călin-adrian comes 2010 -...
TRANSCRIPT

1
BAZE DE DATE
Călin-Adrian COMES
2010

2
1. Arhitectura unei baze de date
În prezent informaţia este o componentă esenţială în desfăşurarea oricărei activităţi deoarece influenţează procesul de luare a
deciziilor; acestea trebuie să fie mai bune decît cele care s-ar lua în absenţa informaţiei. De aceea aceasta trebuie să fie disponibilă în timp util, să fie corectă, coerentă, neredundantă. Cum satisfacem aceste cerinţe în condiţiile în care volumul datelor care trebuie prelucrate este în continuă creştere? Sînt deci necesare sisteme care să asigure culegerea, memorarea, organizarea, regăsirea şi prelucrarea acestora. Aceste activităţi sînt posibile în prezent şi în
informatică ele sînt legate nemijlocit de noţiunea de baze de date.
Introducere
În cadrul acestui curs se prezintă fundamentele bazelor de date. Toate expunerile au un caracter general şi nu fac referire la vreun SGBD
particular. Vom încerca să dăm în acelaşi timp o notă practică tuturor expunerilor, aceasta pentru a-i ajuta pe viitorii proiectanţi de aplicaţii de baze de date să găsească soluţii cît mai bune pentru problemele care se pun. Structura cursului este următoarea: 1) arhitectura unei baze de date;
2) modelul relaţional: noţiunile de domeniu, atribut, relaţie, cheie primară, cheie externă; probleme legate de integritatea datelor; modelul entitate-legătură; 3) limbajul SQL (partea I): descrierea datelor şi prelucrarea acestora: inserare, modificare, ştergere; 4) limbajul SQL (partea a II-a): instrucţiunea Select SQL - selecţii
dintr-o singură tabelă, din mai multe tabele şi funcţii de agregare;

3
5) proiectarea bazelor de date: dependenţe funcţionale şi probleme cauzate de acestea; primele trei forme normale.
Avantajele bazelor de date
O bază de date este o colecţie de date persistente utilizate de sistemul de aplicaţii al unei instituţii. Colecţia de date este concretizată printr-un ansamblu de fişiere pe disc care au o anumită stabilitate în timp, deci care nu sînt date de intrare, de ieşire sau de manevră. Un sistem de gestiune a bazelor de date (în engleză DBMS: DataBase
Management System) este un pachet unitar de programe care oferă facilităţi de descriere a datelor şi de prelucrare a acestora. Aplicaţiile de baze de date se caracterizează în primul rînd prin faptul că majoritatea prelucrărilor care se fac sînt cele de memorare şi regăsire a datelor, efectuate asupra unor volume mari de date. În general operaţiile de prelucrare sînt destul de simple, spre deosebire de alte domenii ale informaticii - cum este de exemplu domeniul tehnic unde predomină operaţiile de calcul care au o complexitate
destul de ridicată. Cea mai frecventă operaţie care apare într-o aplicaţie de baze de date este aceea de consultare a datelor: într-adevăr, pentru ce creăm o bază de date dacă nu o folosim? Alte operaţii care apar pe lîngă cea de consultare: introducerea unor noi date, modificarea unor date existente, ştergerea unor date perimate. Prin organizarea datelor în baze de date se asigură centralizarea acestora, fapt care conduce la o serie de avantaje:
1) Reducerea redundanţei datelor. Dacă fiecare aplicaţie lucrează cu fişiere proprii este posibil ca aceleaşi date să apară de mai multe ori în fişiere diferite. În cazul centralizării datelor administratorul bazei de date poate organiza datele în aşa fel încît toate aplicaţiile să folosească aceleaşi fişiere. Astfel se obţine o economie importantă a spaţiului de memorie, şi nu numai atît. 2) Evitarea inconsistenţei datelor. Duplicarea datelor în fişiere
diferite poate crea probleme la actualizare: este posibil ca prin actualizări parţiale (din omisiune sau datorită unor accidente neprevăzute) să avem valori diferite pentru una şi aceeaşi entitate (de

4
exemplu, un client poate avea mai multe nume: nu mai ştim care este
cel real). 3) Posibilitatea partajării datelor. Aceasta se referă la posibilitatea utilizării datelor în comun de mai mulţi utilizatori şi la posibilitatea dezvoltării de noi aplicaţii folosind datele deja existente. 4) Încurajarea utilizării unor standarde. Administratorul bazei de date poate impune alinierea la anumite standarde, fapt care permite ulterior un transfer rapid al datelor de pe o platformă (hardware sau
software) pe alta. 5) Posibilitatea protejării datelor. Administratorul bazei de date, avînd un control centralizat al datelor, poate introduce restricţii diferite de acces la date pentru fiecare categorie de utilizatori. 6) Menţinerea integrităţii datelor. Baza de date trebuie să conţină în permanenţă date corecte; aceasta presupune date coerente şi plauzibile, fapt care poate fi garantat de procedurile de validare
utilizate. 7) Independenţa datelor. Într-o aplicaţie scrisă într-un limbaj clasic de programare, cunoştinţele despre structura datelor şi tehnicile de accesare a acestora sînt "zidite" în programe. Orice schimbare în modul de reprezentare sau accesare face imposibilă utilizarea aplicaţiei: toate programele care referă aceste date trebuie rescrise. Independenţa datelor, garantată de utilizarea bazelor de date, presupune independenţa aplicaţiei de modul de reprezentare a datelor
şi de tehnicile de acces utilizate. Trebuie să facem o precizare: simplul fapt de a utiliza un SGBD în vogă la un moment dat nu ne garantează automat obţinerea acestor avantaje! Administratorul bazei de date trebuie să aibă o viziune de ansamblu asupra problemei care trebuie rezolvată, să cunoască toate datele problemei (ce se dă, ce se cere, cum se prelucrează) şi să cunoască facilităţile oferite de SGBD-ul folosit pentru a putea
beneficia de avantajele de mai sus. Şi în primul rînd trebuie să aibă cunoştinţe serioase despre proiectarea aplicaţiilor de baze de date.

5
Arhitectura unei baze de date
Considerăm un exemplu simplificat din practică: evidenţa facturilor într-un magazin. Atunci cînd un client doreşte să cumpere nişte produse, se întocmeşte o factură după modelul celei din figura 1. Ceea ce am prezentat în figura respectivă este un model extern al bazei de date, care descrie modul în care vede vînzătorul datele acesteia. Dacă pe şeful magazinului îl interesează care produse se
vînd cel mai bine într-o anumită perioadă de timp, atunci el poate primi o situaţie după modelul din figura 2. Modelul extern este cel mai apropiat de utilizator şi cuprinde descrierea structurii logice a datelor referitoare la aplicaţiile fiecărui utilizator. Observăm că fiecare utilizator vede altfel baza de date, deşi ea este unică şi este memorată într-un mod care este ascuns tuturor. Modelul conceptual cuprinde descrierea structurii datelor şi a
legăturilor dintre acestea pentru întreaga bază de date. În figura 3 este prezentat modelul conceptual al bazei de date pentru problema evidenţei facturilor. Baza de date se compune din patru tabele (Clienti, Produse, Facturi, Detalii) şi pentru fiecare tabelă este prezentată structura acesteia, cu alte cuvinte cîmpurile care o descriu. Am marcat cu (*) acele cîmpuri cheie care servesc la identificarea unică a fiecărei înregistrări din tabelă. Astfel, pentru tabela Clienti
cheia primară este Codcl, pentru Produse: Codpr, pentru Facturi: Nrfact; pentru tabela Detalii ea este formată din două cîmpuri: Nrfact şi Codpr. Legăturile dintre tabelele componente se văd uşor deoarece am folosit aceleaşi nume pentru cîmpurile care asigură aceste legături. Modelul conceptual este independent de modul de memorare a datelor, fapt care garantează independenţa datelor. Să remarcăm faptul că în figura 3 nu am precizat tipul cîmpurilor pentru nici o
tabelă. Modelul intern defineşte modul de memorare a datelor şi tehnicile de accesare a acestora. La acest nivel se defineşte pentru fiecare cîmp modul de reprezentare internă (dacă este şir de caractere, întreg binar, zecimal extern, boolean etc). Baza de date apare ca o colecţie de fişiere avînd diferite moduri de organizare (liste înlănţuite, B-arbori etc), aceste fişiere conţinînd datele ce formează baza de date. Acest

6
nivel este cel mai apropiat de sistemul de operare. Scopurile urmărite
în alegerea modelului intern sînt minimizarea spaţiului utilizat şi a timpilor de acces la date. În figura 4 este prezentată o vedere de ansamblu a arhitecturii unei baze de date. De ce este oare necesară o arhitectură atît de complexă? Drumul pe care l-a parcurs activitatea de prelucrare a volumelor mari de date a fost destul de lung şi de sinuos. S-a urmărit o simplificare pe două planuri: pe de o parte accesul utilizatorului la date, pe de altă parte proiectarea aplicaţiilor.
Cum rezolvă SGBD-ul o cerere de acces pe care o face un utilizator? SGBD-ul interpretează această cerere în conformitate cu modelul extern al utilizatorului respectiv şi găseşte corespondenţa dintre modelul extern al acestuia şi modelul conceptual. În continuare determină componentele modelului conceptual care vor interveni în rezolvarea cererii şi face un acces la acestea pe baza corespondenţei dintre modelul conceptual şi modelul intern. După ce au fost
identificate toate datele necesare, se revine din nou la modelul extern, acestea sînt integrate şi prezentate în final utilizatorului. Trebuie să precizăm faptul că în practică modelul prezentat mai sus nu este întotdeauna respectat intregral. Multe SGBD-uri nu fac o distincţie netă între modelul conceptual şi cel intern. Scopul pe care l-am urmărit în expunerea de faţă este de a pune în evidenţă acea parte a bazei de date care prin stabilitatea ei garantează independenţa aplicaţiilor faţă de structura datelor şi coerenţa informaţiilor
memorate în baza de date. Vom vedea în continuare (prezentarea limbajului SQL) că atunci cînd descriem o componentă a unei baze de date precizăm pentru fiecare cîmp şi tipul acestuia. Acest lucru este firesc deoarece atunci cînd proiectăm o bază de date avem în vedere şi operaţiile de prelucrare care se vor face. Dacă avem de efectuat operaţii aritmetice (adunări, scăderi, înmulţiri etc) atunci operanzii trebuie să fie neapărat de tip
numeric, ei nu pot fi şiruri de caractere! Modelul conceptual este inima oricărei baze de date şi de aceea proiectarea acestuia este deosebit de importantă, deoarece de felul în care este rezolvată această problemă depinde soarta aplicaţiilor care vor exploata baza de date. Dacă acesta este atent proiectat atunci aplicaţiile vor fi proiectate relativ uşor şi vor avea o fiabilitate

7
garantată. În caz contrar vor apărea mereu probleme pentru
rezolvarea cărora va trebui să apelăm de multe ori la improvizaţii.
Administratorul bazei de date
Acesta este o persoană sau un grup de persoane care răspunde de ansamblul activităţilor legate de baza de date. Problemele pe care le rezolvă sînt următoarele:
1) Decide care informaţii vor fi stocate în baza de date. Pe baza informaţiilor pe care le primeşte de la viitorii beneficiari (utilizatori) ai bazei de date identifică care entităţi prezintă interes pentru buna desfăşurare a activităţilor instituţiei, şi care informaţii ce caracterizează aceste entităţi trebuie memorate. În acest moment el este în măsură să proiecteze schema conceptuală. 2) Decide structura datelor care vor fi memorate şi tehnicile de
accesare. Administratorul bazei de date trebuie să urmărească stabilirea unui raport optim spaţiu de memorare / timpi de acces. Modelul intern este proiectat avîndu-se în vedere o estimare a evoluţiei volumului datelor, frecvenţa accesării lor, implicaţiile acestora în prelucrări. 3) Proiectează modelele externe pentru fiecare categorie de
utilizatori. Administratorul bazei de date se informează în legătură cu cerinţele acestora şi eventual balansează cerinţele conflictuale. Aceasta se face printr-o alegere atentă a modelului intern. 4) Defineşte strategia de garantare a integrităţii datelor. Există posibilitatea ca baza de date să nu mai fie operaţională la un moment dat, fie din cauza unor erori în operare, fie din cauza unor pene hard,
fie din alte cauze neprevăzute. Este foarte important pentru instituţie ca baza de date să fie refăcută într-un timp cît mai scurt şi cu pierderi minime de informaţii. Pentru aceasta administratorul bazei de date

8
elaborează strategii de salvare periodică a bazei de date şi de refacere
a acesteia (parţială sau în întregime) pe baza unor copii de siguranţă. 5) Monitorizează performanţele sistemului. Pentru a obţine o creştere a eficienţei aplicaţiilor urmăreşte modul de utilizare a resurselor şi depistează factorii care limitează performanţele sistemului. În sfîrşit el determină o planificare a funcţionării sistemului pentru a maximiza performanţele acestuia.
Un set minimal de unelte pe care le foloseşte administratorul bazei de date în munca sa sînt: - rutine de iniţializare (pentru încărcarea iniţială a bazei de date); - rutine de import şi export a datelor în şi respectiv din baza de date (conversii); - rutine de jurnalizare şi restaurare; - rutine de control şi refacere a coerenţei;
- rutine de analiză statistică a funcţionării sistemului.
Figura 1. Un model extern pentru vînzător
Număr factură: xxxxxxxxx Data: xx.xx.xxxx Cod client: xxxxxxxxx
Nume:xxxxxxxxxxxxxxxxxxxxxxxxxxxx Localitate: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Adresa: xxxxxxxxxxxxxxxxxxxxxxxxxxxxx Produse cumpărate: Cod prod Denumire Preţ unitar Cantitate Valoare
xxxxxxxx xxxxxxxxxxx xxxxxxxx xxxxxxx xxxxxx yyyyyyyy yyyyyyyyyyy yyyyyyyy yyyyyyy yyyyyy
Total valoare: zzzzzzzz
9
Figura 2. Un model extern pentru şeful magazinului
Figura 3. Modelul conceptual al bazei de date
Figura 4. Arhitectura unei baze de date
Perioada Cod prod Denumire Preţ Cant Val totală
xxxxxxx xxxxxxx xxxxxxxxxx xxxx xxxxx xxxxxxxx
yyyyyyy yyyyyxx yyyyyyyyyy yyyy yyyyy yyyyyyyy
Clienti Produse Facturi Detalii *Codcl *Codpr *Nrfact *Nrfact Nume Denumire Dataf *Codpr Localit Pretunit Codcl Cant
Adresa

10
2. Modelul relaţional
Ce este modelul relaţional? O caracterizare ar putea fi următoarea:
modelul relaţional este o tehnică de descriere a datelor cu ajutorul
tabelelor, şi o tehnică de manipulare a acestora cu ajutorul unor operatori
specifici calculului relaţional şi / sau algebrei relaţionale, concretizaţi prin
utilizarea unor limbaje specifice - cum ar fi QbE (Query by Example) sau
SQL (Structured Query Language). Modelul relaţional este un model
abstract care are la bază fundamente matematice solide (teoria algebrică a relaţiilor). Principiile modelului relaţional au fost descrise prin 1969-1970
de către E. F. Codd, cercetător la IBM. El a fost primul care a înţeles că
rigoarea matematică poate fi folosită pentru a introduce principii solide în
domeniul gestiunii bazelor de date - domeniu care era foarte deficitar la
acest capitol.
Modelul entităţi-legături
În nota de curs precedentă am prezentat o arhitectură clasică a unei baze de date. Aceasta este organizată pe trei nivele: nivelul extern sau utilizator, nivelul conceptual şi nivelul intern. Pentru a descrie nivelul conceptual folosim un model abstract numit model entităţi-legături. Elementul fundamental al acestui model este noţiunea de entitate: acest termen generic desemnează un obiect care face parte dintr-o
clasă (mulţime) de entităţi, toate aceste obiecte fiind similare ca structură, dar care pot fi deosebite prin proprietăţi specifice (pe care le vom numi în continuare atribute). Deoarece definiţia este destul de vagă (imprecisă) vom da două exemple preluate dintr-o problemă (simplificată) de evidenţă a facturilor, şi dintr-o altă problemă de evidenţă a personalului: - mulţimea clienţilor unui magazin formează o clasă de entităţi; toţi
aceşti clienţi au nişte atribute: cod personal, nume, localitate (de domiciliu), adresa; fiecare client este o entitate identificabilă prin codul personal al acestuia; - mulţimea produselor aflate în evidenţa magazinului formează o altă clasă de entităţi; toate aceste produse pot fi caracterizate prin: cod produs, denumire, preţ unitar; fiecare produs este o entitate identificabilă prin codul acestuia;

11
- mulţimea departamentelor unei firme; orice departament se
caracterizează prin: cod, denumire, şef; - mulţimea angajaţilor unei firme: fiecare angajat se caracterizează prin: număr legitimaţie, nume, departamentul la care lucrează. Un alt element care caracterizează acest model este noţiunea de legătură. Această legătură (asociere) între mai multe clase de entităţi E1, ..., En (nu neapărat distincte) presupune existenţa unei mulţimi de valori (e1, ..., en), unde ei este mulţimea valorilor atributelor unei
entităţi din clasa Ei. În practică de cele mai multe ori întîlnim legături între două clase de entităţi (n=2); acestea se numesc legături binare. Un exemplu concret preluat din evidenţa personalului: (101,"Personal",5001,5001,"Petrescu",101)
Primele trei valori sînt preluate din clasa de entităţi
Departamente, următoarele trei din Personal. Se observă uşor
că această mulţime de valori este un element al produsului cartezian
al celor două mulţimi: Departamente şi Personal. După ce
eliminăm valorile care se repetă (această operaţie este numită proiecţie) obţinem:
(101,"Personal",5001,"Petrescu") Să clasificăm în continuare legăturile binare după cardinalitatea acestora (cîte entităţi din fiecare clasă intră în cadrul legăturii): - legături de tip 1:1 (one-to-one); observăm o astfel de legătură în cazul unei evidenţe a personalului, care indică faptul că un
departament este condus de un şef (un departament nu poate fi condus de mai mulţi şefi, o persoană nu poate conduce mai multe departamente); - legături de tip 1:n (one-to-many); în evidenţa personalului remarcăm o astfel de legătură între angajaţii unui departament şi departamentul în cauză (la un departament lucrează mai mulţi
angajaţi, un angajat nu poate lucra în cadrul mai multor

12
departamente); la evidenţa facturilor remarcăm o legătură între
Facturi şi Clienti (unui client i se pot întocmi mai multe
facturi; nu se poate întocmi o aceeaşi factură pentru mai mulţi clienţi);
- legături de tip m:n (many-to-many); o astfel de legătură există între
Clienti şi Produse: un client poate cumpăra mai multe produse,
şi în acelaşi timp mai mulţi clienţi pot cumpăra un acelaşi sortiment de produse. După ce vor fi prezentate fundamentele modelului relaţional, vom prezenta şi tehnici de implementare a acestor tipuri de legături.
Domeniu, atribut, relaţie
Un domeniu este o mulţime de valori scalare (atomice - care nu pot fi descompuse) de acelaşi tip. Exemple: mulţimea codurilor personale, mulţimea numelor de clienţi, mulţimea numelor de localităţi ş.a. Cu aceste valori se pot efectua mai multe operaţii:
- cu majoritatea acestor valori se pot face comparaţii; - cu unele valori se pot face şi alte operaţii: o cantitate poate fi înmulţită cu un preţ (rezultînd o valoare), un preţ poate fi înmulţit cu o valoare (în cazul unei reaşezări) ş.a.m.d. Un atribut al unei clase de entităţi este o caracteristică (proprietate) care ia valori într-un anumit domeniu. Exemple:
- atributele clasei de entităţi CLIENTI sînt: cod client, nume client, localitate, adresa; - atributele clasei de entităţi PRODUSE sînt: cod produs, denumire produs, preţ unitar. O relaţie (în sens algebric) este o submulţime a unui produs cartezian
D1 D2 ... Dn, unde Di sînt domenii de valori (nu neapărat
distincte). Aceasta a fost definiţia folosită mult timp şi pentru noţiunea de relaţie în domeniul bazelor de date - modelul relaţional. Unul dintre cei mai prestigioşi autori de lucrări în acest domeniu, C.

13
J. Date (amintit în nota de curs precedentă) propune o nouă definiţie
pentru noţiunea de relaţie (în domeniul bazelor de date): aceasta se compune din două părţi: - antetul relaţiei, care este o mulţime de atribute definite fiecare pe cîte un domeniu de valori (aceste domenii nu sînt neapărat distincte): {A1:D1, A2:D2, ..., Am:Dm}; - corpul relaţiei, care este o mulţime de tuple (un tuplu este o generalizare a noţiunii de cuplu); fiecare tuplu este definit ca o
mulţimi de valori ale atributelor definite în cadrul antetului: {{A1:v11, A2:v12, ..., Am:v1m}, ..., {A1:vn1, A2:vn2, ..., Am:vnm}}. Valoarea m (numărul de atribute ale relaţiei) reprezintă gradul relaţiei, şi valoarea n (numărul de tuple) reprezintă cardinalitatea relaţiei.
Din definiţia de mai sus a noţiunii de relaţie rezultă următoarele proprietăţi: - atributele nu sînt ordonate (ordinea lor nu este semnificativă) - rezultă din faptul că antetul este definit ca o mulţime de atribute (într-o mulţime ordinea elementelor nu este semnificativă); - atributele sînt distincte (chiar dacă pot exista două atribute definite pe acelaşi domeniu) - elementele unei mulţimi sînt distincte; - în cadrul corpului relaţiei tuplele nu sînt ordonate - corpul relaţiei
este definit ca o mulţime de tuple; - orice atribut are doar valori atomice; această proprietate poate fi enunţată şi astfel: la intersecţia dintre o linie şi o coloană se află întotdeauna o singură valoare, şi niciodată o colecţie de valori; rezultă că o relaţie nu conţine grupuri repetitive; spunem în acest caz că relaţia se află în prima formă normală; - nu există tuple duplicate (deoarece corpul unei relaţii este o mulţime
de tuple).
Dacă o linie din tabela Clienti conţine valorile:
(80001, "Ionescu", "Bucuresti", "Str Libertatii")

14
toate aceste valori se află într-o anumită relaţie: ele definesc
identitatea unui client, care are cod personal 80001, are numele "Ionescu", domiciliază în localitatea "Bucuresti" la adresa "Str Libertatii". Prezentăm în continuare o corespondenţă între termenii formali (definiţi mai sus) şi termenii informali (cei folosiţi în mod curent în exploatarea bazelor de date relaţionale):
Relaţie Tabelă Tuplu Linie, înregistrare Cardinalitate Număr de linii Atribut Coloană, cîmp Grad Număr de coloane Domeniu Mulţime de valori valide
Corespondenţa nu trebuie considerată ca o echivalenţă, deoarece există cîteva deosebiri de care trebuie să ţinem seama (este de altfel una dintre diferenţele pe care le sesizăm între teorie şi practică): - noţiunea de relaţie este o noţiune teoretică, pe cînd o tabelă este un obiect concret, care are o anumită reprezentare în calculator - sub forma unui tablou bidimensional; - într-o relaţie ordinea atributelor şi a tuplelor nu este semnificativă;
într-o tabelă există o ordonare atît a coloanelor - dată de ordinea acestora la crearea tabelei, cît şi a liniilor - dată de ordinea în care acestea au fost introduse, sau de ordinea unei chei care induce o anumită ordonare a liniilor în cadrul tabelei; - o relaţie este formată întotdeauna din tuple distincte; în multe cazuri o tabelă poate avea linii duplicate.
Cheie primară, cheie externă
O cheie candidată a unei relaţii R este o mulţime K de atribute cu următoarele proprietăţi: - identificare unică: nu există două tuple distincte în R care să aibă aceeaşi valoare pentru setul de atribute K; cu alte cuvinte, mulţimea
K de atribute identifică în mod unic fiecare tuplu al relaţiei R;

15
- nereductibilitate: nu există o submulţime proprie a lui K (distinctă
de K) care să aibă proprietatea de identificare unică. O cheie este simplă dacă este formată dintr-un singur atribut, şi este compusă în caz contrar. O relaţie poate avea mai multe chei candidate; una dintre acestea se alege pentru a fi folosită în aplicaţii ca şi cheie de identificare a tuplelor. Cheia candidată folosită în acest scop se numeşte cheie primară; de obicei se folosesc în acest scop acele chei care reprezintă
coduri ale înregistrărilor memorate în baza de date. Un motiv important pentru a justifica o astfel de alegere este următorul: valorile de tip cod ocupă foarte puţin spaţiu în comparaţie cu informaţiile pe care le identifică, fapt care conduce la o economie importantă de spaţiu în cazul creării unui index, precum şi la accelerarea regăsirii informaţiilor în cazul în care se fac corelaţii între tabele. Să analizăm unul din exemplele prezentate:
- tabela Clienti are cheia primară Codcl, tabela Produse are
cheia primară Codpr, tabela Facturi are cheia primară Nrfact;
în toate aceste cazuri se verifică uşor cele două proprietăţi ale cheii primare - atît identificarea unică cît şi ireductibilitatea sînt evidente;
- tabela Detalii are cheia primară compusă din atributele Nrfact
şi Codpr; ireductibilitatea este evidentă şi în acest caz, deoarece este
posibil să avem mai multe linii cu aceeaşi valoare pentru Nrfact
(cînd un client cumpără mai multe produse cu aceeaşi factură), şi de asemenea este posibil să avem mai multe linii cu aceeaşi valoare
pentru Codpr (cînd mai mulţi clienţi cumpără acelaşi tip de marfă).
În continuare se defineşte noţiunea de cheie externă (sau cheie străină) în conexiune cu noţiunea de cheie candidată. Să facem precizarea că în majoritatea situaţiilor practice apar legături între tabele care se materializează prin coincidenţa valorilor cheilor primare şi externe. Fie R2 o relaţie. O cheie externă din R2 este o mulţime Ek de atribute
cu următoarele proprietăţi:

16
- există o tabelă R1 (care poate să coincidă sau nu cu R2) care are o
cheie candidată Pk; - fiecare valoare a setului Ek din R2 coincide cu o valoare a setului Pk din R1. Să analizăm din nou unul din exemplele prezentate:
- tabela Facturi are o cheie externă Codcl, care este cheie
primară în tabela Clienti;
- tabela Detalii are două chei externe: Nrfact care este cheie
primară în tabela Facturi, şi Codpr care este cheie primară în
tabela Produse; am remarcat mai sus că cele două chei externe
formează împreună cheia primară a tabelei Detalii.
Să facem cîteva precizări: - prin definiţie, fiecare valoare a unei chei externe trebuie să se regăsească printre mulţimea valorilor cheii candidate corespondente;
reciproca nu este obligatorie: de exemplu, putem să înregistrăm
informaţii în tabela Clienti despre un potenţial client, chiar dacă
acesta încă nu cumpără nimic; putem de asemenea să înregistrăm
informaţii despre un produs pe care îl aducem în magazin, şi care încă nu este cumpărat de nici un client; - o cheie externă este simplă dacă şi numai dacă cheia candidată corespondentă este simplă, şi este compusă dacă şi numai dacă cheia candidată corespondentă este compusă;
- fiecare atribut component al unei chei externe trebuie să fie definit pe acelaşi domeniu al componentei corespondente din cheia candidată; - o valoare a unei chei externe reprezintă o referinţă către un tuplu care conţine aceeaşi valoare pentru cheia candidată corespondentă; se

17
pune astfel problema integrităţii referinţei: o bază de date nu trebuie
să conţină valori invalide pentru chei externe, altfel spus dacă B referă pe A atunci A trebuie să existe.
Ce se întîmplă dacă ştergem din tabela Clienti un client pentru
care avem cîteva linii în tabela Facturi? Dacă operaţia de ştergere
se efectuează fără nici un control, după ştergere nu mai este
respectată regula integrităţii referinţei. Pentru a preveni asemenea
situaţii, în tabela Facturi precizăm la creare:
[ON DELETE option] [ON UPDATE option]
unde opţiunea poate fi:
- RESTRICTED dacă dorim ca operaţia cerută pentru tabela
Clienti să fie respinsă;
- CASCADES dacă dorim ca operaţia cerută pentru tabela Clienti
să provoace operaţii (actualizări sau ştergeri) "în cascadă" - se
actualizează (sau se şterg) toate liniile afectate din tabela Facturi;
în acest al doilea caz se cere o atenţie deosebită, deoarece o ştergere a
unei linii din tabela Facturi poate afecta linii din tabela
Detalii.
Cheile externe se folosesc pentru a implementa legăturile dintre
entităţi. Legăturile de tip one-to-one şi one-to-many se implementează introducînd în una din tabele o cheie externă, care va face legătura cu cheia primară din tabela corespondentă. O legătură de tip many-to-many se implementează introducînd o tabelă suplimentară care are o cheie primară compusă, fiecare element al cheii primare fiind o cheie externă. Cele două exemple sînt (sperăm) concludente în acest sens.
Valori NULL
Există unele situaţii cînd regula integrităţii referinţei nu poate fi
respectată. Să considerăm următorul exemplu foarte simplu: o bază de date pentru evidenţa personalului compusă din două tabele:

18
Departamente (Coddep, Dendep, Sefdep)
Angajati (Nrleg, Numeang, Dep)
Observăm că tabela Departamente are ca şi cheie primară
atributul Coddep, şi cheie externă Sefdep, care este cheie primară
în tabela Angajati. De asemenea tabela Angajati are ca şi cheie
primară atributul Nrleg, şi cheie externă Dep, care este cheie
primară în tabela Departamente. În momentul creării celor două
tabele nu există nici o informaţie înregistrată. Dacă dorim să introducem informaţii despre un departament operaţia de inserare va fi respinsă deoarece nu avem informaţiile despre şeful departamentului respectiv. Dacă dorim să introducem informaţii despre şeful unui departament operaţia de inserare va fi de asemenea respinsă deoarece nu avem informaţiile despre departamentul respectiv.
Această problemă este rezolvată prin introducerea noţiunii de valoare NULL; semnificaţia acestei valori este valoare necunoscută sau informaţie absentă. În concordanţă cu această nouă noţiune regulile de integritate se completează astfel: - integritatea entităţii: orice atribut al unei chei primare nu poate avea valoarea NULL; - integritatea referinţei: orice valoare a unei chei externe este fie
NULL fie coincide cu o valoare a unei chei candidate corespondente. Problema enunţată mai sus se poate rezolva în felul următor: - mai întîi se introduc informaţiile despre departament, dar fără să se precizeze informaţia despre şeful departamentului;
- în continuare se introduc informaţiile despre şeful departamentului, şi în acest moment se poate introduce şi informaţia despre departamentul la care acesta lucrează; -în final se actualizează informaţia absentă din tabela
Departamente.

19
Crearea unei baze de date relaţionale în SQL
O bază de date relaţională este o bază de date care este văzută de utilizator ca o colecţie de relaţii (tabele) normalizate (aduse cel puţin în forma întîi normală).
Înainte de a prezenta instrucţiunile SQL pentru definirea unei baze de date să facem cîteva precizări. Numele limbajului (prescurtare de la Structured Query Language - limbaj structurat de interogare) este impropriu după cum se poate uşor observa. Acest limbaj ne permite atît definirea datelor, cît şi manipularea acestora: inserare, modificare, ştergere, consultare (interogare). Orice operaţie realizată de o instrucţiune SQL operează cu tabele SQL. O tabelă SQL, spre deosebire de relaţii, poate avea linii duplicate. De asemenea tabelele
SQL au o ordine precizată a coloanelor (de la stînga la dreapta), în schimb ordinea liniilor nu este semnificativă. O tabelă SQL se creează cu ajutorul unei comenzi CREATE TABLE:
CREATE TABLE Nume-tabela(
Coloana Reprezentare [Valoare-implicita]
[Restrictii], ...
);
Reprezentare. Standardul SQL precizează mai multe tipuri de date scalare (detalii privind modul de reprezentare trebuie căutate în
documentaţia SGBD-ului care se foloseşte în mod concret), unele dintre acestea fiind prezentate în continuare: Char(n) - o coloană de şiruri de maximum n caractere; Integer - o coloană de valori întregi pozitive sau negative (de regulă întregi pe 4 octeţi); Smallint - o coloană de valori întregi mici (de regulă întregi pe 2 octeţi); Float(p) - o coloană de valori reprezentate în virgulă mobilă;
Decimal(p,q) - o coloană de valori zecimale, unde p este numărul total de poziţii pe care se reprezintă numărul, şi q este numărul de cifre ale părţii zecimale (punctul zecimal nu se reprezintă în mod explicit)

20
Date - o coloană de valori de tip dată calendaristică, pentru
reprezentarea cărora se foloseşte un format specific SGBD-ului folosit; Time - o coloană de valori de tip oră exactă. Valoare implicită. Pentru fiecare coloană se poate preciza o valoare implicită (care trebuie să se încadreze în tipul de date definit la reprezentare), în cazul în care la inserarea unei linii în tabelă nu este
precizată o valoare pentru coloana respectivă. Dacă nu a fost precizată o valoare implicită la creare şi nici la inserare, atunci coloana respectivă va primi o valoare NULL, dar numai dacă o valoare NULL este permisă. O valoare implicită se precizează astfel: DEFAULT = valoare
Restricţii. O restricţie poate fi de tipul următor:
NOT NULL - coloana respectivă nu poate primi valori NULL;
CHECK (conditie) - se precizează o condiţie care va fi verificată
în momentul inserării unei linii în tabelă, sau în momentul actualizării unei linii: de exemplu
CHECK (PRETUNIT > 0)
restricţie de tip cheie candidată:
UNIQUE (Lista-de-coloane);
restricţie de tip cheie primară:
PRIMARY KEY (Lista-de-coloane);
restricţie de tip cheie externă:
FOREIGN KEY (Lista-de-coloane) REFERENCES
Nume-tabela [ON DELETE option] [ON UPDATE
option]

21
Comenzile SQL pentru crearea bazei de date cu care am lucrat pînă
acum pot fi următoarele:
CREATE TABLE CLIENT(
Codcl Integer,
Nume Char(60),
Localit Char(60),
Adresa Char(60),
PRIMARY KEY (Codcl)
);
CREATE TABLE PRODUSE(
CodPr Integer,
Denumire Char(60),
PretUnitar Integer,
PRIMARY KEY(Codpr),
CHECK(PRETUNIT > 0)
);
CREATE TABLE FACTURI(
Nrfact Integer,
Dataf DATE,
Codcl Integer,
PRIMARY KEY(Nrfact),
FOREIGN KEY(Codcl) REFERENCES Clienti
ON DELETE RESTRICTED ON UPDATE RESTRICTED);
CREATE TABLE DETALII(
Nrfact Integer,
Codpr Integer,
Cant Integer,
PRIMARY KEY(Nrfact, Codpr),
FOREIGN KEY(Nrfact) REFERENCES Facturi,
FOREIGN KEY(Codpr) REFERENCES Produse
ON DELETE RESTRICTED ON UPDATE RESTRICTED);

22
Structura unei tabele poate fi modificată ulterior cu ajutorul unei
comenzi ALTER TABLE:
ALTER TABLE Nume-tabela ADD/MODIFY/DROP Nume-
coloana Specificatii ...
Este posibil să adăugăm o coloană nouă în tabelă, să ştergem o coloană existentă din tabelă, sau să modificăm specificaţiile (de tip, de restricţii etc) ale unei coloane existente.
Încărcarea şi actualizarea datelor
Introducerea datelor. Instrucţiunea Insert are sintaxa următoare:
INSERT INTO Nume-tabela [(Lista-coloane)]
VALUES (Lista-valori);
Datele pot fi introduse în mai multe moduri: -se precizează lista coloanelor care vor primi valori, şi în acest caz celelalte coloane vor primi fie valoarea NULL fie valoarea implicită specificată la crearea tabelei; lista valorilor corespunde cu lista
coloanelor; exemplu:
INSERT INTO Departamente (Coddep, Dendep)
VALUES (101, 'Personal');
-nu se precizează lista coloanelor, caz în care trebuie specificate valorile în listă în conformitate cu lista coloanelor precizată la crearea
tabelei; lista valorilor trebuie să fie completă (eventual cu argumente absente precizate explicit); exemplu:
INSERT INTO Departamente
VALUES (101, 'Personal',);

23
INSERT INTO Angajati VALUES
(5001, 'Petrescu',101);
Actualizarea datelor. Instrucţiunea Update are sintaxa următoare:
UPDATE Nume-tabela
SET Coloana = Valoare [WHERE Conditie];
Sunt actualizate liniile din tabelă pentru care este verificată condiţia specificată. Atenţie: dacă nu s-a specificat nici o condiţie sînt actualizate toate liniile tabelei. Exemplu:
UPDATE Departamente
SET Sefdep = 10 WHERE Coddep=100;
Ştergerea datelor. Instrucţiunea DELETE are sintaxa următoare:
DELETE FROM Nume-tabela [WHERE Conditie];
Sunt şterse liniile din tabelă pentru care este verificată condiţia specificată. Atenţie: dacă nu s-a specificat nici o condiţie sînt şterse
toate liniile tabelei. Exemplu:
DELETE FROM Departamente
WHERE Departament='Personal';
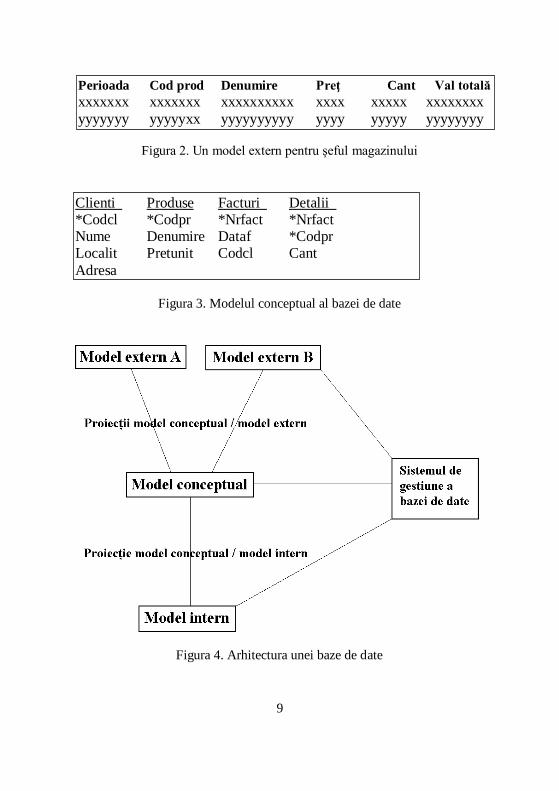
Un model entităţi-legături pentru evidenţa personalului. Am pus în evidenţă
cele două tipuri de legături existente între Departamente şi Personal.

24
Un exemplu de bază de date pentru evidenţa personalului
DEPARTAMENTE PERSONAL
Coddep Dendep Sefdep Nrleg Nume Depart
100 Conducere 5000 5000 Popescu 100 101 Personal 5001 5001 Petrescu 101 102 Productie 5002 5002 Ionescu 102 5005 Carmen 100 5006 Adam 102 5007 Barbu 101
25
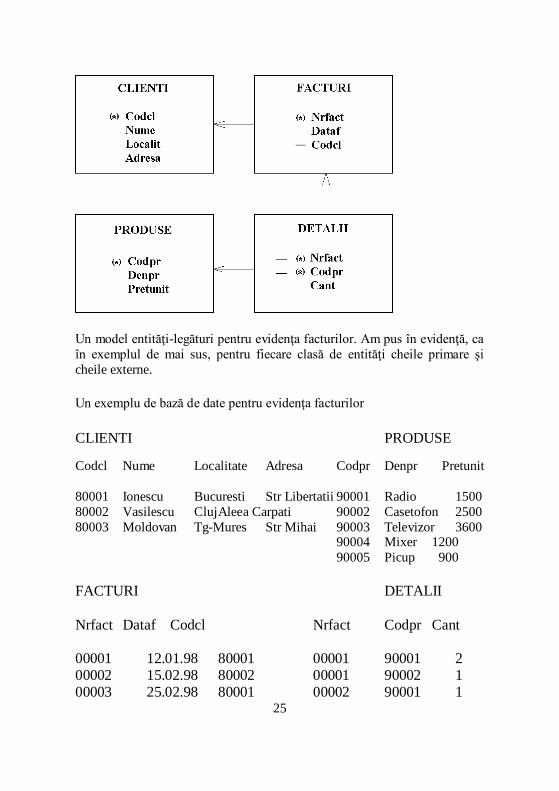
Un model entităţi-legături pentru evidenţa facturilor. Am pus în evidenţă, ca
în exemplul de mai sus, pentru fiecare clasă de entităţi cheile primare şi
cheile externe.
Un exemplu de bază de date pentru evidenţa facturilor
CLIENTI PRODUSE
Codcl Nume Localitate Adresa Codpr Denpr Pretunit
80001 Ionescu Bucuresti Str Libertatii 90001 Radio 1500
80002 Vasilescu Cluj Aleea Carpati 90002 Casetofon 2500
80003 Moldovan Tg-Mures Str Mihai 90003 Televizor 3600 90004 Mixer 1200
90005 Picup 900
FACTURI DETALII
Nrfact Dataf Codcl Nrfact Codpr Cant 00001 12.01.98 80001 00001 90001 2 00002 15.02.98 80002 00001 90002 1 00003 25.02.98 80001 00002 90001 1

26
00004 07.03.98 80003 00002 90002 2
00002 90003 1 00003 90003 1 00004 90002 1 00004 90004 1

27
3. Instrucţiunea Select SQL
În nota de curs precedentă am făcut cunoştinţă cu cîteva instrucţiuni ale limbajului SQL: Create table, Insert, Update, Delete. Aceste instrucţiuni ne-au permis să creăm tabele, să introducem şi să actualizăm informaţii în aceste tabele. În articolul de faţă prezentăm cîteva posibilităţi de interogare a bazelor de date relaţionale cu
ajutorul instrucţiunii Select SQL. Deoarece aproape fiecare SGBD relaţional implementează un subset al limbajului SQL, plus unele "inovaţii" care creează uneori confuzii, insistăm doar asupra unor aspecte pe care le considerăm esenţiale.
Limbajul SQL (Structured Query Language) a fost creat prin anii '70
în laboratoarele din San Jose ale firmei IBM. Sintaxa acestui limbaj este, după cum ne-am putut da seama, destul de apropiată de limba engleză, fiind adecvat programării pe calculator şi uşor de asimilat de către utilizatori. SQL nu este un limbaj de programare (aşa cum sînt limbajele procedurale cunoscute: C, Pascal, Fortran, Cobol), este destinat manipulării datelor dintr-o bază de date relaţională. De aceea el este inclus într-un limbaj procedural cu care este dotat aproape
fiecare SGBD relaţional. Sintaxa generală a instrucţiunii Select SQL este următoarea: SELECT [DISTINCT] atribut / expresie ... FROM tabelă [AS sinonim] ... [WHERE condiţii de selecţie şi / sau condiţii de legătură ...] [GROUP BY atribut ...] [HAVING condiţii de selecţie ...]
[ORDER BY atribut ASC|DESC ...]; Rezultatul selecţiei este o tabelă ale cărei coloane sînt cîmpurile care
apar în lista clauzei Select. Pentru a ilustra mai multe posibilităţi
de utilizare a instrucţiunii Select SQL, vom lucra cu cinci exemple de baze de date. Numele tabelelor şi ale cîmpurilor au fost alese în aşa fel încît să sugereze cît mai bine semnificaţia lor, precum şi să

28
evidenţieze cît mai clar legăturile dintre tabele. În nota de curs
următoare aceste exemple vor fi reluate şi explicate, astfel că în final vom înţelege de ce o bază de date trebuie să fie compusă din aşa de multe tabele. Pentru început trebuie să ştim că în felul acesta se garantează corectitudinea datelor introduse (sau cel puţin există un control din partea SGBD-ului), se elimină redundanţele (repetiţiile inutile), şi eventuale actualizări se pot face uşor fără a afecta integritatea informaţiilor deja introduse.
Selectarea unor informaţii dintr-o tabelă
Exemplul 1 - o evidenţă simplificată a studenţilor: STUDNOTE(Stud,Disc,Nota)
Pentru a ilustra utilizarea instrucţiunii Select folosind o singură
tabelă, vom face pentru început referire la tabela StudNote din
primul exemplu care conţine informaţii despre notele obţinute de fiecare student la toate disciplinele pe care le studiază. Structura
tabelei este foarte simplă, avînd doar trei coloane (Stud, Disc,
Nota), primele două formînd cheia primară.
Cel mai simplu exemplu de instrucţiune Select este următorul:
Select * from StudNote;
Această instrucţiune selectează toate informaţiile din tabela
StudNote. Caracterul '*' se referă la toate coloanele tabelei (sau
tabelelor - în cazul general) din lista clauzei from. Putem selecta o
parte din coloanele tabelei, ca în exemplul de mai jos:
Select Disc from StudNote;
Această instrucţiune selectează lista disciplinelor care sînt studiate. Dacă o folosim în forma prezentată mai sus, vom observa că tabela rezultat va avea tot atîtea linii cîte are şi tabela StudNote, aceasta deoarece fiecare disciplină apare de mai multe ori (o dată pentru fiecare student).

29
Următorul exemplu arată cum se poate obţine lista studenţilor, de
data aceasta fără repetiţii supărătoare:
Select distinct Stud from StudNote;
Putem cere selectarea unor linii care îndeplinesc anumite condiţii, de exemplu lista notelor sub 5:
Select * from StudNote where Nota<5;
În clauza where putem preciza condiţii complexe de căutare,
combinate cu operatorii logici AND, OR şi NOT, ordinea de evaluare
fiind cea cunoscută. Se pot folosi şi paranteze pentru a controla ordinea de evaluare a condiţiilor.
Funcţii de agregare în interogări cu o singură tabelă
Dacă ne interesează care este cea mai mare şi cea mai mică notă dintre cele care au fost date, formulăm următoarea interogare:
Select min(Nota), max(Nota) from StudNote;
Media generală se obţine astfel:
Select avg(Nota) from StudNote;
Folosim funcţia count pentru a afla numărul de înregistrări ale
tabelei StudNote:
Select count(*) from StudNote;
Standardul SQL defineşte următoarele funcţii de agregare:
- min: valoarea minimă de pe o anumită coloană;
- max: valoarea maximă de pe o anumită coloană;
- sum: suma valorilor de pe o anumită coloană;
- avg: media aritmetică a valorilor de pe o anumită coloană;

30
- count: numărul de înregistrări selectate.
Funcţiile sum şi avg pot fi folosite doar pentru coloane care au
valori numerice, spre deosebire de celelalte care pot opera cu orice
tip de valori. Funcţia avg poate returna o valoare de tip diferit de cel
al atributului căruia i se aplică (de exemplu, media aritmetică a unor valori întregi poate fi o valoare cu zecimale). Sînt necesare cîteva precizări în legătură cu aceste funcţii. Implicit ele iau în considerare toate valorile aflate pe coloana specificată; dacă se doreşte să fie prelucrate doar valorile distincte, atunci numele coloanei trebuie
precedat de cuvîntul cheie distinct.
Şi o precizare în legătură cu funcţia Count. Aceasta poate fi folosită
pentru a numărta toate înregistrările - forma count(*), sau pentru a
număra valorile distincte ale unei anumite coloane. De exemplu, ne interesează cîţi studenţi avem în evidenţă:
Select count(distinct Stud) from StudNote;
Să presupunem că ne interesează notele cele mai mari, dar şi care sînt studenţii care au primit acele note. Pentru aceasta trebuie să comparăm fiecare notă cu valoarea maximă, care poate fi obţinută
printr-o interogare. Deducem că trebuie să folosim interogări SQL imbricate:
Select * from StudNote where Nota =
(Select max(Nota) from StudNote);
Comparaţia este posibilă deoarece instrucţiunea Select interioară
returnează o singură valoare. Acestea au fost interogări relativ simple. Dacă dorim să ştim care studenţi sînt restanţieri, interogarea este de asemenea foarte simplă:
Select Distinct Stud from StudNote
where Nota < 5;

31
Am folosit clauza distinct deoarece altfel studenţii care au mai
mult de o restanţă apar de mai multe ori în listă. Dacă în schimb dorim să ştim care sînt studenţii integralişti, interogarea ne va da serioase dureri de cap. Aceasta deoarece, spre
deosebire de cazul precedent, aici trebuie să formulăm altfel condiţiile de selecţie. Prezentăm în continuare două formulări echivalente: - toate notele obţinute de un student sînt de cel puţin 5; - nici o notă obţinută de un student nu este sub 5.
Ar trebui pentru fiecare student să încercăm a selecta numai înregistrările corespunzătoare acestuia şi care au nota sub 5. Se reţin în rezultatul final numai acei studenţi pentru care nu s-a selectat nici o înregistrare (rezultatul selecţiei este vid). Într-un limbaj pseudocod această problemă se rezolvă astfel:
pentru i de la 1 la n
S := ; pentru j de la 1 la n
daca (StudNote[i].Stud=StudNote[j].Stud
si StudNote[j].Nota < 5)
S := S StudNote[j];
sf
sf
daca (S = ) output(StudNote[i].Stud);
sf
sf
În secvenţa de mai sus am comparat cîmpul Stud din înregistrările
StudNote[i] şi StudNote[j]. În limbajul SQL nu avem o
astfel de posibilitate; putem în schimb să folosim o tabelă sub mai multe nume (sinonime), şi să comparăm două cîmpuri ca şi cum ele
ar face parte din tabele diferite. Interogarea se rezolvă astfel:

32
Select Stud from StudNote as S where not
exists
(Select * from StudNote as T
where S.Stud = T.Stud and T.Nota < 5);
Remarcăm folosirea expresiei condiţionale not exists, care
returnează valoarea true dacă tabela transmisă ca argument este
vidă.
Să reformulăm interogarea cu scopul de a obţine o instrucţiune Select mai simplă: să se selecteze toţi studenţii care nu se află în lista restanţierilor. Această interogare se scrie astfel:
Select Stud from StudNote where not Stud in
(Select Stud from StudNote where Nota<5);
Remarcăm folosirea expresiei condiţionale not (Stud in
(...)), care verifică dacă o valoare se află sau nu într-o listă
(obţinută pe baza unei selecţii). Până acum funcţiile de agregare au operat asupra tuturor valorilor din rezultatul selecţiei. Putem să construim şi grupe de înregistrări asupra cărora să opereze aceste funcţii. Ne interesează media fiecărui student:
Select Stud, avg(Nota) from StudNote
group by Stud;
Putem ordona această situaţie descrescător după medie şi în ordine alfabetică după nume:
Select Stud, avg(Nota) from StudNote
group by Stud order by 2 desc, 1;
Dacă dorim să selectăm doar acei studenţi care au media minimum 9,
folosim şi clauza having:
Select Stud, avg(Nota) from StudNote
group by Stud having avg(Nota) >= 9;

33
Selectarea unor informaţii din mai multe tabele
Exemplul 2 - evidenţa angajaţilor unei instituţii: DEPARTAMENTE(Codd,Dendep,Sefd) PERSONAL(Nrl,Nume,Dep)
Ne interesează să aflăm, pentru fiecare departament, cine este şeful acestuia şi cîţi angajaţi lucrează la departamentul respectiv:
Select Codd, Dendep, Sefd, Nume,
(Select count(*) from Angajati
where Codd = Dep)
from Departam,Angajati where Sefd = Nrl;
Remarcăm şi în acest caz folosirea unei instrucţiuni Select care returnează o valoare. Pentru această instrucţiune Select atributul
Codd joacă acelaşi rol pe care îl are o variabilă globală într-un
program C sau Pascal. Aceasta deoarece ne interesează cîţi angajaţi
are un anumit departament: dacă am fi inclus în lista clauzei from şi
tabela Departam, atunci instrucţiunea Select interioară ar fi pierdut
valoarea atributului Codd din exterior (să ne gîndim ce se întîmplă
atunci cînd scriem un program în C sau Pascal). Dar lucrurile nu s-ar opri aici: instrucţiunea Select interioară ar efectua produsul cartezian al celor două tabele şi ar număra cîte înregistrări ale acestui produs
îndeplinesc condiţia din clauza where.
În instrucţiunea Select exterioară remarcăm în clauza where o condiţie care se numeşte condiţie de legătură. Aceste condiţii de
legătură se scriu în general astfel: cheie-primară = cheie-externă
Exemplul 3 - evidenţa facturilor: CLIENTI(Codc,Nume,Localit,Adresa) PRODUSE(Codp,Denpr,Pretu)

34
FACTURI(Nrf,Dataf,Codc)
DETALII(Nrf,Codp,Cant)
Dorim să ştim care este valoarea fiecărei facturi:
Select Facturi.Nrf, Dataf, Facturi.Codc, Nume,
Localit, Adresa, Sum(Cant*Pretu)
from Facturi, Clienti, Detalii, Produse
where Facturi.Nrf = Detalii.Nrf
and Facturi.Codc = Clienti.Codc
and Detalii.Codp = Produse.Codp
group by Facturi.Nrf, Dataf,
Facturi.Codc, Nume, Localit, Adresa;
Remarcăm mai întîi necesitatea de a califica acele atribute care apar cu acelaşi nume în mai multe tabele. În al doilea rînd (un fapt nu
tocmai plăcut), necesitatea de a include în lista clauzei group by
toate cîmpurile din clauza Select care nu sînt funcţii de agregare.
Standardul SQL cere acest lucru, şi majoritatea SGBD-urilor care
implementează limbajul Select SQL se conformează acestei cerinţe.
În al treilea rînd observăm că în lista clauzei Select putem avea şi
expresii aritmetice, chiar şi ca argumente ale unei funcţii de agregare.
O altă interogare pe care o putem face este: suma totală pe care a plătit-o fiecare client. Aceasta este ceva mai scurtă decît precedenta:
Select Facturi.Codc, Nume, Localit, Adresa,
Sum(Cant*Pretu)
from Facturi, Clienti, Detalii, Produse
where Facturi.Nrf = Detalii.Nrf
and Facturi.Codc = Clienti.Codc
and Detalii.Codp = Produse.Codp
group by Facturi.Codc, Nume, Localit,
Adresa;
Dacă dorim să aflăm căror clienţi le-am întocmit facturi care totalizează o valoare maximă, trebuie să procedăm în doi paşi. Mai întîi creăm o tabelă nouă în care depunem rezultatele selecţiei de mai

35
sus. Pentru aceasta folosim instrucţiunea Insert cu următoarea
sintaxă, presupunînd că avem creată o tabelă Valori (Codf, Nume, Localit, Adresa, Val):
Insert into Valori
Select Facturi.Codc, Nume, Localit, Adresa,
Sum(Cant*Pretu)
from Facturi, Clienti, Detalii, Produse
where Facturi.Nrf = Detalii.Nrf
and Facturi.Codc = Clienti.Codc
and Detalii.Codp = Produse.Codp
group by Facturi.Codc, Nume, Localit,
Adresa;
În pasul al doilea putem extrage informaţiile care ne interesează:
Select Codc, Nume, Localit, Adresa, Val
from Valori where Val =
(Select max(Val) from Valori);
Exemplul 4 - evidenţa comenzilor
FURNIZORI(Codf,Nume,Localit,Adresa) PRODUSE(Codp,Denp) OFERTE(Codf,Codp,Pretu) COMENZI(Nrc,Datac,Codf) DETALII(Nrf,Codp,Cant)
Dorim să ştim care este valoarea fiecărei comenzi:
Select Comenzi.Nrc, Datac, Comenzi.Codf, Nume,
Localit, Adresa, Sum(Cant*Pretu)
from Furnizori, Oferte, Comenzi, Detalii
where Comenzi.Nrc = Detalii.Nrc
and Detalii.Codp = Oferte.Codp
and Comenzi.Codf = Furnizori.Codf
and Detalii.Codp = Oferte.Codp
and Comenzi.Nrf = Oferte.Codf
group by Comenzi.Nrc, Datac,
Comenzi.Codf, Nume, Localit, Adresa;

36
Am fost nevoiţi să punem toate cele patru condiţii de legătură,
deoarece informaţiile despre preţurile produselor se află în tabela
Oferte - fiecare produs poate avea preţuri diferite de la un furnizor
la altul.
Ne interesează de unde putem achiziţiona fiecare produs la cel mai mic preţ:
Select Produse.Codp, Denp, Pretu,
Furnizori.Codf, Nume, Localit, Adresa
from Oferte as O, Furnizori as F, Produse
as P
where O.Codf =
(Select Codf from Oferte as Q
where P.Codp = Q.Codp and Pretu =
(Select min(Pretu) from
Oferte))
and O.Codf = F.Codf and O.Codp = P.Codp;
Exemplul 5 - o evidenţă detaliată a studenţilor:
STUDENTI(Nrls,Nume,Spec,An) DISCIPLINE(Codd,Dend,Spec,An) SPECIALIZARI(Cods,Dens) NOTELE(Nrls,Codd,Nota)
Această evidenţă presupune gestiunea a patru tabele. Primele trei tabele le numim tabele primare, deoarece datele primare se introduc
în tabelele Studenti, Discipline, Specializari. Tabela
Notele păstrează informaţii care presupun o corelare între celelalte
trei tabele, deci nu putem introduce oricum datele de intrare. Presupunem că avem toate datele introduse în tabelele primare şi
dorim să pregătim tabela Notele pentru a putea introduce ulterior şi
notele de la examene. Folosim o instrucţiune Insert pentru a introduce în tabelă rezultatul unei selecţii:
Insert into Notele (Nrls, Codd)
Select Nrls, Codd from Studenti, Discipline

37
where Studenti.Spec = Discipline.Spec
and Studenti.An = Discipline.An;
Instrucţiunea Select de mai sus efectuează produsul cartezian al celor două tabele, şi selectează acele înregistrări pentru care sînt îndeplinite
condiţiile din clauza where. Aceste condiţii nu sînt de legătură,
deoarece între atributele implicate nu există o legătură de tip cheie primară - cheie externă. După ce am introdus notele dorim o situaţie a mediilor, ordonată pe specializări, ani de studiu, medie (descrescător), nume (alfabetic):
Select Notele.Nrls, Nume, Spec, Dens, An,
avg(Nota) as Media
from Notele, Studenti, Specializari
where Notele.Nrls = Studenti.Nrls
and Studenti.Spec = Cods
group by Notele.Nrls, Nume, Spec, Dens, An
order by 3,5,6,2;
Utilizarea instrucţiunii Select SQL în actualizare
Am văzut mai sus cum se utilizează instrucţiunea Select SQL în conexiune cu instrucţiunea Insert. Putem cere în plus actualizarea (modificarea sau ştergerea) unor înregistrări care îndeplinesc anumite condiţii, şi care se exprimă cu ajutorul unor selecţii. Un exemplu: în preajma unor sărbători (de Crăciun sau Paşte) un
furnizor (căruia îi ştim numele, dar nu şi codul) anunţă reduceri de preţ cu 15%. Aceste modificări se operează astfel:
UPDATE Oferte SET Pretu = Pretu * 0.85
WHERE Codf =
(SELECT Codf FROM Furnizori
WHERE Nume = '...');
În locul punctelor de suspensie introducem numele furnizorului. În mod asemănător se poate folosi instrucţiunea Select SQL în
conexiune cu instrucţiunea Delete.

38
4. Proiectarea bazelor de date
Ideea centrală care stă la baza proiectării unei baze de date relaţionale este
aceea de dependenţă a datelor. Aceasta se referă la faptul că între
atributele unei relaţii sau între atribute din relaţii diferite pot exista anumite
legături logice (dependenţe) şi acestea influenţează proprietăţile relaţiilor
în raport cu operaţiile de actualizare a bazei de date.
Dependenţe funcţionale
Presupunem că am proiectat o relaţie cu următoarea structură: CLFACTURI(Nrf,Codc,Numec,Adresa,Dataf)
Observăm dependenţa atributelor Numec şi Adresa faţă de atributul
Codc, şi de aici rezultă că fiecare valoare a atributului Codc
determină în mod univoc valoarea corespunzătoare a celorlalte două atribute. Această structură (schemă de relaţie) introduce o redundanţă
relativ la atributele Numec şi Adresa, ale căror valori se repetă
pentru fiecare factură a aceluiaşi client. Această redundanţă conduce la următoarele anomalii:
- la adăugare: nu se poate înregistra un potenţial client decît după ce se emite o factură pentru acesta; - la ştergere: dacă se şterg toate facturile emise pentru un anumit client se pierd toate informaţiile despre acesta; ulterior, dacă acesta cumpără nişte produse, informaţiile pe care tocmai le-am şters trebuie introduse din nou;
- la modificare: dacă se modifică o informaţie despre un anumit client (numele, adresa), este necesară parcurgerea întregii relaţii pentru a actualiza toate apariţiile acestui client; în caz contrar apare pericolul introducerii unei inconsistenţe în baza de date datorită faptului că pentru acelaşi client sînt înregistrate informaţii diferite.

39
Aceste anomalii pot fi evitate dacă se descompune relaţia
CLFACTURI în două relaţii: CLIENTI şi FACTURI, avînd
structurile:
CLIENTI(Codc,Numec,Adresa) FACTURI(Nrf,Codc,Dataf) Un „dezavantaj” al descompunerii efectuate este acela că pentru a obţine informaţiile despre un client pentru care am emis o factură este necesară efectuarea unei operaţii de cuplare a celor două relaţii.
Operaţia de cuplare (realizată printr-o instrucţiune Select care
extrage informaţii din cele două tabele) nu este atît de costisitoare pe cît ar putea părea la prima vedere, dacă se aleg în mod corespunzător cheile primare şi modalităţile de indexare.
După cum rezultă din exemplul de mai sus problema alegerii unui model conceptual corect pentru o bază de date relaţională este, de cele mai multe ori, formulată în termenii determinării unor descompuneri pentru scheme de relaţii date, descompuneri care să izoleze dependenţele existente şi prin aceasta să se evite anomaliile care decurg din ele.
Definiţia 1. Fie R(A1, A2,..., An) o relaţie, X şi Y două atribute (simple
sau compuse) submulţimi ale mulţimii de atribute (A1, A2,..., An). Atributul X determină atributul Y (sau Y depinde funcţional de X) şi
notăm XY dacă şi numai dacă orice valoare a atributului X determină în mod unic valoarea atributului Y.
Observaţii:
- dacă XY atunci pentru orice ZY avem XZ;
- dacă XY atunci pentru orice VX avem VY.
Definiţia 2. Fie XY o dependenţă funcţională; spunem că avem
dependenţă totală dacă nici o submulţime VX nu induce o
dependenţă funcţională VY; în caz contrar, dacă există o

40
submulţime VX care induce o dependenţă funcţională VY,
spunem că avem dependenţă parţială.
Existenţa în cadrul relaţiilor a dependenţelor funcţionale este un fapt natural. În orice relaţie există o dependenţă funcţională a oricărui atribut faţă de atributul cheie (sau setul de atribute care formează cheia primară): ştim că atributul cheie identifică în mod unic fiecare
tuplu. Dependenţele funcţionale existente în cadrul unei relaţii se datorează semanticii segmentului din lumea reală care se modelează prin această schemă şi reprezintă restricţii referitoare la realitatea modelată. Aceste restricţii constituie informaţii asociate relaţiei şi care nu pot fi înglobate în reprezentarea relaţiei, deşi se reflectă
indirect în această reprezentare prin valorile concrete pe care le iau atributele relaţiei. Singura cale de a determina dependenţele funcţionale din cadrul unei scheme de relaţie este aceea de a lua în considerare semnificaţia tuturor atributelor componente.
Primele trei forme normale
Am arătat mai sus că existenţa anumitor dependenţe funcţionale în cadrul unei scheme de relaţie conduce la o serie de anomalii legate de adăugare, ştergere sau modificare. Am văzut că aceste anomalii pot fi evitate dacă se înlocuiesc schemele de relaţii date prin altele echivalente, în cadrul cărora dependenţele sînt supuse anumitor restricţii. Aceste scheme de relaţii se numesc forme normale. Formele
normale constituie criterii de ghidare a proiectantului bazei de date în ceea ce priveşte alegerea schemelor de relaţie. Regulile de normalizare se aplică cu scopul de a evita anomaliile legate de adăugare, ştergere sau modificare. Efectul direct al normalizării este reducerea redundanţei datelor, redundanţă care constituie cauza tuturor acestor anomalii. Prin reducerea redundanţei se localizează efectul fiecărei operaţii de actualizare la un număr cît mai restrîns de tuple, ceea ce înseamnă creşterea gradului de independenţă reciprocă
a tuplelor. În cadrul acestei note de curs vom studia doar primele trei forme normale, care se definesc pe baza dependenţelor funcţionale stabilite

41
între cheia primară şi celelalte atribute non-cheie ale unei relaţii. În
majoritatea problemelor practice aceste trei forme normale sînt mai mult decît suficiente.
Definiţia 3. O relaţie R este în prima formă normală dacă şi numai dacă toate atributele sale iau numai valori atomice (scalare).
Această condiţie introduce restricţia ca domeniile pe care se definesc atributele relaţiei R să conţină doar valori atomice, ceea ce înseamnă că toate tuplele unei relaţii au acelaşi număr de cîmpuri (aceeaşi
dimensiune). Toate atributele unei relaţii trebuie să fie atribute simple, deci nu pot fi atribute compuse, iar valorile din cadrul tuplelor nu pot fi structuri, vectori sau tuple, Modelul relaţional nu studiază relaţii care au tuple de dimensiuni variabile. A doua şi a treia formă normală rezolvă problemele cauzate de existenţa dependenţelor funcţionale dintre atributele cheie şi cele non-cheie din cadrul tuplelor. Trecerea unei relaţii din prima formă
normală în a doua formă normală în procesul de normalizare a relaţiilor constă în izolarea tuturor dependenţelor funcţionale şi crearea unor relaţii noi definite cu ajutorul atributelor implicate în aceste dependenţe. Pentru fiecare dependenţă funcţională se creează o relaţie distinctă. Acest lucru este posibil atunci cînd relaţia dată are o cheie multiatribut.
Definiţia 4. O relaţie este în a doua formă normală dacă şi numai
dacă este în prima formă normală şi orice atribut non-cheie este total dependent faţă de cheia primară a relaţiei.
Pentru orice relaţie aflată în prima formă normală se poate găsi o descompunere în relaţii aflate în a doua formă normală care este echivalentă cu relaţia iniţială. Aceasta înseamnă că din relaţiile descompunerii se poate reconstitui prin cuplare întreg conţinutul de informaţie al relaţiei iniţiale. Aşadar înlocuirea unei relaţii printr-o descompunere a sa în relaţii aflate în a doua formă normală este un
proces reversibil. Avantajul acestei înlocuiri este evitarea unor anomalii legate de operaţiile de adăugare, ştergere şi modificare. Dar oare sînt evitate toate aceste anomalii?

42
Exemplu. Fie schema de relaţie
PRODFACT (Nrf, Codc, Dataf, Codp, Cant)
avînd ca şi cheie primară setul (Nrf,Codp) şi următoarele
dependenţe funcţionale:
– Nrf(Codc,Dataf);
– (Nrf,Codp)Cant; aceasta deoarece pe o factură putem avea
mai multe produse, şi un acelaşi produs poate apărea pe mai multe facturi.
Deoarece setul (Codc,Dataf) depinde total numai de Nrf,
redundanţa are drept consecinţă o anomalie la adăugare: pentru fiecare poziţie de pe factură aceste informaţii trebuie repetate. Ca dovadă că se poate mai rău decît în exemplul de mai sus, să ne imaginăm ce consecinţe ar avea utilizarea unei structuri cum este cea
de mai jos:
TOTFACT(Nrf, Codc, Numec, Adresa, Dataf, Codp, Denp, Pret, Cant)
Remarcăm o serie de dependenţe funcţionale, dintre care prezentăm cîteva mai semnificative:
Nrf(Codc,Numec,Adresa,Dataf);
Codc(Numec,Adresa);
Codp(Denp,Pret);
(Nrf,Codp)Cant.
Dependenţa Nrf(Numec,Adresa) se numeşte tranzitivă,
deoarece ea se deduce din NrfCodc şi
Codc(Numec,Adresa); o ignorăm pentru moment. Să
descompunem această schemă astfel:

43
CLFACTURI(Nrf,Codc,Numec,Adresa,Dataf) PRODUSE(Codp,Denp,Pret) DETALII(Nrf,Codp,Cant)
Se poate verifica faptul că toate cele trei scheme se află în a doua formă normală. Recompunerea relaţiei originale se poate face cu ajutorul unei instrucţiuni Select SQL. Ceva nu e în regulă cu această descompunere se observă o redundanţă supărătoare în schema
CLFACTURI, datorită atributelor Numec şi Adresa. Aceasta
generează aceleaşi anomalii la adăugare, ştergere sau modificare, deoarece am ignorat dependenţele funcţionale tranzitive.
Definiţia 5. O relaţie R este în a treia formă normală dacă şi numai
dacă este în a doua formă normală şi toate atributele non-cheie sînt total dependente numai de cheia primară şi nu şi de alte atribute non-cheie.
Să reluăm exemplul de mai sus. Schema CLFACTURI se descompune mai departe astfel:
CLIENTI(Codc,Numec,Adresa) FACTURI(Nrf,Codc,Dataf)
Proiectarea structurii unei baze de date
Analiza problemei pe care trebuie să o rezolvăm identifică toate informaţiile care se introduc în baza de date. Se identifică de asemenea toate corelaţiile care există între aceste informaţii - se
identifică în fond dependenţele funcţionale. Pentru a putea identifica mai uşor aceste corelaţii se recomandă ca în baza de date fiecare entitate care se înregistrează să aibă o cheie de identificare (un cod). Toate informaţiile care se deduc dintr-o astfel de cheie (cod) se înregistrează într-o relaţie asociată clasei respective de entităţi. Descompunerea unei scheme de relaţie se face pînă cînd toate schemele de relaţie se află în a treia formă normală.

44
Exemplu. Analiza unei probleme de evidenţă a comenzilor a pus în
evidenţă următoarele informaţii care trebuie înregistrate în baza de date: – despre furnizori: cod, nume, adresa; fiecare furnizor îşi prezintă oferta - o listă de produse: cod, denumire, preţ; – un furnizor poate prezenta mai multe produse pe ofertă, un acelaşi produs poate apărea pe ofertele mai multor furnizori cu preţuri
diferite; toată lumea foloseşte un sistem unic de codificare a produselor; – pe o comandă adresată unui furnizor apare: furnizorul, data comenzii, lista produselor comandate (pentru fiecare produs, cantitatea comandată). Atributele cu care operăm în continuare sînt:
Codf, Numef, Adresa, Codp, Denp, Pret, Nrc, Datac, Cant.
Dependenţele funcţionale de bază pe care le-am identificat (am evitat orice dependenţe tranzitive):
Codf(Numef,Adresa);
CodpDenp; preţul nu poate apărea aici deoarece el diferă de
la un furnizor la altul;
(Codf,Codp)Pret;
Nrc(Codf,Datac);
(Nrc,Codp)Cant.
Din aceste dependenţe funcţionale de bază se deduc imediat schemele de relaţie care vor compune baza de date.