notiuni introductive - departamentul de informaticăid.inf.ucv.ro/~cpopirlan/ecnpd/curs1.pdf · •...
TRANSCRIPT

Notiuni introductive
1 Arhitecturi paralele si distribuitePentru a realiza un studiu al metodelor numerice paralele si distribuite ar trebui in primul rand sa ne raportamla diferentele lor fata de implementarile seriale:
• alocarea task-urilor;
• comunicarea intre procesoare a rezultatele intermediare obtinute prin calcul;
• sincronizarea calculelor efectuate de procesoare. De aici se obtine o clasificare a metodelor: metodesincrone si metode asincrone.
Calculul paralel si distribuit reprezinta in prezent un domeniu larg de interes existand o activitate de cerc-etare intensa in acest sens motivata de numerosi factori. Intotdeauna a fost nevoie de o solutie de rezolvare aproblemelor cu calcule foarte mari, dar, doar recent, tehnologiile avansate au luat in calcul folosirea calcululuiparalel in rezolvarea acestor probleme tinand cont si de calculatoarele paralele din ce in ce mai puternice.
Dezvolatarea algoritmilor paraleli si distribuiti este determinata pe de o parte de legatura dintre nevoilede calcul noi si cele vechi, iar pe de alta parte de progresul tehnologic.
Aplicatiile care privesc inteligenta artificiala, calculul simbolic si calculul numeric sunt cele care au jucatun rol important in dezvoltarea arhitecturilor paralele si distribuite.
Nevoia de determinare rapida a unui numar mare de calcule numerice din cadrul aplicatiilor ce privescrezolvarea ecuatiilor cu derivate partiale si a procesarii imaginilor a fost ceea ce a dus la dezvoltarea rapiditatiisi a paralelizarii masinilor de calcul.
Recent a crescut interesul pentru aplicarea calculului paralel si distribuit in aplicatii precum cele ce privescanaliza, simularea si optimizarea la scara larga a sistemelor interconectate. Alte exemple de aplicare a calcu-lului paralel sunt: rezolvarea sistemelor de ecuatii, programarea matematica si problemele de optimizare. Oproprietate comuna a acestor probleme este aceea de a putea fi descompuse in subtask-uri.
O distictie importanta este intre sistemele de calculul paralel si cele de calcul distribuit.Sistemele de calcul paralel consistau in mai multe procesoare care sunt localizate la o distanta mica unele
de altele si care au fost concepute in scopul realizarii de taskuri de calcul in comun. Comunicarea dintreprocesoare este de incredere si poate fi anticipata.
Sistemele de calcul distribuit sunt diferite din mau multe puncte de vedere: procesoarele pot fi separate sicomunicarea dintre ele este mult mai problematica; intarzierile de comunicare nu pot fi anticipate si legaturilede comunicatie pot sa nu fie de incredere; fiecare procesor poate fi angajat in propriile sale activitati in timpce coopereaza cu alte procesoare pentru realizarea unui task comun.
Sunt mai multi parametrii care pot fi folositi pentru a descrie sau pentru a clasifica sistemele de calculparalel:
• tipul si numarul de procesoare. Sunt sisteme de calcul paralel care au multe procesoare numite masivparalele si sunt sisteme cu un numar mic de procesoare numite coarse grained parallelism.
• prezenta sau absenta unei masini de control global. O clasificare privind acest aspect si referindu-ne laabilitatea diferitelor procesoare de a executa diferite instructiuni la un moment dat este in calculatoareparalele SIMD (Single Instruction Multiple Data) si MIMD (Multiple Instruction Multiple Data).
1

• operatii sincrone si asincrone. Distinctia in acest caz se refera la prezenta sau absenta unui ceasglobal folosit pentru a sincroniza operatiile diferitelor procesoare. Aceasta sincronizare este intot-deauna prezenta in SIMD. Operatiile sincrone sunt de preferat datorita catorva proprietati importante:comportamentul procesoarelor este mult mai usor de controlat si algoritmul este mult simplificat. Darin unele cazuri este destul de greu de sincronizat o retea de comunicare de date.
• legaturile dintre procesoare. Un aspect important al calculatoarelor paralele este mecanismul prin careprocesoarele fac schimb de informatii. Din acest punct de vedere exista doua cazuri: arhitecturi cumemorie comuna si arhitecturi care transmit mesaje. Plecand de la aceste doua tipuri de arhitecturiavem numerosi hibrizi. Cel mai des intalnit mod de a lucra cu memoria este switching systems (sistemede comutare) asa cum se poate observa in figura 1. Exista situatii in care nu avem memorie comuna, darfiecare procesor are propria sa memorie locala. In aceasta situatie procesoarele pot comunica printr-oretea de comunicare care consta in legaturi de conexiune care leaga anumite perechi de procesoare(2). Apare astfel problema de a stabili care procesoare sunt conectate. Ar fi de preferat daca toateprocesoarele ar fi direct conectate unele cu altele, sau daca pot fi legate printr-un numar de legaturiaditionale.
Figure 1: Sistem de conectare
Figure 2: Retea de comunicare
Structura retelei de conectare este foarte importanta atat in sistemele de calcul paralel cat si in cele decalcul distribuit dar cu o diferenta: in calculatoarele paralele reteaua de conectare este sub controlulunui designer si din aceasta cauza de obicei este regulata, iar in sistemele distribuite topologia reteleieste predeterminata si iregulata.
2

2 Modele si exempleExista o varietate de modele de calcule paralele si distribuite. Un model simplu folosit in general in calcululparalel pentru algoritmi asincroni este acela al reprezentarii algoritmilor paraleli prin grafuri directe aciclice.Fiecare nod al grafului reprezinta operatiile pe care le face algoritmul si fiecare arc este folosit pentru areprezenta dependenta datelor. In particular, un arc (i, j) indica faptul ca operatia corespunzatoare nodului jfoloseste rezultatele operatiei corespunzatoare nodului i. Un astfel de exemplu este cel din figura 3.
Figure 3: Exemplu de graf direct orientat pentru (x1 + x2)(x2 + x3)
Un graf direct orientat realizeaza doar o reprezentare partiala a unui algoritm. In cadrul grafului suntspecificate operatiile care se efectueaza, operanzii si impune anumite conditii privind ordinea in care acesteoperatii se efectueaza. Pentru a determina un algoritm paralel trebuie sa specificam si ce procesor executa oanumita operatie si la ce moment o executa. Pentru aceasta trebuie impus ca un procesor sa execute cel multo operatie la un moment dat, si ca daca avem un nod (i, j) atunci operatia care ii corespunde nodului j poateincepe doar dupa ce operatia corespunzatoare nodului i a fost terminata.
Exista situatii cand pentru aceeasi problema de calcul exista mai multi algoritmi, deci sunt situatii incare avem mai multe grafuri direct orientate pentru rezolvarea unei probleme (figura 4). Apare astfel situatiadeterminarii unui graf ce minimizeaza timpul de calcul al solutiei problemei. Pentru cateva clase de problemeexista metode care construiesc un graf direct orientat cu un factor constant de optimizare.
In continuare consideram cateva exemple simple de taskuri de calcul numeric care pot fi reprezentate prinalgoritmi paraleli simpli. Toti algorimii considerati pot fi reprezentati printr-un graf direct orientat. Pentru ausura calculele presupunem ca fiecare operatie este executata intr-o unitate de timp si ca transmiterea de dateintre procesoare se realizeaza instantaneu.
2.1 Calcule cu vectori si matrici1. Adunarea scalarilor
Cea mai simpla sarcina de calcul este aceea de a aduna n scalari. Cel mai bun algoritm serial necesitan− 1 operatii, deci timpul de executie al algoritmului este n− 1.
In continuare prezentam un algoritm paralel construit sub presupunerea ca n este o putere a lui 2.Partitionam cei n scalari in n
2 perechi diferite si folosim n2 procesoare pentru a aduna cei doi scalari
din fiecare pereche. Deci, dupa o unitate de timp, avem de executat sarcina de a aduna n2 scalari.
Continuand in aceeasi maniera, dupa log n pasi vom mai avea de efectuat o singura adunare si calculul
3

Figure 4: Graf direct orientat pentru (x1 + x2)(x2 + x3)
se va termina (figura 5). Acest algoritm poate fi generalizat la cazul in care n nu este putere a lui 2 siastfel timpul de executie devine ⌈log n⌉ folosind ⌊n
2 ⌋ procesoare.
Figure 5: Calcul paralel pentru adunarea a 16/15 scalari
Aceeasi problema a adunarii a n scalri poate fi rezolvata folosind graful direct orientat reprezentat infigura 6 si care aduce o imbunatatire a eficientei algoritmului.
2. Produsul scalar
Produsul scalarn∑
i=1
xiyi a doi vectori n-dimensionali poate fi calculata cu cu n procesoare in ⌈log n⌉+1
unitati de timp astfel: la primul pas fiecare procesor i calculeaza produsul xiyi si apoi avem nevoie de⌈log n⌉ unitati de timp pentru adunarea scalarilor folosind algoritmul anterior.
3. Adunarea si inmultirea matricilor
Suma a n matrici de dimensiune m×m poate fi calculta in ⌈log n⌉ unitati de timp si folosind m2⌊n2 ⌋
procesoare.
Inmultirea a doua matrici de dimensiune m × n si n × l consta in evaluarea a ml produse scalare devectori n-dimensionali si poate fi deci indeplinita in ⌈log n⌉+1 unitati de timp folosind nml procesoare.
4. Puterile unei matrici
4

Figure 6: Algoritm alternativ pentru adunarea paralela a 16 scalari
Presupunem ca avem o matrice A de dimensiune n×n si dorim sa calculam Ak pentru k ∈ Z . Daca keste putere a lui 2, atunci task-ul poate fi indeplinit prin pasi repetitivi: calculam intai A2, apoi A2A2 =A4, etc. Dupa log k pasi se obtine Ak. Aceasta procedura presupune log k inmultiri consecutive dematrici si poate fi deci incheiata in log k(⌈log n⌉+ 1) unitati de timp folosind n3 procesoare.
O alta situatie de calcul a puterii unei matrici este reprezentata in figura 7.
Figure 7: Calcul paralel al puterilor unei matrici
2.2 Paralelizarea metodelor iterativePentru rezolvarea de sisteme de ecuatii, pentru optimizari si alte tipuri de probleme se folosesc in generalalgoritmi iterativi (metode de relaxare) de tipul:
x(t+ 1) = f(x(t)), t = 0, 1, . . . (1)
5

unde fiecare x(t) este un vector n-dimensional si f : Rn → Rn.O notatie alternativa este x = f(x). Daca sirul {x(t)} generat de (1) este convergent la x∗ si daca functia
f este continua, atunci x∗ este punct fix al lui f , f(x∗) = x∗.Fie xi(t) componenta i a lui x(t) si fie fi componenta i a functiei f . Atunci putem scrie (1) ca:
xi(t+ 1) = fi(x1(t), . . . , xn(t)), i = 1, n (2)
Algoritmul iterativ x = f(x) poate fi paralelizat prin luarea a n procesoare care sa calculeze o componentadiferita a lui x, asa cum se observa in (2). La fiecare pas, procesorul i cunoaste valorile tuturor componentelorlui x(t) de care depinde fi, calculeaza noua valoare a lui xi(t+1) si comunica aceasta valoare altor procesoarepentru a se putea trece la urmatoarea iteratie.
Comunicatiile necesare pentru executia unei iteratii de tipul (2) pot fi descrise cu ajutorul unui graf directca cel reprezentat in figura 8, numit si graf de dependenta. Nodurile reprezinta componentele lui x si pentrufiecare doua noduri i si j exista arcul (i, j), daca functia fj depinde de xi, asta inseamna ca procesorul itrebuie sa comunice valoarea lui xi(t) procesorului j.
Figure 8: Graf de dependenta
Graful din figura 8 este realizat pentru urmatoarea situatie:x1(t+ 1) = f1(x1(t), x3(t))x2(t+ 1) = f2(x1(t), x2(t))x3(t+ 1) = f3(x2(t), x3(t), x4(t))x4(t+ 1) = f4(x2(t), x4(t))
Daca presupunem ca procesul iterativ reprezentat in ecuatia (1) se termina in T pasi, T ∈ N , structuraalgoritmului poate fi reprezentata printr-un graf direct orientat (9).
2.2.1 Iteratia Seidel-Gauss
Iteratia (2) in care toate componentele lui x sunt updatate simultan este numita iteratie de tip Jacobi. Intr-oforma alternativa, componentele lui x sunt updatate pe rand si valoarea cel mai recent calculata este folosita.Astfel ecuatia (2) devine:
xi(t+ 1) = fi(x1(t+ 1), . . . , xi−1(t+ 1), xi(t), . . . , xn(t)), i = 1, n (3)
Iteratia (3) se numeste algoritmul Seidel-Gauss bazat pe functia f .
Example 2.1 Consideram urmatoarea situatie:x1(t+ 1) = f1(x1(t), x3(t))x2(t+ 1) = f2(x1(t+ 1), x2(t))x3(t+ 1) = f3(x2(t+ 1), x3(t), x4(t))x4(t+ 1) = f4(x2(t+ 1), x4(t))
6

Figure 9: Graf direct orientat asociat grafului de dependenta
Figure 10: Paralelizarea iteratiei Seidel-Gauss
Exista mai multe alternative ale algoritmului Seidel-Gauss corespunzator functiei f , deoarece ordineain care sunt updatate componentele poate fi diferita. Atata timp cat viteza de convergenta nu se modificasemnificativ este natural sa schimbam ordinea de calcul a componentelor astfel incat paralelismul la fiecareiteratie este fie maximizat.
Example 2.2 Consideram urmatoarea situatie:x1(t+ 1) = f1(x1(t), x3(t))x3(t+ 1) = f3(x2(t+ 1), x3(t), x4(t))x4(t+ 1) = f4(x2(t+ 1), x4(t))x2(t+ 1) = f2(x1(t+ 1), x2(t))
Proposition 2.1 Urmatoarele afirmatii sunt echivalente:
7

Figure 11: Paralelizarea iteratiei Seidel-Gauss - alta ordine de updatare a componentelor
• Exista o ordine a variabilelor astfel incat o parte a algoritmului Seidel-Gauss sa poata fi executata inK pasi paraleli.
• Exista o colorare a grafului de dependenta care foloseste K culori si cu proprietatea ca nu exista unciclu pozitiv cu toate nodurile intr-un ciclu care au aceleasi culori.
• Exista o colorare a grafului de dependenta care foloseste cel mult K culori astfel incat nodurile adia-cente au culori diferite.
In cazul in care consideram exemplul din figura 8, doua culori sunt suficiente: h(1) = h(3) = h(4) = 1si h(2) = 2.
In cazul in care se folosesc schemele cu culori pentru o implementare paralela a algoritmului Seidel-Gauss, este usor de folosit cate un procesor diferit pentru fiecare componenta a lui x, deoarece fiecare procesorva fi idle atata timp cat sunt updatate variabile de culori diferite. Un remediu imediat ar fi acela de a folosimai putine procesoare, fiecare procesor avand asignate mai multe variabile de culori diferite.
Example 2.3 Intr-o varietate de algoritmi de forma x = f(x), folositi pentru rezolvarea de ecuatii cuderivate partiale sau in procesarea de imagini, fiecarei componente a vectorului x ii este asociat un punctparticular dintr-o anumita regiune dintr-un spatiu 2-dimensional.
Fie N multimea tuturor punctelor (i, j) ∈ R2 astfel incat i si j sunt numere intregi ce satisfac 0 ≤ i ≤ Msi 0 ≤ j ≤ M . Fie xij o componenta a vectorului x care corespunde punctului (i, j). Prin conectarea celormai apropiati vecini obtinem graful reprezentat in figura 12. Vedem acest graf ca si graf direct daca facemarcele bidirectionale si presupunem ca este un graf de dependenta asociat ecuatiei x = f(x). Asignam cateun procesor fiecarui punct (i, j). Acest procesor este responsabil de updatarea valorii lui xij si pentru aface acest lucru are nevoie sa cunoasca valorile componentelor lui x asociate punctelor vecine. Este astfelnatural de presupus ca procesoarele asociate punctelor vecine sunt unite printr-o conexiune directa.
In ceea ce priveste implementarea unei metode Seidel-Gauss asociate situatiei prezentate, observam cagraful din figura 12 poate fi colorat folosind doua culori asa cum se observa in figura 13. Daca asignamcate un procesor fiecarei componente xij , atunci acesta va fi idle jumatate din timp. Este deci rezonabil saasignam doua componente de culori diferite fiecarui procesor. In practica, numarul de puncte este foartemare si deci fiecare procesor va avea asignate mai mult de doua puncte.
3 Exercitii1. Se considera urmatoarea ecuatie:
8
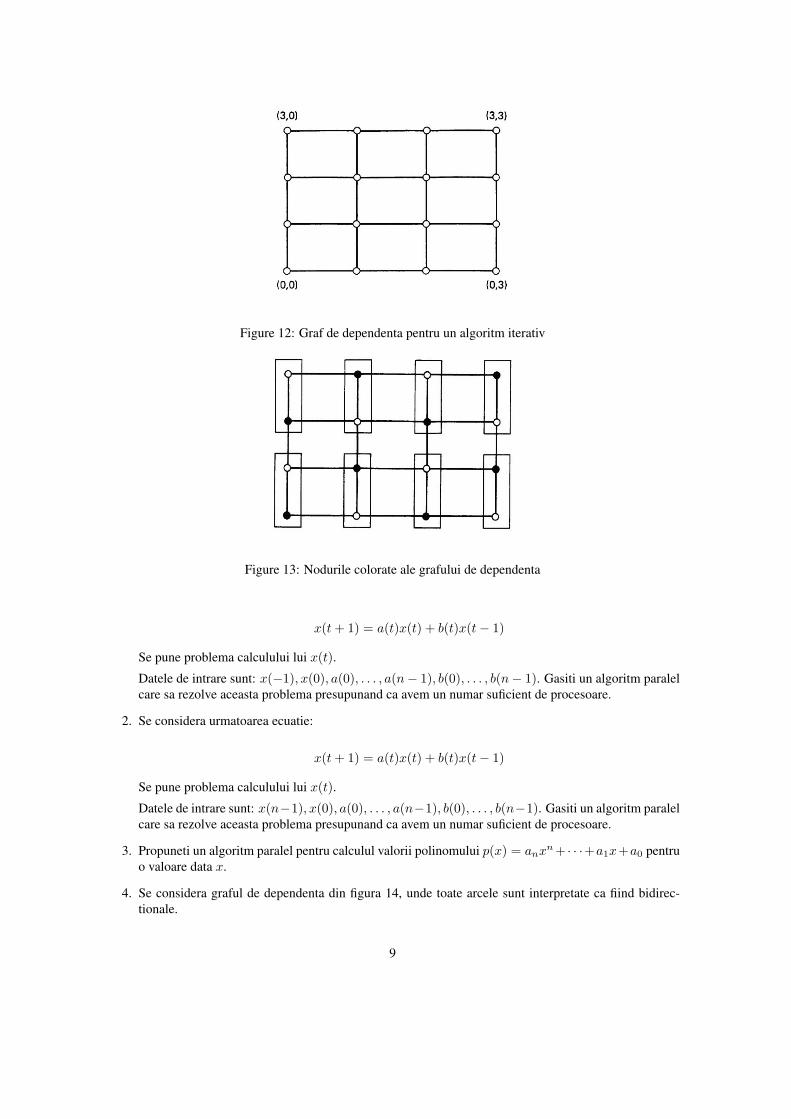
Figure 12: Graf de dependenta pentru un algoritm iterativ
Figure 13: Nodurile colorate ale grafului de dependenta
x(t+ 1) = a(t)x(t) + b(t)x(t− 1)
Se pune problema calculului lui x(t).
Datele de intrare sunt: x(−1), x(0), a(0), . . . , a(n− 1), b(0), . . . , b(n− 1). Gasiti un algoritm paralelcare sa rezolve aceasta problema presupunand ca avem un numar suficient de procesoare.
2. Se considera urmatoarea ecuatie:
x(t+ 1) = a(t)x(t) + b(t)x(t− 1)
Se pune problema calculului lui x(t).
Datele de intrare sunt: x(n−1), x(0), a(0), . . . , a(n−1), b(0), . . . , b(n−1). Gasiti un algoritm paralelcare sa rezolve aceasta problema presupunand ca avem un numar suficient de procesoare.
3. Propuneti un algoritm paralel pentru calculul valorii polinomului p(x) = anxn+ · · ·+a1x+a0 pentru
o valoare data x.
4. Se considera graful de dependenta din figura 14, unde toate arcele sunt interpretate ca fiind bidirec-tionale.
9

Figure 14: Graf de dependenta - exercitiu
• Precizati cu cate culori poate fi colorat graful si care este numarul minim de culori.
• Verificati de cate procesoare aveti nevoie penru o implementare paralela.
10