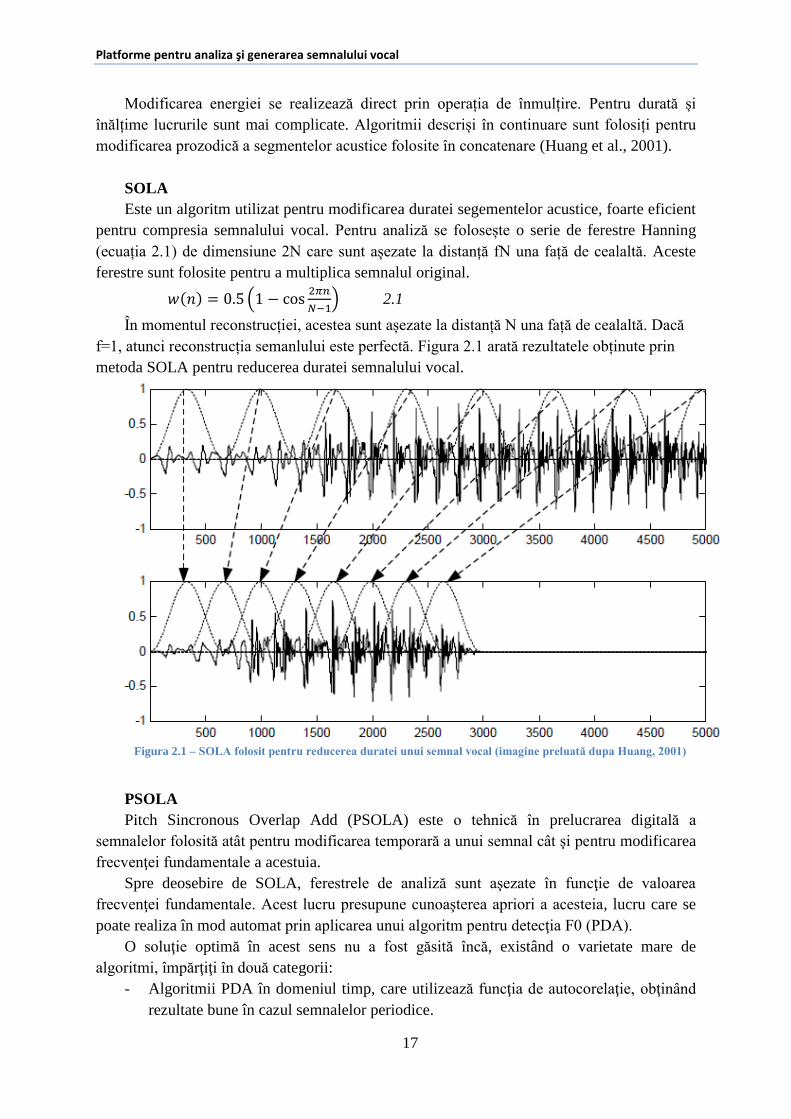
Este un algoritm utilizat pentru modificarea duratei segementelor acustice, foarte eficient
pentru compresia semnalului vocal. Pentru analiză se folosește o serie de ferestre Hanning
(ecuația 2.1) de dimensiune 2N care sunt așezate la distanță fN una față de cealaltă. Aceste
ferestre sunt folosite pentru a multiplica semnalul original.
(
) 2.1
În momentul reconstrucției, acestea sunt așezate la distanță N una față de cealaltă. Dacă
f=1, atunci reconstrucția semanlului este perfectă. Figura 2.1 arată rezultatele obținute prin
metoda SOLA pentru reducerea duratei semnalului vocal.
Figura 2.1 – SOLA folosit pentru reducerea duratei unui semnal vocal (imagine preluată dupa Huang, 2001)
PSOLA
Pitch Sincronous Overlap Add (PSOLA) este o tehnică în prelucrarea digitală a
semnalelor folosită atât pentru modificarea temporară a unui semnal cât şi pentru modificarea
frecvenţei fundamentale a acestuia.
Spre deosebire de SOLA, ferestrele de analiză sunt aşezate în funcţie de valoarea
frecvenţei fundamentale. Acest lucru presupune cunoaşterea apriori a acesteia, lucru care se
poate realiza în mod automat prin aplicarea unui algoritm pentru detecţia F0 (PDA).
O soluţie optimă în acest sens nu a fost găsită încă, existând o varietate mare de
algoritmi, împărţiţi în două categorii:
- Algoritmii PDA în domeniul timp, care utilizează funcţia de autocorelaţie, obţinând
rezultate bune în cazul semnalelor periodice.

Platforme pentru analiza şi generarea semnalului vocal
18
- Algoritmii PDA în domeniul frecvenţă, care funcţionează în general prin analiza
spectrală a semnalului.
Înainte de aplicarea algoritmului PSOLA pentru un segment acustic trebuie stabilit dacă
acesta este vocalizat sau nevocalizat.
În cazul în care semnalul este vocalizat el se poate scrie ca o funcţie dependentă de
periodicitatea frecvenţei fundamentale F0 (ecuaţia 2.2).
∑ (2.2)
[ ] sunt epoci ale semnalului, astfel încât diferenţa dintre două epoci adiacente
[ ] [ ] să aibă valoarea lui F0 la momentul [ ] ca număr de eşantioane. Funcţia
este obţinută prin ferestruirea semnalului original (ecuaţia 2.3).
(2.3)
Alegerea tipului de fereastră precum şi lungimea acesteia se face în funcţie de condiţia
impusă de ecuaţia 2.4. Acestă condiţie este respectată dacă se utilizează fereastra Hanning cu
lungime [ ] (care este, de fapt, de două ori valoarea frecvenţei
fundamentale).
∑ ( ) (2.4)
Scopul final este de a sintetiza un semnal care are aceleaşi caracteristici spectrale ca
şi dar cu alte valori pentru F0 şi durată. Acest lucru se face prin înlocuirea valorilor
folosite la pasul de analiză cu , care sunt valorile dorite pentru semnalul sintetizat
(ecuaţia 2.5).
∑ (2.5)
Pentru zonele nevocalizate din semnal, valorile sunt distribuite uniform peste
eşantioane, în aşa fel încât spaţierea să se facă la intervale mai mici de 10ms. În cazul în care
se doreşte modificarea duratei în timp a segmentelor, acestea trebuie repetate de mai multe
ori şi pentru a evita o periodicitate creată artificial, acestea se inversează în timp.
MBROLA
Multiband Resynthesis Overlap and Add este un alt algoritm de sinteză a vorbirii, care
lucrează în domeniul timp şi care are avantajul de a netezi discontinuităţile spectrale care apar
în cazul TD-PSOLA. Situaţia optimă pentru algoritmul PSOLA este atunci când toate
ferestrele de analiză sunt identice (Dutoit şi Leich, 1993). Pentru ca acest lucru să fie posibil,
baza de date trebuie să aibă următoarele proprietăţi:
a. Toate cuvintele trebuie pronunţate cu un ton constant;
b. Interpolarea spectrală între segmentele concatenate trebuie să fie uşor de realizat din
punct de vedere computaţional.

Platforme pentru analiza şi generarea semnalului vocal
19
Pentru a rezolva cerinţele impuse mai sus, MBROLA resintetizează segmentele acustice
înainte de utilizarea acestora în sinteză. Acest lucru se face în faza de creare a bazei de date,
în aşa fel încât, în momentul concatenării, operaţiile asupra segmentelor să fie minime ca
număr şi complexitate (figura 2.2)
Analiză MBE
Proces de rearmonizare
Segment Vocalic
R sint ză s gm nt
Stop (segmente
MBROLA)
Start (segmente acustice)
Figura 2.2 –resinteza MBROLA
Fazele semnalelor sunt resetate în momentul resintezei iar calitatea vocii sintetizate
depinde foarte mult de strategia folosită în acest pas. În cazul în care se folosesc valori
constante sau distribuite liniar va apărea un efect nedorit de voce metalică. De asemenea, s-a
arătat că rezultate bune se obţin dacă frecvenţele înalte sau joase sunt lăsate nemodificate (cu
faza iniţială neschimbată) (Dutoit şi Leich, 1993).
2.2.3. Metode de evaluare a sistemelor TTS
Evaluarea și compararea sistemelor TTS se face în funcție de inteligibilitatea, naturalețea
și aplicabilitatea acestora în diferite domenii. Aceste atribute sunt imposibil de măsurat în
mod automat, fiind nevoie de implicarea unor subiecți umani în procedura de testare. Aceștia
sunt rugați să asculte un set de silabe, cuvinte sau propoziții și să răspundă la un set de
întrebări.
De menționat că există factori subiectivi care pot afecta rezultatele:
- În cazul testelor de inteligibilitate, reevaluarea unui sistem de către același grup de
subiecți duce la creșterea artificială a rezulatelor, chiar dacă setul de date este
schimbat;
- Stresul sau distragerea atenției pot afecta în mod negativ rezultatele.
Metode de testare a inteligibilității pentru segmente izolate
Aceste metode au în vedere inteligibilitatea unui singur segment izolat. Există două
grupuri de teste utilizate mai des în acest scop și anume testele bazate pe rimă și testele pe
cuvinte fără sens. Primul grup este mai avantajos prin faptul că numărul de stimuli este redus,

Platforme pentru analiza şi generarea semnalului vocal
20
procedura de testare fiind redusă ca timp și utilizatorii nu au nevoie de instruire înainte de a
participa la evaluarea sistemului TTS (Jekosh, 1993). În plus efectele date de antrenarea
subiecților umani pentru setul de date dat sunt neglijabile iar rezultatele sunt utile în a ajuta la
localizarea problema și a observa care foneme crează confuzie.
a. Diagnostic Rhyme Test (DRT) a fost introdus de Fairbanks în 1958 și
folosește un set izolat de cuvinte care diferă doar prin prima consoană.
Utilizatorul asculă cuvinte monosilabice pronunțate izolat și alege ceea ce a
auzit dintr-o listă de două variante posibile.
b. Modified Rhyme Test (MRT) este o extensie a DRT folosit pentru a stabili
inteligibilitatea atât pentru prima cât și pentru ultima consoană. Testul constă
într-un număr de 50 de grupuri de câte 6 cuvinte. Utilizatorul ascultă fiecare
grup de șase cuvinte rostite separat și marchează apoi într-o listă cu variante
multiple cuvintele pe care consideră că le-a auzit. Primele 3 cuvinte sunt
utilizate pentru stabilirea inteligibilității primei consoane, iar ultimile 3
cuvinte pentru inteligibilitatea ultimei consoane. Vocea umană primeşte un
scor de aproximativ 99% la testul MRT, iar cele mai bune sistem TTS au
valori situate între 70% şi 95% (Huang et al., 2001).
c. Diagnostic Medial Consonant Test (DMCT) este tot un test bazat pe cuvinte
care rimează numai că în acest caz ele sunt bisilabice și sunt alese în așa fel
încât să difere printr-o singură fonemă mediană.
d. Standard Segmental Test (SST) foloseşte liste de cuvinte fără sens de forma
consoană-vocală, vocală-consoană şi vocala-consoană-vocală. Utilizatorul
trebuie să completeze într-un formular consoana lipsă din cuvântul pe care
tocmail l-a ascultat.
e. Cluster Identification Test (CLID) este un test în care vocabularul folosit nu
este predefinit. Transcrierea fonetică a cuvintelor este generată automat după
o structură data (de exemplu CVCCV) apoi este convertită în grafeme
(deorece majoritatea sistemelor TTS nu acceptă decât acest mod de a
introduce datele). Utilizatorii ascultă cuvintele sintetizate şi completează ce
au auzit într-un formular cu răspuns deschis (pot scrie răspunsul atât la nivel
grafemic cât şi fonemic).
f. Phonemically Balanced Word Lists (PB) este un test care foloseşte o listă de
cuvinte monosilabice. Lista este balansată din punct de vedere fonetic
deoarece cuvintele sunt alese în aşa fel încât să aproximeze relativ numărul de
apariţii al fiecărui fonem specific limbii.
Metode de testare a inteligibilităţii unui cuvânt la nivel de propoziție
Aceste teste sunt folosite pentru a măsura inteligibilitatea unui sistem TTS cu ajutorul
unor propoziţii alese în aşa fel încât cuvintele din ele să respecte frecvenţa relativă de apariţie
specifică limbii ţintă.
a. Harvard Psychoacoustic Sentences este un set prestabilit de 100 de propoziţii
folosite pentru a testa inteligibilitatea unui cuvânt în frază. Propoziţiile sunt
alese în aşa fel încât anumite secvenţe de foneme să respecte frecvenţa de
apariţii specifice limbii engleze. Dezavantajul constă în faptul că este un set

Platforme pentru analiza şi generarea semnalului vocal
21
închis de propoziţii şi efectul de învăţare nu poate fi ignorat în momentul în
care se foloseşte acelaşi grup de oameni.
b. Haskins Sentences este un set de propoziţii asemănător cu cel de la Harvard
cu singura diferenţă că aceste propoziţii sunt lipsite de sens şi cuvântul care
nu se înţelege corect nu poate fi dedus din context.
c. Semantically Unpredictable Sentences (SUS) este tot un test de inteligibilitate
numai că în acest caz cuvintele pe care se face testul sunt alese dintr-un set de
candidaţi formând astfel la fiecare testare propoziţii noi. Propoziţiile sunt de
forma: subiect-verb-adverb, subiect-verb-obiect, adverb-verb-obiect, adverb
interogativ-verb-obiect, subiect-verb-obiect complex.
Metode de evaluare la nivel prozodic
Inteligibilitatea unui segment sau a unui cuvânt nu garantează percepeţia corectă a
mesajului transmis, de aceea testele menţionate până acum sunt utile doar din anumite puncte
de vedere. Mai mult, o rată de inteligilitate de 100% nu este obligatorie pentru ca un sistem
să fie considerat inteligibil. O metodă completă de testare a unui sistem TTS trebuie să aibă
în vedere şi evaluarea din punct de vedere prosodic al acestuia. Testul funcţionează în felul
următor: un set de propoziţii sunt sintetizate pentru forma imperativă, neutră şi interogativă,
apoi utilizatorii sunt puşi să asculte propoziţiile şi să aleagă tipul fiecăreia.
Metode de evaluare generală a sistemelor TTS
Testele pentru evaluarea generală a sistemelor TTS au la bază Mean Opinion Score
(MOS). Scorul MOS este o medie aritmetică a notelor date de un grup de experți umani
pentru o serie de propoziții sintetizate. Iniţial, acest tip de evaluare a fost folosit pentru
sistemele de compresie a vocii.

Platforme pentru analiza şi generarea semnalului vocal
22
3. Aplicaţii de sinteză a vorbirii
3.1. Aplicaţii comerciale
Ivona este un sistem TTS multilingv cu suport pentru limba română. Această aplicație
folosește o bază de date foarte mare de unități ne-uniorme și un algoritm numit Unit Selection
Algorithm with Limited Time-scale Modifications (USLTMS). Scorul MOS raportat de către
autori pentru IVONA este de 3.9 (Kaszczuk and Osowski, 2006).
Baum Engineering a dezvoltat sistemul TTS Moromete despre care nu se dau prea
multe detalii dar, la o primă ascultare pare să fie vorba de sinteză concatenativă cu
MBROLA.
3.2. Aplicaţii gratuite
Google TTS este un API introdus de Google de curând pentru a permite sinteza vorbirii.
Momentan motorul se poate folosi gratuit însă este limitat la un număr de 100 de caractere. În
spate Google foloseşte mai multe aplicaţii TTS în funcţie de limba ţintă, vocea pentru limba
română fiind obţinută prin sinteză formantică. Evaluarea acestui sistem nu a fost posibilă din
cauza faptului ca ultima consoană nu se auzea niciodată.
MBROLA este o aplicaţie care permite sinteză concatenativă cu un inventar de
difoneme şi foloseşte algoritmul cu acelaşi nume în prelucrarea segmentelor acustice.
MBROLA nu este un sistem TTS complet deoarece modulul de prelucrare a limbajului
natural lipseşte. Pentru a putea sintetiza voce, utilizatorul trebuie să introducă datele în
formatul acceptat de aplicaţie:
1. Numele fonemului
2. Durata în milisecunde a acestuia
3. Un set de valori reprezentând valorile de referinţă pentru înălţimea vocii şi durata lor
relativă.
Nefiind un sistem TTS complet, am ales să nu evaluam MBROLA ci mai degrabă un
produs care foloşte sintetizatorul MBROLA şi introduce un modul de prelucrare a limbajului
natural numit Phobos TTS.
Universitatea Tehnică din Cluj-Napoca împreună cu Centre for Speech Technology
Research a creat primul sistem TTS pentru limba română bazat pe Modele Markov Ascunse
utilizând sistemul HTS. Aplicaţia foloseşte pentru antrenare corpusul Romanian Speech
Synthesis (RSS) (Stan et al., 2010)
3.3. Evaluarea sistemelor
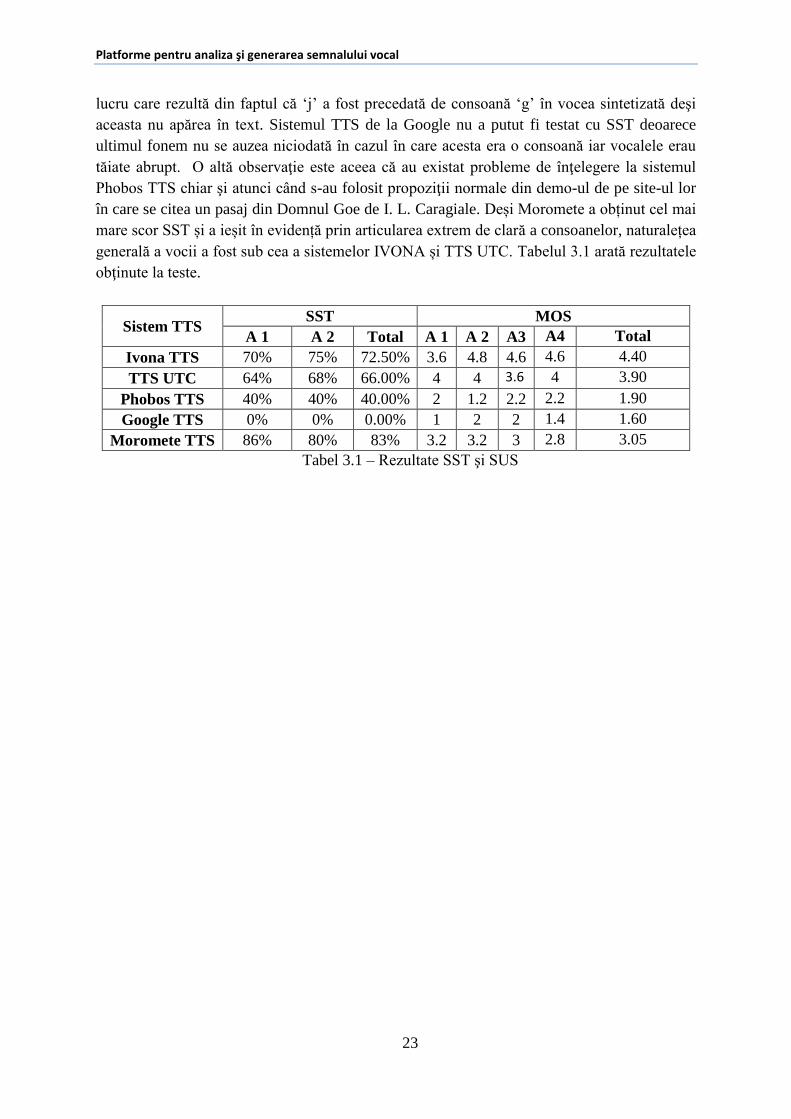
Pentru evaluarea sistemelor TTS am folosit două criterii şi anume Standard Segmental
Test (SST) şi scorul MOS. În cazul SST am folosit 50 de cuvinte fără sens de forma CVC,
VCV iar pentru scorul MOS au fost folosite notele date de 4 utilizatori pentru 10 propoziţii.
Ivona şi sistemul TTS de la UTC au obţinut scoruri comparabile la testul SST, însă acestea au
fost departe de scorul obținut de Moromete (83%). O problemă constatată la sistemul Ivona,
care a redus scorul SST obţinut, este pronunţia greşită a literei ‘j’ situată la începutul
cuvintelor. Această problemă este aparent dată de segmentarea incorectă a unităţilor acustice,
Platforme pentru analiza şi generarea semnalului vocal
23
lucru care rezultă din faptul că ‘j’ a fost precedată de consoană ‘g’ în vocea sintetizată deşi
aceasta nu apărea în text. Sistemul TTS de la Google nu a putut fi testat cu SST deoarece
ultimul fonem nu se auzea niciodată în cazul în care acesta era o consoană iar vocalele erau
tăiate abrupt. O altă observaţie este aceea că au existat probleme de înţelegere la sistemul
Phobos TTS chiar şi atunci când s-au folosit propoziţii normale din demo-ul de pe site-ul lor
în care se citea un pasaj din Domnul Goe de I. L. Caragiale. Deși Moromete a obținut cel mai
mare scor SST și a ieșit în evidență prin articularea extrem de clară a consoanelor, naturalețea
generală a vocii a fost sub cea a sistemelor IVONA și TTS UTC. Tabelul 3.1 arată rezultatele
obţinute la teste.
Sistem TTS SST MOS
A 1 A 2 Total A 1 A 2 A3 A4 Total
Ivona TTS 70% 75% 72.50% 3.6 4.8 4.6 4.6 4.40
TTS UTC 64% 68% 66.00% 4 4 3.6 4 3.90
Phobos TTS 40% 40% 40.00% 2 1.2 2.2 2.2 1.90
Google TTS 0% 0% 0.00% 1 2 2 1.4 1.60
Moromete TTS 86% 80% 83% 3.2 3.2 3 2.8 3.05
Tabel 3.1 – Rezultate SST şi SUS

Platforme pentru analiza şi generarea semnalului vocal
24
4. Concluzii În prima parte a lucrării am evidenţiat aspecte legate de modul de producere al vorbirii şi
caracteristici, din punct de vedere acustic, ale sunetelor din limba română. De asemenea, am
dat o atenţie deosebită modulului de prelucrare a limbajului natural şi am explicat paşii ce
trebuie urmaţi în prelucrarea textului înainte ca vocea să fie sintetizată de către modulul DSP.
Am evidenţiat problemele legate de normalizarea textului, dezambiguizarea omografelor
neomofone, transcrierea fonetică, detectarea accentului, generarea conturului F0 şi stabilirea
locului unde trebuie plasate pauzele în vorbire. Acolo unde a fost cazul am menţionat
soluţiile propuse pentru limba română şi unde s-a putut am scos în evidenţă rezultatele
obţinute de aceastea.
În ceea ce priveşte metodele de sinteză a vorbirii am pus accent pe o serie de algoritmi
utilizaţi pentru modelarea prozodiei în cazul sintezei concatenative. De menţionat este faptul
că nivelul de inteligibilitate şi naturaleţe al unui sistem TTS nu este dependent doar de
modulul DSP, prelucarea limbajului natural şi sinteza prozodică jucând un rol foarte
important în acest sens.
Mai mult, fără o modelare prozodică foarte bună, chiar dacă o voce sintetică este
inteligibilă şi naturală acest lucru nu garantează transmiterea corectă a mesajului din text. Din
aceste considerente, am ales să prezint şi o serie de metode de evaluare a sistemelor TTS
împărţite în: metode de testare a inteligibilității pentru segmente izolate; metode de testare a
inteligibilităţii unui cuvânt la nivel de propoziție; metode de evaluare la nivel prozodic şi
metode de evaluare generală.
În finalul lucrării am evaluat cinci astfel de sisteme pentru limba română: Ivona, UTC,
Phobos, Google şi Moromete. După cum s-a putut observa din rezultate, este importantă
folosirea combinată a mai multor teste din categorii diferite, pentru a surprinde calitatea unui
TTS. Scorul Moromete pentru testul SST a fost de departe cel mai bun rezultat obţinut de
vreun sistem. Cu toate acestea, scorul MOS, care reflectă calitatea generală a sistemului TTS
a scos în evidenţă sistemele Ivona şi UTC.

Platforme pentru analiza şi generarea semnalului vocal
25
5. Referinţe bibliografice
1. Black, A., Lenzo, K. şi Pagel, V. Issues in building general letter to sound rules.
ESCA Speech Synthesis Work-shop, Jenolan Caves, 1998.
2. Burileanu, D., Contribuţii la sinteza vorbirii din text pentru limba română. Teză
doctorat, 1999
3. Burileanu, D. şi Dan, C., Principii şi tehnici de bază în prelucrarea digitală a
semnalelor. Editura Printech, 2000, ISBN 973-652-127-3
4. Burileanu, D., Sima, M., şi Neagu, A. (1999b). A phonetic converter for speech
synthesis in romanian. Proceedings of the XIVth Congress on Phonetic Sciences
(ICPhS), San Francisco, CA, vol. 1, pp. 503–506, 1999
5. Burileanu, D. şi Negrescu, C. Prosody modeling for an embedded TTS system
implementation. 14th European Signal Processing Conference (EUSIPCO 2006),
Florence, Italy, September 4-8, 2006
6. Burileanu, D., Negrescu, C., Prosody Modeling for an Embedded TTS System
Implementation. Proceedings of the 14th
European Signal Processing Conference
EUSIPCO 2006, Florence, pp. 715–718, 2006
7. Dutoit, T. şi Leich, H., MBR-PSOLA: Text-To-Speech Synthesis based on an MBE
Re-Synthesis of the Segments Database. Speech Communication, Elsevier Publisher,
November 1993, vol. 13.
8. Dutoit, T. A Short Introduction to Text-to-Speech Synthesis,
http://tcts.fpms.ac.be/synthesis/, accesat la 12.07.2011
9. Fant, G., Acoustic Theory of Speech Production., Mouton De Gruyter, 1970, ISBN
90-279-1600-4
10. Huang, X., Acero, A., Hon, H.W. Spoken Language Processing. Prentice-Hall,
Englewood Cliffs, NJ, 2001
11. Hunt, A., Black, A. (1996). Unit selection in a concatenative speech synthesis system
using a large speech database. Proceedings of IEEE int. conf. acoust., speech, and
signal processing (vol. 1, pp. 373–376).
12. Jiampojamarn, S., Cherry, C. şi Kondrak, G. Joint processing and discriminative
training for letter-to-phoneme conversion. Proceedings of ACL-2008: Human
Language Technology Conference, pp. 905–913, Columbus, Ohio, June, 2008.
13. Jozsef, D., Ovidiu, B. şi Gavril, T. Automated grapheme-to-phoneme conversion
system for Romanian. Speech Technology and Human-Computer Dialogue (SpeD),
2011
14. Kaszczuk, M. şi Osowski, L. Evaluating Ivona Speech Synthesis System for Blizzard
Challenge 2006, Blizzard Workshop, 2006.
15. Manning, C. D., şi Schutze, H. Foundations of statistical natural language
processing. Cambridge Massachusetts: MIT Press, 1999.
16. Ungurean, C., Burileanu, D., Popescu, V. şi Derviş, A. Hybrid syllabification and
letter-to phone conversion for tts synthesis. U.P.B. Sci. Bull., Series C, Vol. 73, Iss.
3, ISSN 1454-234x, 2011

Platforme pentru analiza şi generarea semnalului vocal
26
17. Ordean, M., Saupe, A., Ordean, M., Gorgan, D. Componentele unui sistem de sinteza
text-vorbire. A 6-a Conferinta Nationala de Interactiune Om-Calculator, RoCHI2009,
Cluj-Napoca, Romania, 2009
18. Pagel, V., Lenzo, K. and Black, A., “Letter to sound rules for accented lexicon
compression”, International Conference on Spoken Language Processing, Sydney,
Australia, 1998
19. Pantazis, Z., Stylianou, Y., şi Klabbers, E. Discontinuity detection in concatenated
speech synthesis based on nonlinear speech analysis. Proc. of Interspeech 2005,
Lisbon, Portugal, 2005, pp. 2817-2820
20. Stan, A., Yamagishia, J., Kinga, S. şi Aylettc, M. The Romanian Speech Synthesis
(RSS) corpus: building a high quality HMM-based speech synthesis system using a
high sampling rate. 2010
21. Taylor, P. Hidden Markov Models for grapheme to phoneme conversion. Proceedings
of the 9th European Conference on Speech Communication and Technology, 2005.
22. Toma, S. A., Munteanu, D.P. Rule-Based Automatic Phonetic Transcription for the
Romanian Language. Computation World: Future Computing, Service Computation,
Cognitive, Adaptive, Content, Patterns, 2009
23. Vepa, J., & King, S. Join cost for unit selection speech synthesis. Text to speech
synthesis: new paradigms and advances. New York: Prentice Hall (pp. 35–62), 2004.
24. Zen, H., Tokuda, K., Masuko, T., Kobayashi, T., Kitamura, T. A hidden semi-Markov
model-based speech synthesis system. IEICE Trans. Inf. Syst. E90-D (5), 825–834,
2007.