lucrare de licenŢĂ - profs.info.uaic.roadiftene/licenta/licenta2012_daneliuc... · 1...
TRANSCRIPT

1
UNIVERSITATEA ALEXANDRU IOAN CUZA IAŞI FACULTATEA DE INFORMATICĂ
LUCRARE DE LICENŢĂ
Augmented Reality – OCR şi recunoaştere entităţi
textuale semnificative
Absolventă: Coordonator științific:
Daneliuc A. Ana-Maria Lector Dr. Adrian Iftene
Sesiunea: iulie 2012

2
Declaraţie privind originalitatea şi respectarea drepturilor de autor
Prin prezenta declar că Lucrarea de licență cu titlul “Augmented Reality – OCR şi
recunoaştere entităţi textuale semnificative” este scrisă de mine și nu a mai fost prezentată
niciodată la o altă facultate sau instituție de învățământ superior din țară sau străinătate. De
asemenea, declar că toate sursele utilizate, inclusiv cele preluate de pe Internet, sunt indicate în
lucrare, cu respectarea regulilor de evitare a plagiatului:
- toate fragmentele de text reproduse exact, chiar și în traducere proprie din altă limbă,
sunt scrise în ghilimele și dețin referința precisă a sursei;
- reformularea în cuvinte proprii a textelor scrise de către alți autori deține referință
precisă;
- codul sursă, imagini etc. preluate din proiecte open-source sau alte surse sunt utilizate
cu respectarea drepturilor de autor și dețin referințe precise;
- rezumarea ideilor altor autori precizează referința precisă la textul original
Absolventă Ana-Maria Daneliuc,
_________________________
(semnătura în original)

3
Declaraţie de consimţământ
Prin prezenta declar că Lucrarea de licență cu titlul “Augmented Reality– OCR şi
recunoaştere entităţi textuale semnificative”, codul sursă al programelor și celelalte conținuturi
(grafice, multimedia, date de test, etc.) care însoțesc această lucrare să fie utilizate în cadrul
Facultății de Informatică. De asemenea, sunt de acord ca Facultatea de Informatică de la
Universitatea Alexandru Ioan Cuza Iași să utilizeze, modifice, reproducă și să distribuie în
scopuri necomerciale programele-calculator, format executabil și sursă, realizate de mine în
cadrul prezentei lucrări de licență.
Absolventă Ana-Maria Daneliuc,
_________________________
(semnătura în original)

4
Cuprins
Motivaţie ....................................................................................................................................................... 6
Contribuţii ..................................................................................................................................................... 7
Introducere .................................................................................................................................................... 8
I. Realitate augmentată (Augmented Reality) .......................................................................................... 9
I.1 Introducere .......................................................................................................................................... 9
I.2 Platforme şi aplicaţii de realitate augmentată existente ..................................................................... 10
I.2.1 Layar Reality Browser ............................................................................................................ 10
I.2.2 Wikitude World Browser ........................................................................................................ 11
I.2.3 Google Goggles....................................................................................................................... 12
I.2.4 Look! ........................................................................................................................................ 12
II. Recunoaşterea optică a caracterelor .................................................................................................... 13
II.1 Definiţie şi clasificare ....................................................................................................................... 13
II.2 OCR cu reţele neuronale .................................................................................................................. 14
II.3 Reţele neuronale artificiale ............................................................................................................... 16
II.3.1 Structură şi comportament .................................................................................................. 16
II.3.2 Clasificare .................................................................................................................................. 18
II.3.3 Perceptroni .......................................................................................................................... 19
II.3.4 Reţele neuronale multistratificate ....................................................................................... 23
II.3.5 Concluzii: aplicabilitatea reţelelor neuronale artificiale ..................................................... 27
II.4 Tesseract ........................................................................................................................................... 28
II.4.1 Scurt istoric ......................................................................................................................... 28
II.4.2 Arhitectură şi flux de lucru ................................................................................................. 29
II.4.3 Concluzii ............................................................................................................................. 37
III. Recunoaşterea entităţilor textuale de tip nume ............................................................................... 39
III.1 Introducere în domeniul Extragerii de Informaţii ........................................................................... 39
III.2 Definirea recunoaşterii entitӑţilor de tip nume................................................................................ 40
III.3 Tehnici pentru NER ........................................................................................................................ 41
III.4 LingPipe .......................................................................................................................................... 42
III.4.1 Algoritmul Best First pentru LingPipe Named Entity Recognizer .......................................... 43

5
III.4.2 Algoritmul N-Best pentru LingPipe Named Entity Recognizer .............................................. 44
III.4.3 Algoritmul Confidence pentru LingPipe Named Entity Recognizer ....................................... 45
III.5 Concluzii ......................................................................................................................................... 46
IV. Arhitectura aplicaţiei ....................................................................................................................... 47
IV.1 Modulul OCR ................................................................................................................................. 47
IV.1.1 Funcţionalitate generală ...................................................................................................... 47
IV.1.2 Integrare în proiect .............................................................................................................. 48
IV.2 Modulul de traducere ...................................................................................................................... 55
IV.3 Modulul de recunoaştere a entităţilor textuale semnificative ......................................................... 56
IV.3.1 Componente ........................................................................................................................ 56
IV.3.2 Funcţionare ......................................................................................................................... 57
IV.3.3 Rezultate ............................................................................................................................. 58
IV.4 Modulul de extragere a informaţiilor externe ................................................................................. 59
IV.5 Schema generalӑ a aplicaţiei ........................................................................................................... 60
V. Concluziile lucrӑrii şi direcţii de dezvoltare ....................................................................................... 62
VI. Bibliografie ..................................................................................................................................... 63

6
Motivaţie
Smartphone-urile au devenit o componentӑ indispensabilӑ în viaţa de zi cu zi, înglobând
într-un singur dispozitiv atât un telefon, cât şi un aparat de fotografiat/filmat, GPS, internet,
agendӑ şi multiple aplicaţii care combinӑ aceste facilitӑţi pentru a îmbunӑtӑţi şi facilita
comunicarea, interacţiunea cu societatea, organizarea programului zilnic. Telefoanele au
configuraţii din ce în ce mai bune, care permit şi efectuarea de taskuri complicate şi costisitoare,
cu anumite limitӑri, bineînţeles, dar totuşi transformӑ în realiate ceea ce odinioarӑ pӑrea
imposibil pe un dispozitiv atât de mic.
Aplicaţiile bazate pe realitatea augmentatӑ utilizeazӑ toate aceste capabilitӑţi
extraordinare ale platformelor mobile puternice, pentru o experienţӑ vizualӑ şi cognitivӑ
superioare. Majoritatea aplicaţiilor de acest fel sunt de tip AR Browser, afişând pe suprafaţa
ecranului puncte de interes din diverse arii, de cele mai multe ori în funcţie de poziţia geograficӑ,
dar şi de aproprierea sau depӑrtarea de anumite persoane, în cadrul unei reţele sociale
personalizate.
Aplicaţiile care se bazeazӑ pe recunoaşterea sau clasificarea de imagini, text sau persoane
sunt însӑ mai puţine, poate şi datoritӑ complexitӑţii algoritmilor şi strategiilor ce stau la baza
acestor sarcini din domeniul inteligenţei artificiale.
Prin prezentul proiect de licenţӑ, am dezvoltat un sistem capabil sӑ pozeze un text, prin
încadrarea sa exactӑ, sӑ îl recunoascӑ (OCR), sӑ îl traducӑ şi sӑ extragӑ din el entitӑţi
semnificative de tip nume, pe care sӑ le afişeze apoi cu informaţii suplimentare, preluate de pe
internet. Astfel se realizeazӑ o augmentare a textului, lucrarea intrând in categoria de realitate
augmentatӑ descrisӑ mai sus. Tehnologiile folosite sunt alese astfel încât sӑ se preteze la
integrarea pe un telefon cu sistemul de operare Android.Este posibilӑ şi distribuirea şi stocarea
textului rezultat în diverse moduri.
Un use-case tipic ar fi pentru un turist aflat într-o ţarӑ strӑinӑ, care nu cunoaşte limba şi ar
dori sӑ afle informaţii de interes despre diferite locaţii şi obiective turistice, într-o manierӑ cât
mai centralizatӑ cu putinţӑ. Dat fiind cӑ pozarea unui text este mai rapidӑ decât tastarea sa şi

7
ţinând cont de calitatea ridicatӑ a imaginii camerelor de pe telefoanele “inteligente”, aplicaţia se
poate dovedi de un real ajutor.
Contribuţii
Proiectul îmbinӑ ideile personale cu cele ale d-lui coordonator, pentru a realiza o
structurӑ unitarӑ, cu funcţionalitӑţi precise, uşor configurabile şi afişare a rezultatelor într-o
manierӑ cât mai prietenoasӑ. Este scris în limbajul Java Android.
Arhitectura generalӑ a aplicaţiei este conceputӑ în cea mai mare mӑsurӑ de mine, având
totuşi ca repere [14], o aplicaţie pentru scanare coduri de bare, de la care m-am inspirat în lucrul
cu camera şi [13], de la care am preluat modul de desenare al dreptunghiului de încadrare,
precum şi paşii necesari pentru integrarea motorului OCR, mai ales în modul continuu. Codul
respectiv este însӑ adaptat la cerinţele aplicaţiei mele.
Folosesc Tesseract drept componentӑ OCR, care necesitӑ prelucrarea imaginii surprinse
de camerӑ într-un format corespunzӑtor, descӑrcarea fişierelor antrenate pe seturile de caractere,
precum şi setarea unor parametri corespunzӑtori. Folosesc biblioteca Jtar pentru dezarhivarea
fişierelor antrenate descӑrcate.
Traducerea se realizeazӑ prin apeluri cӑtre un serviciu web, Microsoft Translator, cel mai
performant serviciu gratuit actual. Cu ajutorul biblioteca Gson, parsez rӑspunsul de la el.
Pentru componenta de recunoaştere a entitӑţilor textuale, folosesc o strategie proprie, care
presupune însӑ şi integrarea unui NER cât mai lightweight, (LingPipe), antrenat statistic pentru
deducerea din context a tipului entitӑţii. Pentru corectarea rezultatelor sale, folosesc o combinaţie
de expresii regulate, bazӑ de date predefinitӑ, euristici personale şi feedback utilizator.
Modulul de extragere a informaţiilor externe de pe Wikipedia şi Google Maps este gândit
şi scris în totalitate de mine, folosindu-mӑ de biblioteca Jsoup pentru parsarea sursei html.
Toate tehnologiile sunt open-source (în cazul bibliotecilor) sau se încadreazӑ într-un plan
personal gratuit, cu numӑr de cuvinte limitat pe lunӑ (2 milioane), în cazul Microsoft Translator.

8
Introducere
În capitolul 1 al acestei lucrӑri voi face o introducere a paradigmei de Augmented Reality,
în care am dorit sӑ integrez aplicaţia mea. Voi arӑta scopurile în care poate fi dezvoltatӑ, care nu
sunt doar pentru entertainment, ci pot aduce o contribuţie realӑ societӑţii sau unui anumit
segment de public. Voi prezenta pe scurt aplicaţiile de acest tip cele mai populare la ora actualӑ,
cu plusuri şi minusuri, cea mai apropiatӑ de ideea lucrӑrii mele fiind Google Goggles.
În capitolul 2 dezvolt teoria recunoaşterii optice a caracterelor, prin prezentarea extensivӑ
a reţelelor neuronale şi a algoritmilor lor, care stau la baza clasificatorilor din motoarele de OCR-
izare. Continuu cu un studiu de caz asupra motorului Tesseract, cel mai performant dintre
motoarele open-source existente, prezentând fluxul de lucru, strategiile şi algoritmii folosiţi. La
sfârşit fac un bilanţ al aspectelor pozitive şi al celor negative, care îl împiedicӑ poate sӑ se
apropie mai mult de acurateţea soft-urilor comerciale.
Capitolul 3 reprezintӑ o incursiune în domeniul NLP (Natural Language Processing),
mai exact în ramura recunoaşterii entitӑţilor de tip nume (NER), sumarizând câteva din tehnicile
folosite la ora actualӑ. Am efectuat şi un studiu de caz asupra bibliotecii lightweight LingPipe, o
alternativӑ fezabilӑ pentru telefon la aplicaţiile monolitice folosite la ora actualӑ de sistemele mai
performante. Sunt necesare însӑ şi alte tehnici de corectare a rezultatelor.
În capitolul 4 voi descrie arhitectura aplicaţiei mele, prezentând în parte fiecare din cele 4
module principale: modulul OCR, modulul de traducere, modulul de extragere a entitӑţilor de tip
nume semnificative şi modulul colectӑrii de informaţii externe, descriindu-le detaliat pe fiecare
în parte. La sfârşit, ataşez o schemӑ generalӑ a funcţionӑrii aplicaţiei, care face vizibilӑ
conectarea acestor module, precum şi explicaţii suplimentare.
Voi încheia cu concluziile învӑţate în urma lucrului la aceastӑ aplicaţie şi voi enumera
direcţiile de dezvoltare ulterioarӑ la care m-am gândit, ce include mai multe funcţionalitӑţi, dar şi
îmbunӑtӑţirea celor deja existente.

9
I. Realitate augmentată (Augmented Reality)
I.1 Introducere
Mult anticipata şi experimentala tehnologie pe care odinioară o vedeam doar în filmele
science-fiction este acum realitate. Vorbim despre realitatea augmentată (augmented reality,
abreviat AR), cea mai nouă şi sofisticată direcţie software abordată în zilele noastre, cu un impact
decisiv asupra utilizatorului final.
Putem afirma despre acest concept că reprezintă atât o tehnologie, cât şi un domeniu de
cercetare intensivă, proiecţie a viitorului tehnologic, o industrie comercială ce înfloreşte cu paşi
repezi, precum şi un nou mediu de exprimare a creativităţii. [5]
O definiţie formală ar fi următoarea [5]: “Realitatea augmentată combină conţinutul
grafic sau media generat pe calculator cu informaţii obţinute în timp real, prezentându-le
utilizatorului într-o formă atractivă şi interactivă.”. Se realizează astfel o întrepătrundere a
virtualului cu realul, o augmentare a acestuia din urmă, de unde şi denumirea. Realitatea
imediată, cu care utilizatorul interacţionează prin intermediul unui dispozitiv inteligent, capătă
noi dimensiuni cognitive, într-o manieră neaşteptat de prietenoasă şi intuitivă.
Platformele AR se află la intersecţia mai multor domenii tehnice, incluzând grafica
digitală, machine vision, inteligenţă artificială, sisteme de senzori, sisteme de poziţionare
geografică, servicii web, sisteme mobile etc. [5].
Precursoarea realităţii augmentate este realitatea virtuală [6], care îl introduce pe
utilizator într-o dimensiune complet artificială, din care îi este imposibil să mai perceapă lumea
reală. Spre deosebire de aceasta, AR suplimentează realitatea, nu o înlocuieşte total.
Scopul nu este doar entertainmentul sau simpla informare. Aplicaţiile ce se încadrează în
această paradigmă îşi propun să ajute utilizatorul sau un grup de utilizatori şi chiar să faciliteze
munca într-un anumit domeniu, spre exemplu cel educaţional (eLearning, lecţii interactive),
aviaţie (simulatoare avansate de zbor), medical (simulatoare de intervenţii şi practici medicale),

10
publicistic (informaţiile din cărţi/articole “prind viaţă”, interacţionând cu utilizatorul), militar
(planificatoare de strategii), arhitectură (machete virtuale) etc.
I.2 Platforme şi aplicaţii de realitate augmentată existente
Pentru ca o aplicaţie AR să funcţioneze şi să producă o experienţă vizuală deosebită, o
combinaţie de GPS, busolă, cameră foto/video şi o conexiune 3G/WiFi este mult recomandată.
Datorită existenţei unei platforme mobile puternice, precum Android, dezvoltatorilor software le
este mult mai uşor să creeze astfel de aplicaţii.
Trei dintre cele mai semnificative şi populare aplicaţii AR dezvoltate pe această
platformă sunt Layar Reality Browser, Wikitude World Browser şi Google Goggles.
I.2.1 Layar Reality Browser reuşeşte să se menţină în topul preferinţelor utilizatorilor
prin performanţele sale, în ciuda faptului că este printre primele aplicaţii de acest tip. Foloseşte o
combinaţie între camera foto, GPS şi busolă, pentru a identifica locaţia utilizatorului şi câmpul
său vizual, care este apoi îmbogăţit prin afişarea pe ecran a informaţiilor despre locaţii de interes
din apropiere. Mai nou, Layar oferă şi un API pentru programatorii care doresc să dezvolte
aplicaţii după acest model [6]. Observăm un instantaneu mai jos:
Fig 1 – instantaneu din aplicaţia Layar Reality Browser1
1 http://compixels.com/441/top-5-augmented-reality-apps-for-android

11
Plusuri şi minusuri ale acestei aplicaţii:
(+): posibilităţi de customizare a rezultatelor afişate, interactivitate, interfaţă user-friendly,
acurateţe a detectării locaţiilor, numeroase criterii de căutare a punctelor de interes şi de
“straturi” de informaţii care pot fi adăugate peste imaginile capturate de cameră;
(-): API-ul pentru dezvoltatori este limitat;
I.2.2 Wikitude World Browser este un browser ce se bazează pe conţinut Qype,
precum şi pe poziţia geografică, pentru a afişa informaţii de pe Wikipedia în limba aferentă. Se
pot căuta informaţii despre orice punct de interes din cele 350,000 din baza de date, după
coordonatele GPS sau după adresă. Rezultatele sunt afişate sub formă de listă, hartă sau în stil
AR, ca şi cum ar fi vizualizate cu camera2. Avem două instantanee mai jos:
Fig.2 – instantanee din aplicaţia Wikitude World Browser2
Plusuri şi minusuri:
(+): multiple criterii de căutare (Wikipedia, Flickr, YouTube, Booking.com) pentru POI (puncte
de interes), API cuprinzător ce facilitează crearea mashup-urilor de către dezvoltatori;
(-): multitudinea de categorii de puncte de interes poate fi derutantă iniţal, şi necesită timp
pentru a învăţa cum se interpretează rezultatele, unele feature-uri sunt încă în fază incipientă;
2 http://compixels.com/441/top-5-augmented-reality-apps-for-android

12
I.2.3 Google Goggles este contribuţia gigantului mondial la această tehnologie
inovatoare. Se bazează pe recunoaşterea imaginilor de text sau de obiecte de interes, captate cu
ajutorul camerei foto, iar apoi trimise către serverul de procesare SnapTell3. Sunt afişate apoi
rezultate relevante de pe web pentru acestea. Categoriile recunoscute sunt dintre cele mai
diverse: titluri de cărţi, nume de produse comerciale, monumente celebre, portrete ale unor
celebrităţi, coduri de bare etc. Mai jos avem un exemplu de recunoaştere de text:
Fig.3 – instantanee din aplicaţia Google Goggles4
Plusuri şi minusuri:
(+): informaţii rapide despre o gamă largă de produse, procesarea atât a unor imagini capturate
pe loc, cât şi a celor stocate anterior, interfaţă user-friendly, tutorial introductiv;
(-): acurateţea rezultatelor afişate nu este întotdeauna cea dorită, nu se pot configura anumite
setări.
I.2.4 Look! este un framework creat recent pentru dezvoltarea de aplicaţii AR, cu
numeroase facilităţi pentru localizarea geografică atât indoor, cât şi outdoor, precum şi pentru
recunoaşterea de imagini.5
3 http://www.snaptell.com/index.htm
4 http://compixels.com/441/top-5-augmented-reality-apps-for-android
5 http://www.lookar.net/en/

13
II. Recunoaşterea optică a caracterelor
O ramură nu atât de mult explorată pe telefoanele mobile, datorită complexităţii sale, este
cea de OCR (recunoaşterea optică a caracterelor). Totuşi, folosirea unui dispozitiv mobil pentru
a fotografia un anumit text de interes spre a fi procesat, este un comportament firesc, având în
vedere că este mult mai rapid decât compunerea unui şir relevant de cuvinte pentru căutarea pe
web.
În următoarele secţiuni, voi detalia aspectele teoretice legate de OCR şi reţele neuronale,
după care voi face o descriere detaliată a unei biblioteci open source axată pe acest domeniu –
Tesseract –, ce reprezintă o parte importantă a lucrării mele practice.
II.1 Definiţie şi clasificare
Recunoaşterea optică a caracterelor (Optical character recognition, abreviat OCR)
este procesul prin care un sistem inteligent extrage secvenţe de caractere − encodate în format
electronic − din imagini ale acestora, obţinute, de exemplu, prin scanare. Datorită acestei
tehnologii, avem astăzi varianta digitală a multor cărţi şi documente importante. OCR se îmbină
de multe ori cu tehnici de traducere automată, text-to-speech sau text mining, rezultând aplicaţii
complexe şi deosebit de utile.
Există mai multe categorii de software de tip OCR:
i. Desktop/Server OCR – sisteme bazate pe inteligenţa artificială analitică, luând în
considerare mai degrabă secvenţe de caractere, decât cuvinte întregi sau fraze.
După ce se face o potrivire iniţială a caracterelor, se corectează alegerile făcute
prin consultarea unei baze de date cu cuvinte.
ii. WebOCR, OnlineOCR – noul trend care să acopere cererea mare şi volumele mari
de informaţie care trebuie procesată. OnlineOCR se ocupă în special cu
recunoaşterea scrisului de mână în timp real, o provocare mai ales pentru
producătorii de tablete şi alte dispozitive mobile cu stiletto.

14
iii. OCR orientat-aplicaţie – destinat să rezolve probleme frecvente în anumite
aplicaţii, referitoare la calitatea imaginilor ce trebuie procesate: fundaluri
complicate, granularitate mare, hârtie îndoită, rezoluţie joasă, linii trasate,
simboluri neobişnuite etc. Deoarece se concentrează doar pe anumite aspecte, se
mai numeşte şi “Customized OCR”. Exemple: Business-card OCR, Invoice OCR,
Screenshot OCR, ID card OCR, Driver-license OCR etc.
Pentru a-şi îmbunătăţi rata de succes, în special aplicaţiile web care oferă servicii OCR
apelează de multe ori la sistemul reCAPTCHA6, patronat de Google. Astfel, anumite site-uri
abonate primesc imagini ale unor cuvinte ce nu au putut fi procesate corect în maniera OCR.
Acestea sunt apoi oferite utilizatorilor ca imagini CAPTCHA, în procesul obişnuit de
autentificare, înregistrare etc. Rezultatele sunt apoi returnate serviciului reCAPTCHA, care le
returnează, la rândul lui, aplicaţiei OCR. Aceasta deoarece utilizatorii umani sunt cei care pot
recunoaşte cel mai uşor greşelile şi, astfel, ajusta tehnicile curente de recunoaştere a caracterelor.
II.2 OCR cu reţele neuronale
Una dintre cele mai populare astfel de tehnici este folosirea reţelelor neuronale
artificiale multistratificate, folosind algoritmul de retropropagare, concepte care vor fi
detaliate în următoarea secţiune.
După cum vom vedea, una dintre problemele principale este cum codificăm entităţile
concrete iniţiale într-o secvenţă de numere reale, ce va fi dată ca input reţelei. În cazul nostru,
lucrând cu imagini, putem avea mai multe abordări.
Etapa de antrenare a reţelei presupune introducerea unor imagini ale fiecărui caracter,
sub formă de matrice de pixeli. Valoarea fiecărui element din matrice va fi dată de
luminozitatea fiecărui pixel, scalată pentru a se încadra într-un anumit interval impus de
constrângerile reţelei (-0.5 - 0.5, sau -1 - 1). Un exemplu concludent:
6 http://www.google.com/recaptcha

15
Fig.4 – exemplu de matrice bazată pe luminozitatea pixelilor din imaginea digitală a unui caracter7
Etapa de clasificare propriu-zisă presupune, printre altele, trecerea în sistemul alb-negru
a imaginii şi apoi împărţirea ei în imagini de un singur caracter. Aceşti paşi sunt realizaţi de
obicei de către o librărie de procesare a imaginilor, nu de către motorul propriu-zis de OCR.
Apoi, aceste caractere sunt propagate în reţea pentru recunoaştere.
De obicei, pentru o rată de succes mare, este necesar a se cunoaşte limba în care este
textul şi o bază de date de cuvinte a sa, pentru a se corecta rezultatele obţinute.
În prezent, recunoaşterea caracterelor latine nu are o acurateţe de 100% nici măcar în
cazul imaginilor clare. Rata de succes pentru majoritatea softurilor comerciale variază de la 71%
la 98%, potrivit unor statistici [4]. Pentru atingerea maximului, este întotdeauna nevoie de
feedback uman.
În ceea ce priveşte bibliotecile OCR open-source, cea mai performantă s-a dovedit a fi
Tesseract, care aparţine acum de Google şi va fi detaliată într-o secţiune următoare.
7 http://www.codeproject.com/KB/dotnet/simple_ocr.aspx

16
II.3 Reţele neuronale artificiale
II.3.1 Structură şi comportament
După cum le spune şi numele, reţelele neuronale artificiale (Artificial Neural Networks,
abreviat ANN) sunt reprezentări ale unor scheme de învăţare supervizată din inteligenţa
artificială, construite după modelul creierului biologic. Acesta este privit ca o reţea complexă
alcătuită din unităţi mici interconectate – neuronii –, care comunică prin semnale, rezultând
raţionamente inteligente [2].
La un nivel mai abstract, un neuron poate fi privit ca o funcţie care, la primirea unor
parametri de intrare, va efectua calcule şi va transmite semnal mai departe sau nu. Aceşti
parametri pot fi din exterior (de la simţuri) sau pot proveni de la alţi neuroni şi se pot raporta la
un prag, care, dacă este depăşit, va determina propagarea semnalului.
ANN-urile simulează acest comportament, bineînţeles, într-un mod mai grosier. Astfel,
ele constau într-un număr de unităţi (noduri) care primesc ca parametri de intrare (input)
numere reale şi produc o singură valoare reală, ca parametru de ieşire (output). Nodurile sunt
legate între ele prin arce, ce au o anumită pondere (cost) care va fi luată în calculul ieşirii.
Inputul unui nod poate veni fie din exteriorul reţelei, fie de la un alt nod din reţea, iar outputul
poate merge în afara reţelei sau poate intra în alt nod.
Ca metodă de învăţare supervizată, utilizarea ANN-urilor presupune 2 etape. Prima este
cea de antrenare, când avem o serie de exemple (instanţe) şi categoria corespunzătoare
fiecăruia, stabilită a priori şi vrem ca reţeaua să deducă logica după care s-au făcut asocierile
respective, pentru a putea apoi să clasifice corect orice nouă instanţă. Această etapă se bazează
pe ajustarea costului fiecărui arc, după cum vom vedea în cele ce urmează.
Cea de-a doua etapă este cea de clasificare (categorisire) propriu-zisă, când, odată
antrenată reţeaua, i se dă o instanţă nouă şi trebuie să decidă în care categorie se încadrează cel
mai bine.

17
Topologia unei ANN arată, schematizat, astfel [1]:
o O mulţime de unităţi de intrare (input units), care primesc din exterior datele (pattern-
urile) ce trebuie să fie propagate în reţea, pentru învăţare sau categorisire şi le afişează
sub formă de valori numerice. Acestea formează stratul de intrare (input layer).
o O mulţime de unităţi ascunse (hidden units), care îşi iau inputul din suma ponderată a
output-urilor unităţilor din stratul de intrare costul pe fiecare arc de la unitate şi
produc propriul output pe baza unei funcţii unice pe toată reţeaua, numită funcţie prag.
Este denumită astfel, deoarece este setată să producă valori mici dacă suma ponderată nu
depăşeşte un anumit prag şi valori mai mari, dacă îl depăşeşte. Cum în general, sunt mai
multe unităţi de intrare care “converg” într-o singură unitate ascunsă, rezultă că numărul
acestora din urmă este, de obicei, mai mic. Ele formează stratul ascuns (hidden layer).
o O mulţime de unităţi de ieşire (output units), care, în procesul de învăţare, dictează
categoria în care se încadrează cel mai bine exemplul propagat în reţea. Ele îşi iau
intrarea analog ca mai sus, dintr-un strat ascuns, iar ieşirea lor este calculată de funcţia
prag decisă mai sus. Împreună formează stratul de ieşire (output layer).
O imagine a unei ANN generale:
Fig.5 – model general de reţea neuronală
artificială de tip feed forward, cu un singur strat ascuns [1]

18
Trebuie menţionate următoarele lucruri:
o toate arcele au costuri asociate (chiar dacă nu au mai fost incluse pentru a nu încărca
imaginea);
o mai multe straturi ascunse sunt posibile, intrarea unuia provenind din ieşirea celuilalt de
dinaintea sa.
o există şi ANN-uri fără straturi ascunse, numite perceptroni, care au aplicaţii limitate, dar
vor fi analizate mai jos pentru a facilita trecerea către cele mai complexe.
II.3.2 Clasificare
Există două tipuri de reţele neuronale: reţele cu flux unidirecţional şi reţele recurente [2].
O reţea cu flux unidirecţional (feed forward network) este, practic, un graf orientat aciclic
în care semnalele merg în aceeaşi direcţie tot timpul. Reţelele de acest tip sunt de obicei
multistratificate, adică nodurile îşi primesc inputul doar de la straturi precedente şi transmit
outputul doar la straturi ulterioare din structura reţelei. Un exemplu de astfel de reţea este exact
cea ilustrată în Fig.1 de mai sus.
Reţelele recurente permit cicluri, ceea ce măreşte numărul şi complexitatea problemelor
ce pot fi reprezentate, dar în acelaşi timp face mai dificilă analiza şi evaluarea reţelei.
După cum am menţionat mai sus, problema învăţării într-o reţea neuronală se bazează
esenţialmente pe asignarea corectă a costurilor pe fiecare arc. Aşadar, sunt 2 decizii importante
care trebuie luate înaintea antrenării:
i. Arhitectura reţelei – cum mapăm datele iniţiale în nodurile de intrare, câte straturi
ascunse să avem şi cum ne folosim de outputul nodurilor de ieşire pentru a trage
concluziile de care avem nevoie.
ii. Funcţia prag de calcul a outputului unui nod din inputul primit.

19
Prima problemă se rezolvă experimentând diferite arhitecturi, până când ceea ce obţinem
este mai aproape de rezultatul dorit. Răspunsul la cea de-a doua îl vom oferi studiind două tipuri
principale de ANN-uri: perceptroni şi reţele multistratificate.
II.3.3 Perceptroni
Perceptronii sunt ANN-uri fără straturi ascunse si cu un singur nod în stratul de ieşire,
spre care converg toate nodurile de intrare. Astfel, problema arhitecturii se reduce doar la a găsi
o formă convenabilă şi relevantă de a transforma exemplele şi pattern-urile iniţale de antrenare
sau categorisire, în numere reale, pe care să le afişăm în nodurile de intrare.
Pentru perceptroni, se folosesc funcţii prag simple ca definiţie, de exemplu una care
produce 1, dacă suma ponderată a inputurilor este mai mare decât un anumit prag şi -1, altfel.
Vom lua un exemplu concret pentru a clarifica lucrurile.
Exemplu:
[1]Se consideră o ANN antrenată să clasifice o imagine de 2x2 pixeli albi sau negri,
astfel: dacă are 3 sau 4 pixeli negri, este întunecată; altfel, este luminoasă. Putem modela aceasta
printr-un perceptron cu 4 unităţi de intrare, câte una pentru fiecare pixel, afişând 1 dacă pixelul e
alb şi -1 dacă este negru. Dacă alegem costurile ca în imaginea următoare, perceptronul va
categorisi corect orice imagine care respectă regulile noastre, lucru care poate fi verificat cu
uşurinţă.
Fig.6 – model de perceptron care clasifică o imagine de 2x2 pixeli albi sau negri [1]

20
De notat că, în general, costurile pe arce nu sunt aceleaşi şi că valorile lor se iau cel mult
egale cu 1. S-a ales o valoare a pragului cât mai mică, dar aceasta nu era singura opţiune.
Pentru ca un perceptron să îndeplinească sarcina de categorisire cu succes, trebuie folosit,
după cum am mai menţionat, un set de instanţe de antrenament pentru a stabili costurile pe
fiecare arc şi pragul pentru funcţia aferentă.
Pentru simplificare, în cazul perceptronului, putem considera pragul ca fiind un cost
special, ataşat unei muchii ce provine de la un nod de intrare cu ieşirea mereu 1, ca în imaginea
de mai jos:
Fig.7 – model de perceptron care trebuie antrenat pe costurile muchiilor şi pe prag [1]

21
II.3.3.1 Descrierea algoritmului de antrenare a perceptronilor [1]
1) Iniţial, costurile sunt asignate aleatoriu;
2) Instanţele de antrenament sunt folosite una după alta pentru a ajusta costurile pe fiecare
muchie, operaţie cunoscută sub numele de regula de antrenare a perceptronilor
(perceptron training rule):
2.1) Dacă exemplu curent, E, este categorisit greşit, atunci fiecare cost , pornind din
nodul de intrare cu ieşirea , va suferi transformarea
unde se calculează cu formula:
( ( ) ( ))
unde:
( ) – valoarea care ar fi trebuit să rezulte pentru exemplul E;
( ) – valoarea care a rezultat de fapt;
o constantă pozitivă numită rată de învăţare (learning rate), care
controlează cât de departe poate merge ajustarea costurilor într-un pas. Se ia
de obicei o valoare foarte mică, de exemplu 0.1.
3) Pasul 2) se repetă până când toate instanţele de antrenament sunt categorisite corect. Aceasta
se întâmplă atunci când categoria decisă de reţea, adică cea care are outputul cel mai mare,
coincide cu cea cunoscută a priori.
Ajustarea costurilor are ca obiectiv găsirea unei erori globale minime, calculată în
funcţie de proporţia de exemple categorisite greşit. Astfel, constanta este responsabilă cu
fineţea corecturii costurilor, pentru ca îmbunătăţirea valorii unuia să nu fie în detrimentul sumei
ponderate totale. Dacă un cost chiar necesită o ajustare mare, atunci acest lucru se va produce
iterând de mai multe ori prin setul de instanţe de antrenament şi nu deodată. Dorim să evităm pe
cât posibil intrarea într-un minim local, din care ne va fi mai greu să ieşim, pentru a atinge
minimul global.

22
II.3.3.2 Aplicaţiile perceptronilor
După cum s-a arătat în lucrarea [3], perceptronii pot fi folosiţi atunci când funcţia de
categorisire este liniar separabilă. Aşadar, scopul funcţiei este apropiat de cel al funcţiilor
booleene, iar graficul său permite trasarea unei linii (sau un plan, dacă gândim în spaţiu) care să
delimiteze clar, de o parte şi de alta, valorile posibile. De aici şi aplicabilitatea redusă a
perceptronilor în forma lor clasică.
Ca exemplu, vom lua chiar funcţiile booleene AND, OR şi XOR, care pot afişa valorile 1
şi -1 (în loc de 0) după regulile cunoscute:
AND( ) = 1 ⇔ , altfel -1
OR( ) = 1 ⇔ , altfel -1
XOR( ) = 1 ⇔ , altfel -1
Funcţiile AND şi OR sunt liniar separabile şi deci pot fi modelate cu ajutorul
perceptronilor, dar funcţia XOR nu este liniar separabilă şi deci nu poate fi reprezentată prin
acest tip de ANN. Următoarele figuri lămuresc aceste concepte:
Fig.8 – funcţiile booleene AND şi OR modelate prin perceptroni [1]

23
Fig.9 – graficele funcţiilor booleene care demonstrează dacă sunt sau nu liniar separabile [1]
II.3.4 Reţele neuronale multistratificate
După cum le spune şi numele, sunt ANN-uri care au cel puţin un strat ascuns şi pot fi
folosite pentru a modela o sumedenie de concepte şi funcţii, spre deosebire de perceptroni.
O altă diferenţă majoră este dată de funcţia prag, care este de această dată diferenţiabilă.
Funcţiile prag de la perceptroni nu sunt continue, deci nici diferenţiabile.
O funcţie care este folosită foarte des în acest scop este funcţia sigma, definită astfel:
( )
,
unde S este suma ponderată primită ca input, iar e este baza logaritmilor naturali, egală cu
2.718...
Un exemplu de ANN multistratificată este următoarea:
Fig.10 – exemplu de reţea neuronală multistratificată, ce foloseşte funcţia sigma ca funcţie prag [1]
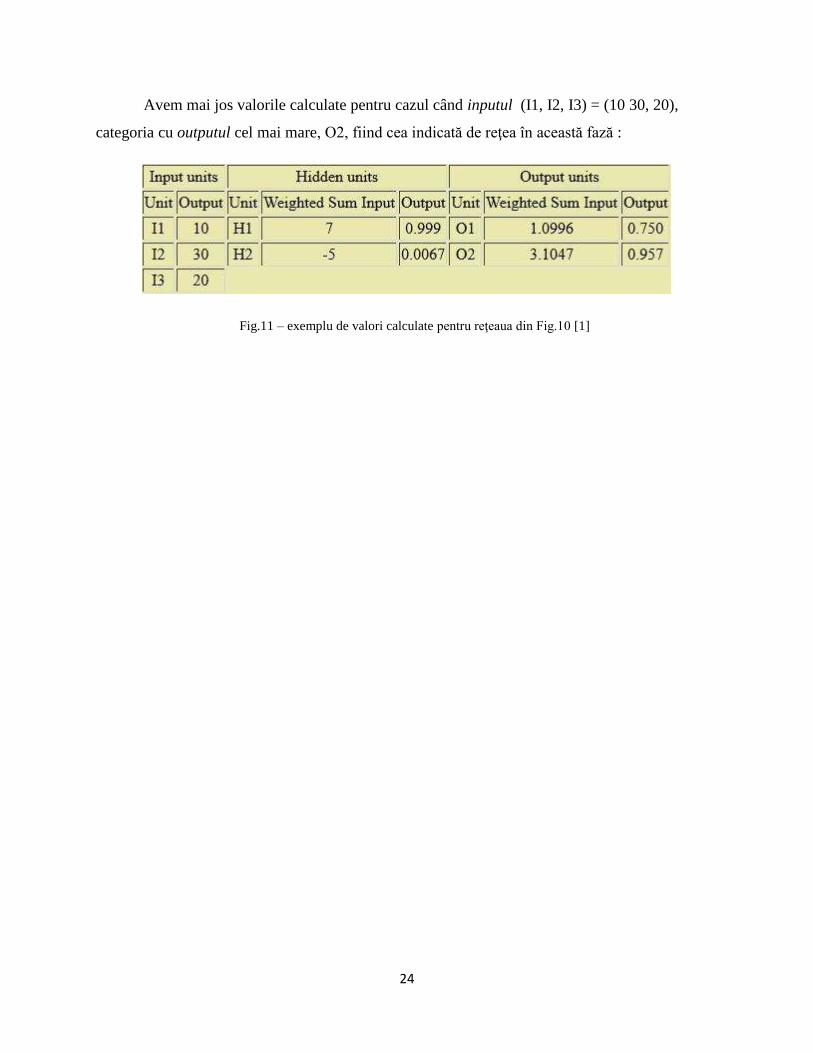
24
Avem mai jos valorile calculate pentru cazul când inputul (I1, I2, I3) = (10 30, 20),
categoria cu outputul cel mai mare, O2, fiind cea indicată de reţea în această fază :
Fig.11 – exemplu de valori calculate pentru reţeaua din Fig.10 [1]

25
II.3.4.1 Rutina de retropropagare (backpropagation) [1]
1) Ne modelăm arhitectura reţelei, care va conţine atât noduri de intrare şi ieşire, cât şi noduri
ascunse, toate calculându-şi ieşirea prin funcţia sigma. Trebuie avut în vedere că, dacă
numărul de noduri interne este prea mare comparativ cu numărul instanţelor de antrenament,
algoritmul nu va generaliza suficient reţeaua, iar dacă numărul de noduri interne este prea
mic, reţeaua poate eşua în găsirea unei configuraţii compatibile cu setul de instanţe de
antrenament [2];
2) Iniţial, costurile sunt asignate aleatoriu, cu valori între -0.5 şi 0.5;
3) Instanţele de antrenament sunt folosite una după alta pentru a ajusta costurile pe fiecare
muchie (costuri notate cu , indicând arcul de la nodul i la nodul j) . Dacă un exemplu E
este încadrat în categoria greşită, atunci se urmează următorii paşi:
3.1) Se calculează valorile aşteptate, (E), pe care fiecare unitate de ieşire ar trebui să
o producă pentru E (1 pentru categoria corectă şi 0 pentru celelalte), valorile
efective rezultate la pasul curent pentru acestea, (E), precum şi valorile
rezultate pentru nodurile ascunse, (E);
3.2) Pentru fiecare nod k de ieşire, se calculează eroarea specifică (error term):
( )( ( ))( ( ) ( )).
3.3) Cu ajutorul acestora, se calculează erorile specifice pentru nodurile ascunse (de
aici şi termenul de retropropagare):
( )( ( )) ∑
3.4) Având calculate aceste valori ale erorilor asociate cu fiecare nod (ascuns sau de
ieşire), putem calcula , care se va aduna la ; pentru costurile arcelor dintre
un nod de intrare şi un nod ascuns :
,

26
iar pentru costurile arcelor dintre un nod ascuns şi un nod de ieşire :
( )
4) După fiecare repetare a pasului 3), o condiţie de terminare a algoritmului este
verificată. Aceasta deoarece, pentru această metodă, nu este garantată găsirea unor
costuri care să nu ducă la absolut nicio categorisire greşită a instanţelor de
antrenament. Aşadar, o posibilă condiţie de terminare (dar nu întotdeauna eficientă)
ar fi un număr limită (de obicei mic) de exemple clasificate greşit.

27
II.3.5 Concluzii: aplicabilitatea reţelelor neuronale artificiale
Când şi pentru ce sarcini putem folosi ANN-urile în practică?
1) Atunci când conceptul care trebuie învăţat poate fi “codificat“ de o funcţie cu valori
reale, ceea ce înseamnă că atât inputul, cât şi outputul pot fi mapate la un set de
numere reale;
2) Dacă perioada de antrenare poate fi oricât de lungă (de la câteva minute la câteva
ore). Mulţi factori, printre care numărul instanţelor de antrenament, valoarea aleasă
pentru rata de învăţare, arhitectura reţelei, influenţează drastic timpul de învăţare;
3) Atunci când nu este important pentru utilizatori să înţeleagă exact calculele după care
funcţionează reţeaua. Metoda utilizării ANN-urilor este de tip black box: observăm
rezultatele, dar nu putem privi “înăuntru”, ne este greu să analizăm mecanismele
interne;
4) Când, odată antrenată reţeaua, sarcina de categorisire trebuie să decurgă rapid;
5) Pentru probleme care nu au un algoritm general de rezolvare, sau ar fi prea complex
de construit unul.
Aplicaţii concrete care folosesc ANN-uri:
- recunoaşterea caracterelor;
- recunoaşterea vorbirii;
- recunoaşterea semnalelor;
- predicţia funcţională,;
- modelarea sistemelor.

28
II.4 Tesseract
II.4.1 Scurt istoric
Dezvoltarea acestui motor OCR open-source a fost iniţial suţinută de către compania
Hewlett- Packard, între anii 1984-1994, figurând în top 3, conform UNLV Annual Test of OCR
Accuracy din 1995. Ulterior, până în 2006, a intrat într-un con de umbră, până când a fost
preluat de către Google, de care aparţine până astăzi. Progresele aduse de atunci au fost
semnificative, poate şi datorită faptului că, devenind open-source, şi-au putut aduce contribuţia şi
sugestiile numeroşi dezvoltatori.
Proiectul include şi o bibliotecă de procesare a imaginilor – Leptonica8 – şi poate în
prezent recunoaşte caractere din peste 40 de limbi, din varii formate de imagini (*.jpg, *.bmp,
*.tiff, *.png etc.).
Tesseract nu poate fi folosit însă ca un produs comercial şi nici măcar ca unul de sine
stătător, deoarece, pe lângă lipsa unei interfeţe grafice, nu conţine funcţii pentru analiza avansată
a layout-ului paginilor sau pentru formatarea textului recunoscut, ca alte produse comerciale, gen
OmniPage9. Acest neajuns are la bază perioada dezvoltării în laboratoarele HP, care aveau deja
unelte independente orientate înspre asemenea sarcini şi care nu sunt open-source. Ele puteau fi
aşadar îmbinate şi Tesseract nu avea motive să conţină propriile astfel de mecanisme. Google nu
a preluat ulterior şi aceste unelte, ele rămânând sub proprietatea HP-ului. Aşadar Tesseract poate
fi folosit în prezent doar ca o bibliotecă inclusă în cadrul unui proiect, focalizată pe recunoaşterea
caracterelor, sarcina de procesare a imaginii date în diferite formate, revenind bibliotecii
Leptonica. Afişarea, eventual formatarea rezultatului, devine sarcina programatorului.
Ultima versiune10
, 3.02, lansată în februarie 2012, are îmbunătăţiri în ceea ce priveşte
detecţia diacriticelor, a alineatelor, a tab-urilor, precum şi funcţii noi, precum:
- detecţia caracterelor din limbi a căror direcţie de scriere este de la dreapta la stânga (ex.
limbile arabice);
8 http://www.leptonica.com/
9 http://www.nuance.com/for-business/by-product/omnipage/index.htm
10 http://tesseract-ocr.googlecode.com/svn/trunk/ReleaseNotes

29
- recunoaşterea caracterelor din mai multe limbi prezente în acelaşi document;
- detecţia paragrafelor;
- un detector de ecuaţii experimental.
II.4.2 Arhitectură şi flux de lucru
Precum am menţionat anterior, Tesseract presupune că inputul este o imagine binară (un
bitmap), eventual cu regiuni poligonale de text definite (asemănătoare paragrafelor). Arhitectura
generală este de tip pipeline, cu unele elemente de inovaţie. Vom detalia în subsecţiunile de mai
jos fiecare pas, incluzând algoritmii şi unele formule folosite [7].
II.4.2.1 Gruparea biţilor imaginii în Blob-uri
Primul pas, care a părut o decizie costisitoare în termeni de eficienţă la momentul
respectiv, constă în analizarea felului în care componentele imaginii sunt conectate între ele, în
termeni de contururi (outlines) imbricate. Aceste rezultate sunt stocate în structuri numite
Blobs (Binary Large Objects). Ele reprezintă o colecţie de biţi stocaţi ca o singură entitate.
Printre avantajele acestei abordări, de a detecta practic “copiii” şi “nepoţii” unui contur,
se numără detecţia cu uşurinţă a textului alb pe fundal negru, invers faţă de normal.
II.4.2.2 Alcătuirea liniilor de text
Al doilea pas presupune gruparea blob-urilor în linii de text. Algoritmul funcţionează şi
pe text deformat oblic (skewed) (Fig. 12), fără a fi nevoie de “îndreptare”, operaţie care ar dăuna
calităţii imaginii.
Fig.12 – exemplu de text deformat oblic (skewed)11
11
http://www.yearbooks.biz/?event=FAQ.Detail&faq=12

30
Presupunând că etapa de analiză a layout-ului paginii dă Tesseract-ului ca parametri de
intrare regiuni de text aproximativ uniform ca dimensiune, pentru a elimina situaţii precum drop
caps (Fig. 13) sau caractere care se intersectează vertical, se aplică un filtru percentilă pentru
înălţime (percentile height filter).
Fig.13- exemplu de drop caps12
Definiţia percentilei13
: o valoare din setul de date, asociată cu un număr de ordine (rank)
în secvenţă crescătoare, ce ne spune ce procent din date se găseşte sub valoarea respectivă. Spre
exemplu, a 20-a percentilă e valoarea sub care se găsesc 20% din observaţii. Cea de-a 25-a
percentilă se întâlneşte frecvent sub termenul de prima quartilă, iar a 50-a percentilă, sub
termenul de mediană sau a doua quartilă.
Mediana înălţimii aproximează dimensiunea textului din acea regiune şi astfel, pot fi
filtrate blob-urile care sunt mai mici decât o anumită fracţiune din această mediană,
considerându-le semne de punctuaţie, diacritice sau noise.
Blob-urile filtrate sunt apoi mai uşor de încadrat într-o grilă de linii paralele,
nesuprapuse, dar înclinate. Pentru aceasta, mai întâi se sortează după abscisă, astfel putând
asigna blob-urile la o unică linie, chiar şi la o pantă a textului mai mare (acel skew de care
menţionam anterior).
Ulterior, liniile de bază (baseline-urile) sunt aproximate prin calculul celei mai mici
mediane a pătratelor (least median of squares sau LMS, descrisă pe larg în [9]. Se bazează în
principiu pe minimizarea medianei pătratelor erorilor reziduale, rezultate în urma aproximării
unor coeficienţi de ecuaţii liniare). Ca idee, baseline-urile se presupune că sunt partiţiile cele mai
populate de biţi.
12
http://safalra.com/web-design/typography/css-drop-caps/ 13
http://www.regentsprep.org/regents/math/algebra/AD6/quartiles.htm

31
Blob-urile care au fost filtrate în urma aplicării medianei înălţimii sunt apoi încadrate în
aceste linii. Cele care se suprapun pe orizontală măcar până la jumătate sunt grupate cu baza
corectă de care aparţin, cum e în cazul diacriticelor sau a unor caractere fragmentate.
Mai jos avem o figură care menţionează denumirile standard din tipografie ale anumitor
linii de încadrare a cuvintelor, termeni pe care îi vom folosi în cele ce urmează.
Fig.14 – denumirile liniilor de încadrare a cuvintelor în tipografie14
II.4.2.3 Alcătuirea baseline-urilor
Odată ce au fost găsite liniile de text, baseline-urile, precum şi celelalte linii importante
ilustrate în Fig. 14, sunt aproximate mai precis prin aplicarea unor funcţii spline pătratice asupra
lor. Iniţial, liniile au fost oblice. Acum sunt curbate, un element de inovaţie pe care îl aduce
Tesseract în rândul motoarelor OCR.
Fig.15 – liniile importante din fig. 14 sunt cele colorate, uşor curbate de această dată [7]
Prin inspecţia atentă a figurii de mai sus, observăm că toate liniile sunt “paralele” şi uşor
curbate. Se observă că ascender line, cea cyan (la printare, gri deschis), este curbată în raport cu
linia neagră dreaptă de sus.
14
http://en.wikipedia.org/wiki/File:Typography_Line_Terms.svg

32
II.4.2.4 Separarea în cuvinte
Această etapă se bazează foarte mult pe distanţa dintre caractere. Tesseract parcurge
fiecare linie de text găsită pentru a testa dacă fontul folosit ocupă acelaşi spaţiu orizontal pentru
fiecare caracter (fixed-pitch font sau monospaced font, cum este fontul Courier, de exemplu).
Dacă da, atunci împarte linia direct în caractere, cuvintele putând fi refăcute uşor de aici
(deoarece şi spaţiul ocupă aceeaşi lăţime). Nu se mai aplică segmentatorul (chopper) şi
asociatorul de la pasul următor, de recunoaştere a cuvintelor.
Fig.16 – exemplu de cuvânt cu caractere fixed-pitch [7]
Dacă însă fontul nu respectă regula de mai sus (proportional font), sarcina de împărţire
în cuvinte este mult mai grea. Figura de mai jos ilustrează nişte probleme tipice în acest sens.
Fig.17 – exemplu de text greu de împărţit în cuvinte [7]
Spre exemplu, nu există deloc spaţiu orizontal între chenarele (bounding boxes) care
încadrează “of” şi “financial”, iar spaţiul dintre “erated” şi “junk” este mai mic decât normal.
Tesseract rezolvă unele (dar nu toate) din aceste probleme măsurând golurile (gaps)
dintr-un anumit interval dintre linia de bază si linia mediană (mean line). Valorile apropiate de
prag devin fuzzy şi o decizie finală va fi făcută după etapa de recunoaştere a cuvintelor.

33
II.4.2.5 Segmentarea maximală a cuvintelor în caractere
Outputul segmentării de la etapa anterioară este dat clasificatorului. Dacă am avut de-a
face cu font non-fixed-pitch, rezultatele nu vor fi satisfăcătoare, cel mai probabil şi atunci se
aplică etape suplimentare de segmentare.
Altfel, în special în cazul în care sunt caractere unite care nu au putut fi separate prin
metoda măsurării golurilor, se încearcă segmentarea blob-ului în vârfurile concave din
aproximarea poligonală a conturului (fig. 18). Fiecare asemenea vârf are fie un alt vârf concav
opus sau un segment de linie. Primul caz are prioritate la segmentare. Spre exemplu, în imaginea
de mai jos, demarcarea va avea loc în punctele unde “r” se uneşte cu “m”.
Fig.18 – puncte concave din contur (outline) pentru segmentarea caracterelor unite [7]
Fiecare segmentare, chiar dacă nu îmbunătăţeşte rezultatul clasificării, este păstrată
pentru a fi utilizată ulterior de către asociator.
Dacă după ce s-au epuizat toate posibilităţile de segmentare, cuvântul tot nu este
recunoscut cu succes, se pasează unui asociator. Acesta aplică algoritmul A* (best first) de
căutare printre posibile combinaţii între elementele segmentate maximal, care nu au fost
clasificate anterior. În figura de mai jos este prezentat un exemplu în care această strategie se
dovedeşte utilă:

34
Fig.19 – combinaţii cu succes între blob-uri segmentate maximal [7]
II.4.2.6 Clasificatorul de caractere
Versiunile anterioare de Tesseract foloseau pentru recunoaşterea caracterelor şi a
cuvintelor, segmentele din aproximarea lor poligonală. Această abordare, luată însă ca atare, nu
s-a dovedit robustă în cazul caracterelor fragmentate, după cum se poate vedea în imaginea de
mai jos:
Fig.20 – a) aproximarea poligonală a caracterului “h” normal (prima imagine), care diferă de b)
aproximarea poligonală a caracterului “h” în cazul fragmentării;
c) trăsături suprapuse prototipurilor.
Soluţia constă nu în comparaţia directă dintre trăsăturile caracterului de identificat şi
prototipurile din setul de antrenare, ci în computarea unei distanţe între acestea, care sa fie cât
mai mică. Pentru a se realiza acest lucru, prototipurile din etapa de antrenare sunt laturi ale
poligonului ce aproximează caracterul, pe când trăsăturile extrase în etapa de recunoaştere sunt

35
segmente unitate (normalizate). Acestea sunt confruntate many-to-one cu trăsăturile clusterizate
ale prototipurilor.
După cum se observă în fig. 20c), liniile scurte şi groase reprezintă trăsăturile caracterului
dat spre identificare, iar segmentele subţiri de dedesubt, pe cele ale prototipului (litera “h”). Cele
mai multe se potrivesc, aşadar distanţa care va fi computată va fi mică. Singurul dezavantaj este
costul calculării acestei distanţe, care este destul de mare.
Se încearcă recunoaşterea, pe rând, a fiecărui cuvânt, folosind un clasificator static (care
se bazează pe reţele neuronale, dar şi pe clusterizare). Fiecare cuvânt care este identificat cu o
rată de succes satisfăcătoare, este pasat clasificatorului adaptiv ca instanţă de antrenament. Pe
baza acestui input, el are ocazia să clasifice mai bine cuvintele care vor fi date ulterior spre
clasificare.
Întrucât clasificatorul adaptiv e posibil să fi “învăţat” ceva util prea târziu pentru a putea
aduce o contribuţie notabilă în cazul caracterelor aflate mai înainte în pagină, imaginea este
parcursă încă o dată, pentru a se încerca o a doua recunoaştere a cuvintelor care nu au putut fi
identificate în prima etapă.
Faza finală rezolvă datele fuzzy şi verifică ipoteze alternative pentru x-height (Fig. 15),
pentru a localiza “majusculele mici” (small caps):
Fig.21 – exemplu de “majuscule mici” (small caps)15
II.4.2.7 Analiza lingvistică
Fiecare propunere de cuvânt rezultată în urma modulului de recunoaştere de cuvinte,
după clasificarea caracterelor, este confruntat cu o listă de cuvinte din mai multe categorii:
15
http://en.wikipedia.org/wiki/File:True_vs_Scaled_Small_Caps.svg

36
- cel mai frecvent cuvânt;
- cuvânt de dicţionar;
- cuvânt numeric;
- cuvânt UPPER case;
- cuvânt lower case;
- cuvânt lower case cu majusculă la început;
- cuvântul ales de cele mai multe ori de către clasificator.
Din fiecare categorie, se alege cea mai bună variantă şi se adaugă într-o listă scurtă de
opţiuni, iar varianta finală este dată de distanţa cea mai mică dintre cuvântul recunoscut şi
cuvintele selectate. Ponderea fiecăreia din categoriile de mai sus este o constantă diferită de
celelalte.
Toate aceste categorii, în afară de ultima, presupun să se cunoască limba în care este
textul şi să fie furnizate seturi de date antrenate pentru fiecare limbă în parte. Rezultatul
antrenării, care va fi pasat clasificatorului, trebuie dat într-un fişier inclus în proiect, cu extensia
.traineddata. Pe Google Repository-ul proiectului, sunt date indicaţii despre cum se poate realiza
această antrenare folosind uneltele puse la dispoziţie de ei16
. Se detaliază şi ce structură ar trebui
să aibă fişierele efective cu trăsăturile fiecărui set de caractere, a punctuaţiei specifice, un
dicţionar de cuvinte şi multe altele. Există momentan asemenea fişiere pentru cel puţin 40 de
limbi şi dialecte, disponibile pentru descărcare, în secţiunea http://code.google.com/p/tesseract-
ocr/downloads/list.
16
http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3 – pentru antrenarea caracterelor pentru versiuni de Tesseract 3.0x

37
II.4.3 Concluzii
Tesseract este la ora actuală cel mai performant motor OCR open-source, însă are o rată
de succes sub majoritatea produselor comerciale, poate şi datorită perioadei de latenţă dintre anii
1995-2006.
Punctul său forte este dat de comparaţia dintre trăsăturile caracterului ce se cere a fi
recunoscut şi prototipul antrenat, bazată pe calculul unei distanţe şi nu pe teste triviale de
egalitate. Alte plusuri ar fi:
(+) folosirea baseline-urilor curbate, sporind acurateţea detectării liniilor;
(+) faptul că poate detecta cu uşurinţă text alb pe negru;
(+) faptul că funcţionează pe text înclinat (skewed);
(+) faptul că recunoaşte cu uşurintă caracterele fragmentate;
(+) faptul că foloseşte atât un clasificator static, cât şi unul adaptiv.
Principalele minusuri şi îmbunătăţiri care ar putea fi aduse:
(-) ineficienţa dată de strategia segmentare-asociere, precum şi posibilitatea de a pierde anumite
segmente importante astfel;
(-) folosirea funcţiilor spline pătratice în loc de spline cubice [10], pentru aproximarea baseline-
urilor;
(-) calculul distanţei dintre caracterul ce se cere a fi recunoscut şi prototip este costisitor; o
îmbunătăţire ar fi schimbarea inputului către clasificator din aproximarea poligonală a
caracterului, în conturul său efectiv, brut, ca secvenţă de pixeli [7];
(-) lipsa unui model de n-grame bazat pe modele Markov ascunse (Hidden Markov Models)
pentru a recunoaşte mai bine secvenţe de caractere grupate, care, individual, creează ambiguităţi.
Spre exemplu [11], dacă "I" nu poate fi recunoscut fără ambiguităţi, deoarece "l" poate avea
aceeaşi formă în unele fonturi, combinaţia “It" poate fi mult mai probabilă decât “lt”.

38
Tesseract este implementat în C++, dar datorită numărului mare de cereri şi a utilităţii
crescute, au fost create wrappere în diferite limbaje de programare. O listă completă a acestora,
precum şi diferite AddOn-uri şi proiecte open-source bazate pe acest motor OCR, se găsesc la
adresa http://code.google.com/p/tesseract-ocr/wiki/AddOns. Voi detalia în secţiunea dedicată
descrierii aplicaţiei cum am realizat eu concret integrarea.

39
III. Recunoaşterea entităţilor textuale de tip nume
III.1 Introducere în domeniul Extragerii de Informaţii
Procesul de recunoaştere a entitӑţilor textuale de tip nume, mai cunoscut sub termenul de
Named Entity Recognition (NER), este o sarcină din categoria de Extragere de Informaţii
(Information Extraction). Aceasta se ocupӑ cu selectarea, structurarea şi combinarea unor date
explicite sau implicite din diferite texte, care sunt apoi folosite în scopuri precise. [20] Printre
acestea se numӑrӑ:
- realizarea de statistici;
- detectarea sentimentelor;
- detectarea relaţiilor dintre persoane;
- reconstituirea unor situaţii;
- ordonarea cronologicӑ a unor evenimente;
- clasificarea domeniului de care aparţine textul etc.
Datoritӑ dificultӑţii crescute, s-au dezvoltat tehnici focalizate pe texte aparţinând unui
anumit domeniu precis (ştiinţific, militar, publicistic, juridic etc). Odatӑ generalizate, acestea nu
mai dau rezultate la fel de bune.
Începând din anul 1987, au fost organizate competiţiile din seria MUC (Message
Understanding Conferences), pentru a încuraja dezvoltarea de metode inovative şi eficiente în
acest vast domeniu al extragerii de informaţii. Evaluarea şi compararea rezultatelor au presupus
stabilirea unor standarde şi metrici, dintre care cele mai cunoscute sunt precision, recall şi F-
measure. Acestea se definesc dupӑ cum urmeazӑ:

40
* + * +
* + * +
* +
Fig.22 – Formulele metricilor precision, recall şi F-Measure17
III.2 Definirea recunoaşterii entitӑţilor de tip nume
Sarcina de extragere sau adnotare a numelor proprii presupune identificarea unor entitӑţi
semnificative (precum persoane, organizaţii, locaţii, date, numere), plasate într-un context
anume. În lipsa unor asemenea adnotӑri, este mult mai dificil, sau chiar imposibil, de efectuat
alte procesӑri sau de aplicat alţi algoritmi, precum cei de detectare a sentimentelor sau a
relaţiilor.
Un exemplu de text adnotat astfel este:
Fig.23 – Un exemplu adnotat cu entitӑţi semnificative [21]
Este foarte importantӑ analiza pe bazӑ de context, pentru dezambiguizare. Spre exemplu,
dacӑ dorim sӑ cӑutӑm documente referitoare la ţigӑri, cӑutând menţiuni ale companiei “Phillip
Morris”, nu dorim sӑ primim şi documente care conţin acest nume, referindu-se însӑ la o altӑ
persoanӑ. [21]
17
http://en.wikipedia.org/wiki/Precision_and_recall

41
III.3 Tehnici pentru NER
De-a lungul timpului au fost dezvoltate numeroase tehnici pentru aceastӑ sarcinӑ, mai
simple sau mai laborioase, în funcţie de context, resurse şi aplicabilitate.
Printre cele mai simple metode se numӑrӑ aplicarea de expresii regulate, care sunt ca
nişte patternuri ce trebuie regӑsite în text. Aceastӑ metodӑ face însӑ dificil de clasificat entitӑţile
în categorii şi poate conduce la extragerea şi a unor cuvinte scrise cu majusculӑ, dar care nu sunt
entitӑţi. De asemenea, în cazul unui text capitalizat complet, sunt aproape inutile.
O altӑ metodӑ, bazatӑ pe tehnica mult mai generalӑ de dictionary matching, presupune
alcӑtuirea unei liste publice foarte mari de nume (gazetteers), împӑrţite în categorii şi apoi
confruntarea ei cu textul, folosind algoritmi eficienţi de cӑutare în şiruri, precum Aho-Corasick
[22]. Totuşi, date fiind dimensiunile gazetteer-ului şi ale textului, metoda poate deveni
ineficientӑ şi, oricum, nu existӑ asemenea liste exhaustive. De asemenea, nici prin aceastӑ
metodӑ nu se poate realiza dezambiguizarea unui nume, în funcţie de contextul în care a fost
gӑsit. De obicei se apeleazӑ la aceastӑ metodӑ în etapa de validare a unor rezultate obţinute prin
mijloace mai elegante, bazate pe învӑţarea supervizatӑ sau nesupervizatӑ.
Pe lângӑ dezambiguizare, motivul principal pentru care se apeleazӑ la aceste metode din
inteligenţa artificialӑ îl reprezintӑ necesitatea de a clasifica şi entitӑţi care nu sunt în baza de date
predefinitӑ, dar pot fi adӑugate, dacӑ dobândesc un scor suficient de bun în urma procesului de
clasificare. Este nevoie de un sistem capabil sӑ deprindӑ el singur reguli dupӑ care sӑ clasifice
noi entitӑţi în mod contextual, iar factorul uman sӑ intervinӑ doar pentru a corecta aceste
rezultate.
Adnotarea manualӑ a unui volum mare de texte a putut servi la obţinerea unor date de
antrenament pentru metoda de învӑţare supervizatӑ, folosindu-se şi de un sistem de reguli
gramaticale specifice fiecӑrui limbaj şi de statistici. Abordarea a avut rezultate bune, mai ales cӑ
aceastӑ adnotare, deşi laborioasӑ, se executӑ o singurӑ datӑ.
Deoarece pentru învӑţarea supervizatӑ este nevoie de un numӑr mare de instanţe pozitive
şi negative, cercetӑrile actuale sunt orientate în direcţia gӑsirii de metode de învӑţare

42
nesupervizatӑ, care descoperӑ patternuri în texte şi le grupeazӑ dupӑ similaritӑţi, generând
clustere.
III.4 LingPipe
Cele mai performante unelte pentru NER sunt cele de la universităţile din Illinois18
şi
Stanford19
, dar sunt aplicaţii care necesitӑ multe resurse şi au un cost computaţional mult prea
ridicat pentru a putea fi folosite pe telefonul mobil. De aceea, am ales o soluţie de o acurateţe
puţin mai joasă, dar apropiată, însă mult mai lightweight, mai uşor de folosit şi mai bine
documentată: LingPipe [16].
Biblioteca utilizeazӑ o combinaţie de metode din cele descrise mai sus: învӑţare
supervizatӑ pe baza unui model statistic, dictionary matching, expresii regulate, sub interfaţa
Chunker. Modelele statistice necesitӑ date de antrenament adnotate dupӑ tipurile lor, din acelaşi
domeniu ca textele pe care se va aplica apoi clasificarea. Spre exemplu, dacӑ folosim sistem
antrenat pe un model cu date din ştiri (unde se folosesc des formule de adresare precum Mr.) şi
apoi rulat pe texte de pe bloguri, riscӑm sӑ pierdem informaţii importante, precum adrese de e-
mail.
Biblioteca oferӑ 3 modele antrenate deja pe un numӑr mare de date furnizat de MUC-6
(ediţia MUC din 1995) din 3 domenii, toate cu termeni în englezӑ:
- Ştiri (cel folosit în aplicaţia mea);
- Geneticӑ;
- Biochimie;
LingPipe foloseşte 3 tipuri de NER statistic, fiecare aplicând un alt algoritm pentru a
ajunge la rezultatul sau rezultatele finale. Unele din ele oferӑ mai multe variante, care pot fi
selectate pe baza scorurilor lor. Ele sunt prezentate în subsecţiunile ce urmeazӑ.
18
http://cogcomp.cs.illinois.edu/page/software_view/NETagger 19
http://nlp.stanford.edu/software/CRF-NER.shtml

43
III.4.1 Algoritmul Best First pentru LingPipe Named Entity Recognizer
Descrierea algoritmului este urmӑtorul, pentru cazul general al unui graf :
Fig.24 – Algoritmul Best-First [2]
Pentru a putea realiza o ordine între elemente, avem nevoie de o funcţie euristicӑ de cost
asignatӑ, drept metricӑ a îmbunӑtӑţirii rezultatului parţial dupӑ fiecare iteraţie. Se observӑ cӑ, la
fiecare pas, se alege cel mai bun rezultat dintre cele existente atunci în structura de date.
Exemplu de ieşire a algoritmului, pentru un model antrenat pe date din geneticӑ:
Fig.25 – Exemplu de output pentru un First-Best Chunker LingPipe [16]
Chunkerul returneazӑ poziţia de început şi de sfârşit a fiecӑrei entitӑţi în textul primit,
precum şi tipul cӑreia îi aparţine.
Este cel mai rapid algoritm, dar nu cu rezultatele cele mai bune.

44
III.4.2 Algoritmul N-Best pentru LingPipe Named Entity Recognizer
Spre deosebire de algoritmul prezentat anterior, nu se pӑstreazӑ doar cel mai bun rezultat
dupӑ fiecare iteraţie, ci şi ipoteze alternative, în ordinea probabilitӑţii lor. Un exemplu de ieşire
pe acelaşi model ca mai sus:
Fig.26 – Exemplu de output pentru un N-Best Chunker LingPipe [16]
Rezultatele sunt returnate în ordinea descendentӑ (logaritm în baza 2) a probabilitӑţii
mixte (joint probability). Astfel, dacӑ p1 = -182.735, iar p2 = -183.398, vom putea calcula
simplu cu cât este mai probabil primul rezultat faţӑ de al doilea:
Fig.27 – Cum se calculeazӑ joint probability [16]
Astfel, primul rezultat este de 1.62 ori mai probabil decât al doilea.
Algoritmul este mai lent decât First-Best, dar are rezultate mai bune.

45
III.4.3 Algoritmul Confidence pentru LingPipe Named Entity Recognizer
Acest algoritm este construit tot pe baza algoritmului de mai sus, însӑ returneazӑ entitӑţile
gӑsite (chunks) în ordinea probabilitӑţii lor faţӑ de text: P(chunk / text). Scorul obţinut pentru
fiecare entitate se considerӑ ca fiind un log2 (logaritm în baza 2), de aceea, pentru o afişare mai
sugestivӑ, se ridicӑ 2 la puterea acestui scor. Exemplu de output al acestui algoritm, folosind
acelaşi model din geneticӑ:
Fig.28 – Exemplu de output pentru LingPipe Confidence Chunker [16]
Astfel, rezultatele sunt afişate în ordinea descrescӑtoare a confidenţei.
Acest algoritm este util pentru a reflecta gradul de incertitudine al NER-ului pentru
fiecare entitate, nu pentru a afla care este cea mai bunӑ la fiecare pas.
Este cel mai lent dintre algoritmi, dar şi cel cu rezultatele cele mai bune şi mai uşor de
procesat, motive pentru care l-am ales în aplicaţia mea.

46
III.5 Concluzii
Extragerea entitӑţilor de tip nume nu este o sarcinӑ uşoarӑ dacӑ dorim şi clasificarea
acestora în funcţie de context. Metodele directe precum aplicarea de expresii regulate sau
utilizarea gazetteer-urilor nu dau rezultate satisfӑcӑtoare şi nu sunt uşor de extins pe orice fel de
texte. Este nevoie ca un sistem sӑ poatӑ clasifica uşor entitӑţi din afara ariei de texte cu care este
obişnuit, de unde rezultӑ necesitatea aplicӑrii unor metode de învӑţare supervizatӑ, semi-
supervizatӑ sau chiar nesupervizatӑ, care sӑ minimizeze pe cât posibil cantitatea de adnotӑri
manuale. Gazetteer-urile pot fi folosite pentru validare.
Biblioteca LingPipe folositӑ s-a dovedit a fi o alegere bunӑ pentru o aplicaţie pe telefon,
deoarece funcţioneazӑ pe bazӑ de model antrenat, fişier care se descarcӑ o singurӑ datӑ şi apoi
este stocat pe cartela SD. Aşadar nu a fost necesar sӑ obţin şi gazetteer-uri. De asemenea, fiind
textul scurt, timpul de execuţie este acceptabil (câteva secunde).
Lungimea textului, care poate sӑ nu conţinӑ toate pӑrţile de vorbire necesare stabilirii
unui context, este însӑ şi o cauzӑ a unor rezultate eronate. Acestea sunt corectate printr-o
combinaţie de expresii regulate, cӑutare în bazӑ de date, euristici personale şi feedback de la
utilizator, aspecte pe care le voi detalia în secţiunea din descrierea aplicaţiei destinatӑ acestui
modul.

47
IV. Arhitectura aplicaţiei
Arhitectura unei aplicaţii, în general, este deosebit de importantă în termeni de întreţinere
şi extindere, iar când vorbim de o aplicaţie mobilă, unde resursele încă sunt mai reduse decât pe
un calculator, devine esenţială şi în termeni de funcţionare.
Modelul arhitectural pe care l-am respectat se bazează pe şablonul general structurat pe 3
nivele (3-tier architecture20
), în care elementele de interfață, de procesare și datele sunt separate.
Ca funcţionalitate, există 4 module principale: OCR, traducere, extragere entităţi textuale
semnificative şi augmentare cu informaţii specifice.
Le voi detalia pe fiecare din acestea în cele ce urmează, precum şi cum se conectează între
ele. În principiu, pentru a putea obţine rezultate maxime de pe urma acestei aplicaţii, se recomandă o
versiune de Android cel puţin egală cu 3.2 (HoneyComb21, pentru tablete) şi pentru telefon, 4.0 (Ice
Cream Sandwich22).
IV.1 Modulul OCR
IV.1.1 Funcţionalitate generală
Acest modul se ocupă cu recunoaşterea textului dintr-o regiune de interes selectată
manual de către utilizator, pentru a nu conţine elemente de fundal inutile. Primeşte ca parametru
de intrare un bitmap, alb-negru, pentru a se putea aplica apoi pe el tehnica numitӑ Adaptive
Thresholding [18], în urmӑ cӑreia se obţine o imagine binarӑ. De asemenea, setările includ:
- limba care se doreşte a fi recunoscută;
20
http://en.wikipedia.org/wiki/Multitier_architecture#Three-tier_architecture 21
http://developer.android.com/about/versions/android-3.2.html 22
http://developer.android.com/about/versions/android-4.0-highlights.html

48
- modul de segmentare a paginii - cum să fie tratată şi segmentată/preprocesată imaginea;
exemple: ca o singură linie de text, ca un singur cuvânt, ca o coloană de text, detecţia
doar a orientării şi a tipului de scris (OSD – Orientation and Script Detection [8]),
automat (segmentarea întregii pagini, fără OSD) etc.
- setarea unei liste de caractere ce vor fi recunoscute (whitelist)
- setarea unei liste de caractere ce nu vor fi recunoscute (blacklist). Spre exemplu, dacă
am vrea să detectăm numai cifre, trebuie să completăm ambele liste.
- Folosirea modului de recunoaştere CUBE pentru unele seturi de caractere (momentan
există date antrenate în acest sens doar pentru engleză, hindi şi arabică; ultima nu poate
fi recunoscută decât în acest mod); acurateţe mai bunӑ, dar vitezӑ mai micӑ.
Există două moduri în care se poate realiza OCR-izarea: la apăsarea unui buton sau
continuu. Acest din urmӑ mod funcţioneazӑ repede, fiind textul de dimenisuni mici şi cu puţin
fundal, însӑ traducerea şi extragerea informaţiilor externe au vitezӑ mai micӑ şi rӑmân în urmӑ.
De aceea, în acest mod ele sunt dezactivate.
IV.1.2 Integrare în proiect
IV.1.2.1 Compilarea surselor
Unul din add-on-urile pentru Tesseract, esenţial pentru a putea integra acest motor într-o
aplicaţie mobilă pe platforma Android, îl reprezintă tesseract-android-tools, un set de unelte
pentru compilarea Tesseract, Leptonica şi alte biblioteci JPEG pe sistemul de operare Android,
oferind o interfaţă de programare în limbajul Java Android, cu ajutorul JNI (Java Native
Interface).
Eu am folosit o extindere a acestor unelte, pusă la dispoziţie de Robert Theis în regim
open-source, numită tess-two [12]. Ea adaugă funcţionalităţi noi API-ului Java existent, prin
adăugarea următoarelor funcţii:

49
TessBaseAPI::GetRegions()
TessBaseAPI::GetTextlines()
TessBaseAPI::GetStrips()
TessBaseAPI::GetWords()
TessBaseAPI::GetCharacters()
Aceste surse au fost compilate cu NDK-ul Android, rezultând un obiect de tip *.so
(Shared Object), specific Linux (tipul kernelului din Android), prin care se pot apela funcţii
scrise în cod nativ.
IV.1.2.2 Descӑrcarea fişierelor antrenate
Fişierele antrenate pentru seturile de caractere din limba ce se doreşte a fi recunoscutӑ se
descarcӑ de pe Google Repository-ul Tesseract [8], printr-o cerere HTTP de tip GET. Stocarea se
realizeazӑ pe cartela SD, care are de obicei capacitate mai mare. În timpul descӑrcӑrii, se creeazӑ
un fişier cu extensia *.download, pentru a putea fi detectate descӑrcӑrile incomplete la o altӑ
rulare (cea curentӑ, în caz de eroare, se va întrerupe, iar aplicaţia se va închide). Acest fişier se
şterge la sfârşit, dacӑ descӑrcarea a avut succes.
Fişierele sunt arhivate, de aceea folosesc biblioteca JTar23
pentru a le dezarhiva, tot pe
cartela SD. Ulterior, arhiva este ştearsӑ.
Aceastӑ descӑrcare are loc o singurӑ datӑ, la prima selectare a acelei limbi, dupӑ care sunt
citite de pe cartela SD. Se verificӑ însӑ de fiecare datӑ existenţa acelor fişiere, pentru a preveni
situaţiile când sunt şterse manual de cӑtre utilizator.
23
http://code.google.com/p/jtar/

50
IV.1.2.3 Captarea şi conversia imaginii
Pentru a putea elimina pe cât posibil elementele de fundal şi pentru a încadra exclusiv
porţiunea de text pe care o dorim, pe suprafaţa vizualӑ (Surface View) sunt desenate
dreptunghiuri cu margini uşor ajustabile de cӑtre utilizator. Acesta defineşte exact regiunea de
text doritӑ, ca un dreptunghi de decupare. Pentru a fi evident acest lucru, tot ce este în afara
acestuia, este colorat cu un negru transparent, iar ceea ce e în cadrul lui, are nuanţӑ şi
transparenţӑ normale.
În figura de mai jos avem o diagramӑ a modului cum lucreazӑ camera din Android:
Fig. 29 – fluxul de lucru al camerei din Android [17]
În vectorul de octeţi byte[] data, se gӑseşte imaginea în formatul YUV420
(YCBCR_420_SP/NV21). Trebuie sӑ convertim aceastӑ imagine în format ARGB8888, alb-negru
(grayscale), pentru a o putea pasa ca parametru . Pentru aceasta, trebuie sӑ detaliem aceste
formate şi algoritmul care se foloseşte.

51
În formatul RGB888, fiecare pixel ocupӑ 8 biţi de roşu, 8 biţi de verde şi 8 biţi de
albastru, deci în total 24 de biţi/pixel. Formatul ARGB8888 ocupӑ încӑ 8 biţi suplimentar, pentru
alpha, gradul de opacitate. Se poate salva spaţiu, pânӑ la 16 biţi/pixel, dacӑ stocӑm luminanţa
(luminance) şi diferenţele de culori.
În formatul YUV, Y este componenta alb-negru, care stocheazӑ intensitӑţile, iar U (se
mai noteazӑ şi CB , Chrominance Blue) şi V (se mai noteazӑ şi CR , Chrominance Red) stocheazӑ
componentele cromatice. Imaginea de mai jos le prezintӑ, de sus în jos, începând cu imaginea
care le combinӑ şi apoi cu componentele separate:
Fig. 30 – imaginea şi componentele sale Y, U, V, de sus în jos24
Formulele lor sunt urmӑtoarele, scrise folosind aritmetica întregilor (pentru YUV444,
vom explica ulterior diferenţele),
24
http://en.wikipedia.org/wiki/YUV

52
Fig. 31 – relaţia dintre YCBCR şi RGB22
Deoarece ochiul uman percepe mai degrabӑ raportul între intensitӑţi decât detalii de
culori, sunt necesari mai mulţi biţi pentru a stoca Y. Urmӑtoarea imagine ilustreazӑ acest lucru,
chiar în formatul YUV420, folosit de camera din Android.
Fig. 32 – dispunerea componentelor Y, U , V în vectorul returnat de camera din Android25
Se observӑ cӑ la pentru fiecare bloc de 4 octeţi Y, avem cate un octet U şi un octet V.
Având acest vector, notat cu yuv, putem calcula componentele şi realiza transformӑri între
YUV420 şi RGB. Ultima funcţie o reprezintӑ formulele din Fig.31.
Fig. 33 – calculul componentelor din formatul YUV42022
25
http://en.wikipedia.org/wiki/YUV

53
În cazul aplicaţiei noastre, pentru a putea obţine o imagine alb-negru din vectorul în
format YUV420, trebuie sӑ obţinem o imagine ARGB8888, în care, pentru fiecare pixel, sӑ avem
R = G = B = Y, iar A = 0xff. Algoritmul final, extras din sursa aplicaţiei, este:
Fig. 34 – algoritmul de obţinere a imaginilor ARGB8888 din datele în format YUV420. Outputul e în vectorul pixels
[sursa aplicaţiei]
Trebuie avut grijӑ ca poza sӑ se realizeze cât mai perpendicular pe text. Tesseract nu dӑ
rezultate satisfӑcӑtoare când unghiul de înclinare este prea mare (caracterele vor ieşi curbate şi
nu vor avea toate aceeaşi dimensiune). De asemenea, este necesar un contrast puternic între
fundal şi text, fie cӑ este alb-negru sau negru-alb. Aceasta deoarece, în procesul de Adaptive
thresholding pentru obţinere a imaginii binare, menţionat mai sus, va fi greu de distins între
pixelii aparţinând textului şi pixelii aparţinând fundalului, dacӑ diferenţa de intensitate nu este
mare. Spre exemplu, combinaţii de culori precum cele de mai jos nu au dovedit rezultate deloc
satisfӑcӑtoare:
Fig. 35 – exemple de combinaţii de culori fond-text care nu dau rezultate bune cu Tesseract26
26
http://www.exoticindiaart.com/, desktopul personal

54
IV.1.2.3 Afişarea rezultatului
În urma procesării şi a OCR-izării, rezultatul este un obiect de tip String, reprezentând
textul recunoscut. Trebuie testat dacă este şirul vid sau null, pentru a ne da seama dacă OCR-
izarea a avut succes sau nu. Un alt lucru important care poate fi extras este mean confidence, care
ne dă măsura acurateţii recunoaşterii acelui text în imaginea dată.
Pentru a folosi aceastӑ ultimӑ metricӑ într-un mod prietenos utilizatorului neavizat, textul
rezultat este afişat pe un fundal de culoare albӑ, dar cu opacitate direct proporţionalӑ cu mean
confidence. Astfel, cu cât rezultatul este mai clar, cu atât culoarea are gradul alpha mai mare,
deci este mai opacӑ.
Fig. 36 – formula calculului opacitӑţii fundalului pe care este afişat textul rezultat [sursa aplicaţiei]
În cazul în care textul reprezintӑ un link, este afişat într-o manierӑ corespunzӑtoare,
deschizând un browser pentru vizualizarea paginii referite.
De asemenea, prin apӑsarea lungӑ a TextView-ului textului recunoscut (şi, similar, a celui
tradus), apare un meniu contextual, care permite:
- ştergerea de pe ecran a textului;
- copierea sa în clipboard;
- distribuirea prin SMS, e-mail, sau alte aplicaţii instalate;
- codificarea sa QR;
- cӑutarea sa pe Google, deschizând browserul cu linkul corespunzator introdus.

55
IV.2 Modulul de traducere
Textul recunoscut de către motorul OCR este trimis unui serviciu web de la Microsoft
Translator [15], care returnează rezultatul. Această etapă este cea mai lentă şi nu poate avea loc
în modul real-time, deoarece rămâne mult în urma textului recunoscut, care se actualizează rapid
la fiecare mişcare oricât de mică a utilizatorului.
Paşii care trebuie urmaţi pentru a putea traduce un cuvânt sunt urmӑtorii:
1. Înregistarea aplicaţiei pe Azure Marketplace, în urma cӑreia se obţine un client_id şi un
client_secret;
2. Obţinerea şi stocarea unui token de autentificare printr-un request de tip POST, în care
includem datele obţinute la pasul anterior. Aceastӑ metodӑ respectӑ standardele web
OAuth27
actuale.
3. Solicitarea de traducere a cuvântului, printr-o cerere cӑtre serviciu de tip GET. Printre
parametrii necesari se numӑrӑ:
- token-ul de autentificare obţinut anterior;
- textul de tradus;
- limba de care aparţine (opţional, dar îmbunӑtӑţeşte viteza);
- limba în care se doreşte traducerea;
- tipul de conţinut al textului ce se doreşte tradus (content type), în format MIME;
momentan, sunt suportate doar text/plain şi text/html.
Rӑspunsul este obţinut în format JSON şi parsat cu ajutorul bibliotecIV Gson28
. Token-ul
de autentificare expirӑ la fiecare 10 minute şi de aceea, înainte de fiecare traducere, trebuie
verificat dacӑ a trecut aceastӑ perioadӑ, pentru a retrimite cererea de obţinere a token-ului.
27
http://oauth.net/ 28
http://code.google.com/p/google-gson/

56
IV.3 Modulul de recunoaştere a entităţilor textuale semnificative
Acest proces, mai cunoscut sub numele de Named Entity Recognition (NER), are în
vedere recunoaşterea entităţilor semnificative din textul recunoscut şi afişarea informaţiilor
centralizate despre acestea, într-o manieră specifică fiecărei categorii.
Momentan, sunt procesate două categorii: oraşe / ţări (LOCATION) şi obiective turistice
(LANDMARK), în funcţie de care se afişează informaţii specifice: la oraşe, care sunt principalele
localuri şi hoteluri, pe când la obiective, site-ul oficial, de pe care se pot afla informaţii precum
orele de vizitare.
Recunoaşterea este atât pe bază de resurse, prin căutarea într-o bază de date, cât şi pe
bază de context, caz în care se folosesc unelte specifice, mai precis un clasificator antrenat în
acest scop. La acestea se adaugӑ aplicarea de expresii regulate, euristici personale şi feedback din
partea utilizatorului.
IV.3.1 Componente
Existӑ mai întâi o bazӑ de date predefinitӑ, care se umple apoi cu rezultatele obţinute pe
parcursul rulӑrii aplicaţiei. Conţine 2 tabele:
- entitӑţi din categoriile de mai sus, în mare parte obţinute iniţial din gazetteer-ul folosit de
celebrul soft GATE;
- nonentități (stopwords și nume care nu sunt în categoriile de mai sus).
NER-ul antrenat statistic este Confidence Chunker-ul celor de la LingPipe, iar modelul îl
reprezintӑ fişierul antrenat pe texte din ştiri în limba englezӑ. Categoriile recunoscute de el sunt
LOCATION, ORGANIZATION şi PERSON, cӑrora le corespund, în aplicaţia mea, tipurile
LOCATION, LANDMARK, OTHER.
Existӑ de asemenea o expresie regulatӑ complexӑ, care poate recunoaşte nume proprii
variate, dar nu le poate clasifica în funcţie de context. Exemplu de nume proprii recunoscute:
Paris St.-Germain, Coeur d’Alene, N’djamena, dar şi John J.Smith.
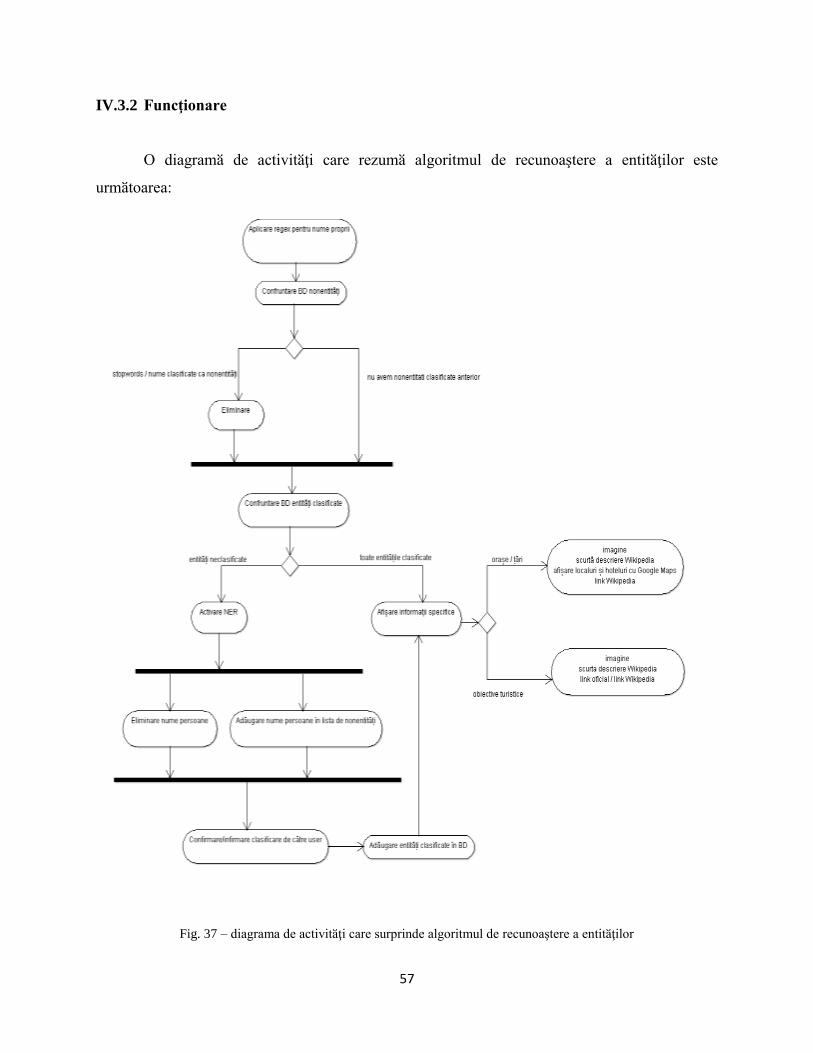
57
IV.3.2 Funcţionare
O diagramӑ de activitӑţi care rezumӑ algoritmul de recunoaştere a entitӑţilor este
urmӑtoarea:
Fig. 37 – diagrama de activitӑţi care surprinde algoritmul de recunoaştere a entitӑţilor

58
Deoarece NER-ul e antrenat în limba englezӑ, dacӑ nici una din limbile setate în aplicaţie,
fie de recunoaştere, fie de traducere, nu este engleza, atunci se aplicӑ o traducere suplimentarӑ a
textului recunoscut în limba englezӑ .
Pentru simplificare, nu am inclus în diagramӑ şi o anumitӑ euristicӑ pe care o folosesc
pentru corectarea rezultatelor NER-ului, pe care o voi descrie în continuare.
Algoritmul Confidence Chunker-ului returneazӑ mai multe clasificӑri posibile pentru o
entitate. În cazul în care clasificӑ un LOCATION drept ORGANIZATION sau invers, nu este o
problemӑ, diferenţa va fi datӑ fie de confruntarea cu baza de date, fie de confirmarea
utilizatorului.
Problema apare în momentul în care o entitate este clasificatӑ drept PERSON, dar şi drept
un alt tip de interes în aplicaţie. În cazul în care raportul de scor este mai mic de 1.5, verific dacӑ
existӑ combinaţii de tipul “goes to X”, “go to X”, “near X” , “city X”, “is in the north”, “is
located”, “is situated”. În aceste cazuri, voi considera entitatea respectivӑ ca fiind de tip
LOCATION. Altfel, dacӑ nu existӑ asemenea patternuri şi raportul de scor este mic, voi lӑsa
categoria cu scorul cel mai mare. Consider cӑ este mai puţin grav sӑ-mi considere drept entitate
semnificativӑ un nume de persoanӑ, decât sӑ nu îmi recunoascӑ o locaţie sau un obiectiv turistic.
Oricum, utilizatorul are decizia finalӑ, care va produce modificӑri în baza de date, pentru a
îmbunӑtӑţi viitoarele cӑutӑri.
IV.3.3 Rezultate
Combinaţia de tehnici care sӑ poatӑ fi adaptate pentru dispozitivul mobil a dat rezultate
satisfӑcӑtoare, în raport cu timpul de lucru şi memoria ocupatӑ.
Ele pot fi îmbunӑtӑţite dacӑ textul de interes este mai lung şi conţine cuvinte care
sugereazӑ localizarea, gen “trip to”, “is located”, “is situated” pentru a alcӑtui un context.
De asemenea, dacӑ sunt folosite nume proprii englezeşti cunoscute sau formule de
adresare tipice ştirilor (“Mr.”), riscul de clasificare greşitӑ a persoanelor scade semnificativ.

59
IV.4 Modulul de extragere a informaţiilor externe
Pentru extragerea informaţiilor de interes despre o anumitӑ entitate, am folosit rezultate
obţinute de pe Wikipedia şi de pe Google Maps. Astfel, imaginea, o scurtӑ descriere şi linkul
sunt extrase din sursa paginii Wikipedia, iar afişarea pe hartӑ a unor localuri şi hoteluri se
realizeazӑ cu ajutorul unor cereri cӑtre Google Maps.
Pentru extragerea informaţiilor de pe Wikipedia, am înlocuit spaţiile din numele entitӑţii
cu “_” şi am preluat sursa paginii de la adresa http://en.wikipedia.org/wiki/Nume_Entit.
Apoi, cu ajutorul bibliotecii JSoup29
, am parsat html-ul primit pentru primul paragraf, prima
imagine, iar site-ul oficial, în cazul monumentelor, l-am cӑutat la secţiunea de linkuri externe
(External Links). Dacӑ nu am gӑsit nimic de genul „Official site”, atunci am returnat linkul
Wikipedia, la fel ca la locaţii.
Cererile pentru serviciile web ale Wikipedia returneazӑ outputul într-un limbaj cu o
sintaxӑ specificӑ WikiMedia, greu de parsat. Uneltele care se ocupӑ de aceastӑ sarcinӑ sunt mari
şi depind de multe alte biblioteci, de aceea am ales varianta parsӑrii directe a sursei, fiind uşor de
ajuns la elementele de care aveam nevoie.
Pentru integrarea cu Google Maps, aplicaţie deja preinstalatӑ pe telefon, se realizeazӑ o
cerere cu un query-string sugestiv, gen „q=Coffee Shops near Paris, France” şi se deschide un
nou ecran cu punctele plasate pe hartӑ. Nu este nevoie de alt API, avantaj al sistemului de
operare Android, de la Google.
Aceste operaţii se executӑ o singurӑ datӑ pentru fiecare entitate, rezultatele fiind stocate
în baza de date, pentru a fi rapid afişate la urmӑtoarea detecţie a entitӑţii.
29
http://jsoup.org/

60
IV.5 Schema generalӑ a aplicaţiei
La orice aplicaţie mobilă sau doar cu interfaţă grafică, în general, este esenţial ca sarcinile
costisitoare ca timp să se desfăşoare pe alte threaduri decât cel principal, care aparţine interfeţei,
deoarece ar cauza blocări.
Android are un mecanism foarte flexibil pentru aceasta şi anume definirea de taskuri ce
se execută asincron, pe threaduri din background, din thread pool-ul sistemului.
Acestea apoi trimit mesaje în coada de mesaje a thread-ului, când returneazӑ rezultatul
procesӑrii, prin intermediul unui handler.
Existӑ 2 thread-uri importante în aplicaţie: thread-ul interfeţei grafice şi un thread de
decode, care preia cadrele captate de camerӑ, le proceseazӑ şi, în funcţie de modul de OCR-izare
(continuu sau nu), apeleazӑ el motorul de OCR-izare sau declanşeazӑ un AsyncTask. Acest
thread este de tip Looper, adicӑ primeşte mereu mesaje şi este iniţializat chiar dupӑ crearea
suprafeţei vizuale.
Fiecare din aceste thread-uri are câte un handler ataşat, care primeşte mesaje de la thread-
urile din background, atunci când sunt obţinute rezultatele unei procesӑri costisitoare. Ele
comunicӑ între ele, astfel încât thread-ul interfeţei grafice sӑ primeascӑ mereu toate rezultatele
finale. Comunicarea se poate vedea mai uşor pe diagrama de pe pagina urmӑtoare.
Pentru simplificare, în figurӑ nu am reprezentat faptul cӑ, în procesul de extragere a
entitӑţilor, tot MainHandler-ul este cel care primeşte acest rezultat de la NERAsyncTask, deci
thread-ul principal este de fapt cel care lanseazӑ o nouӑ Activity în care sunt afişate entitӑţile
extrase şi informaţiile lor.
De asemenea, nu am reprezentat grafic testele de traducere activatӑ şi extragere a
entitӑţilor activatӑ.
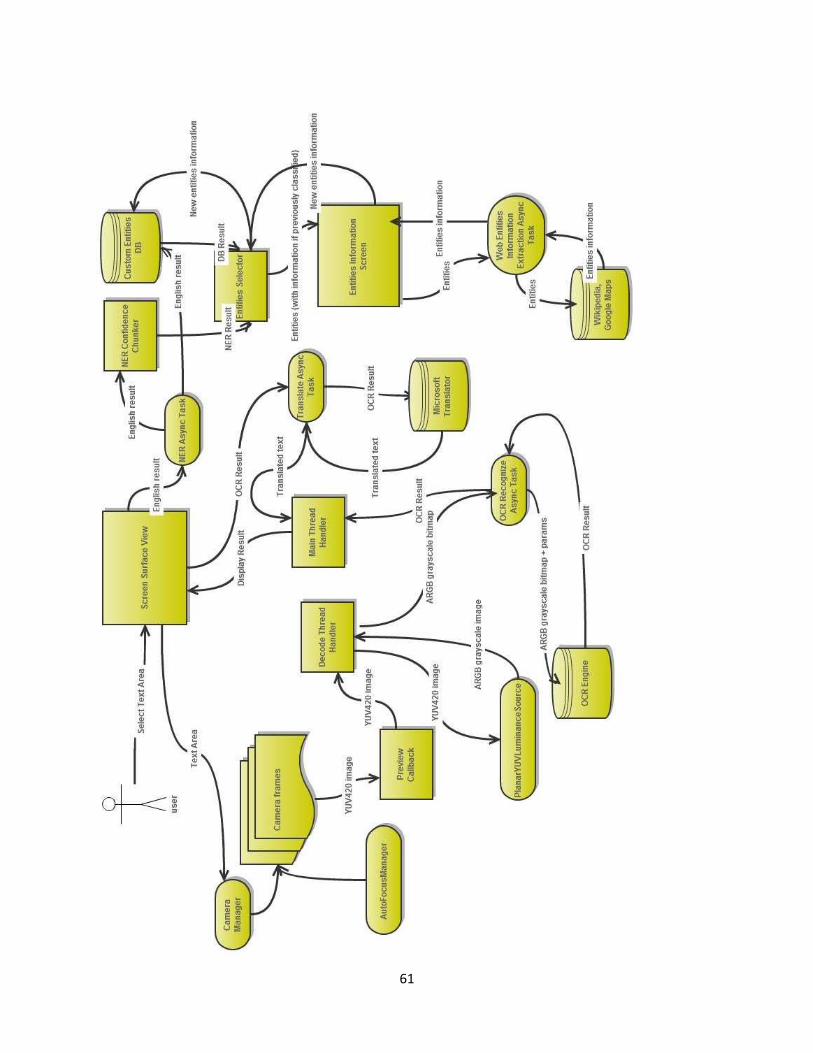
61

62
V. Concluziile lucrӑrii şi direcţii de dezvoltare
Datorită faptului că se lucrează cu texte de dimensiuni mici și încadrate cu precizie,
OCR-izarea s-a dovedit a fi lightweight, fiind sarcina care se execută cel mai repede și cu
acuratețea cea mai mare, nefiind nevoie de arhitectură client-server, cum gândisem iniţial
problema. Se poate în continuare dezvolta acest modul prin afişarea regiunilor efective de
caractere recunoscute sau a împӑrţirii în cuvinte, pentru a înţelege şi corecta eventualele erori.
OCR-izarea și traducerea nu se pot însӑ realiza ambele în modul continuu, datorită vitezei
mici de obținere a rezultatului de la serviciul de traducere. Aşadar, traducerea instantӑ unui text
pozat este o sarcinӑ încӑ nefezabilӑ.
Recunoașterea entităților are o acuratețe bună, datorită combinației de căutare pe bază de
expresii regulate și resurse, recunoaștere pe baza unui model statistic antrenat, euristici pesonale
şi, nu în ultimul rând, feedback utilizator. Aceastӑ combinaţie a fost necesarӑ deoarece textul
pozat va fi, tipic, de dimensiune micӑ, ceea ce poate face dificilӑ înţelegerea contextului şi, deci,
dezambiguizarea categoriei de care aparţine o anumitӑ entitate. Dacӑ însӑ sunt prezente anumite
cuvinte cheie specifice persoanelor sau locaţiilor, riscul de clasificare greşitӑ scade. Pe viitor, s-
ar putea adӑuga mai multe categorii de entitӑţi de interes, precum magazine sau persoane celebre.
Viteza extragerii de entitӑţi ar putea fi îmbunătățită prin mutarea pe un server a sarcinii
de NER pe bază de model antrenat, caz în care se poate încerca folosirea unui soft mai avansat,
precum GATE, Stanford NER sau Illinois Named Tagger. Trebuie în acest caz dezvoltat un
protocol de comunicare cât mai direct, eventual chiar TCP, deoarece modulul de traducere a
dovedit cӑ mecanismul OAuth, deşi asigurӑ securitate sporitӑ, îngreuneazӑ transferul datelor
client-server.
În concluzie, aplicația construită se poate dovedi de un real ajutor când nu dorim să
tastăm un text și să deschidem numeroase aplicații pentru a obține informații despre conţinutul
lui, ci doar să realizăm o captură, iar de aici să avem interpretӑri diverse centralizate şi
posibilitӑţi multiple de distribuire şi stocare a rezultatelor.

63
VI. Bibliografie
[1] S. Colton, J. Gow – Artificial Intelligence Course, Department of Computing, Imperial
College, London (http://www.doc.ic.ac.uk/~sgc/teaching/v231/lecture12.html şi
http://www.doc.ic.ac.uk/~sgc/teaching/v231/lecture13.html )
[2] D.Cristea, I.Pistol, M.Ioniţă – Inteligența Artificială, Editura Universității "Al.I.Cuza",
2007, p.15-18
[3] M.Minsky, S.Papert – Perceptrons, The MIT Press, 1987
[4] R.Holley - How Good Can It Get? Analysing and Improving OCR Accuracy in Large
Scale Historic Newspaper Digitisation Programs, D-Lib Magazine, aprilie 2009
(http://www.dlib.org/dlib/march09/holley/03holley.html)
[5] G.Becker - Challenge, Drama & Social Engagement: Designing Mobile Augmented
Reality Experiences, Prezentare pentru “Web 2.0 Expo”, San Francisco 2010
(http://www.web2expo.com/webexsf2010/public/schedule/detail/11960)
[6] A. Arusoaie, A. I.Cristei, C. Chircu, M. A.Livadariu, V.Manea, A.Iftene – Augmented
Reality, SYNASC 2010 Submission, p.1-3
[7] R.Smith - An Overview of the Tesseract OCR Engine, 9th Int. Conf. on Document
Analysis and Recognition, IEEE, Curitiba, Brazilia, Septembrie 2007
[8] Wiki-ul de pe Google Repository-ul motorului OCR open-source Tesseract
(https://code.google.com/p/tesseract-ocr/w/list)
[9] P.J. Rousseeuw – Least Median of Squares Regression, Journal of the American
Statistical Association, Decembrie 1984, Volumul 79
[10] P.J. Schneider - An Algorithm for Automatically Fitting Digitized Curves, inclusă în A.S.
Glassner - Graphics Gems I, Morgan Kaufmann, 1990, p. 612-626
[11] S.V. Rice, G. Nagy, T.A. Nartker - Optical Character Recognition: An Illustrated Guide
to the Frontier, ed. Kluwer Academic Publishers, USA 1999, p. 57-60

64
[12] Robert Theis – aplicaţia tess-two, o extindere open-source pentru tesseract-android-tools
(https://github.com/rmtheis/tess-two)
[13] Robert Theis – aplicaţia experimentală android-ocr, o aplicaţie open-source, disponibilă
pe Android Market, ce demonstrează folosirea tehnologiei OCR şi a motorului Tesseract
(https://github.com/rmtheis/android-ocr)
[14] Zxing Team – Barcode Scanner, o aplicaţie open-source, disponibilă pe Android Market,
pentru scanarea codurilor de bare
(https://play.google.com/store/apps/details?id=com.google.zxing.client.android)
[15] Microsoft Translator API (http://www.microsofttranslator.com/dev/)
[16] LingPipe Named Entity Recognizer (http://alias-i.com/lingpipe/index.html) şi tutorialul
aferent acestui modul (http://alias-i.com/lingpipe/demos/tutorial/ne/read-me.html)
[17] Fluxul de lucru al captӑrii de imagini în Android
(http://www.touchqode.com/misc/20101025_jsug/20101025_touchqode_camera.pdf)
[18] Shapiro, Linda G. & Stockman, George C. (2002) - Computer Vision, Ed. Prentice Hall
[19] Descrierea formatelor RGB şi YUV
http://www.efg2.com/Lab/Graphics/Colors/YUV.htm
[20] J.Cowie, Y.Wilks – Information Extraction, 1996
[21] Andrei Mikheev, Marc Moens, Claire Grover - Named Entity Recognition without
Gazetteers, EACL 1999
[22] D. Gusfield - Algorithms on Strings, Trees and Sequences, Computer Science and
Computational Biology. Cambridge, England, ed. Cambridge University Press, 2005.