intervale de confidenta
DESCRIPTION
Intervale de confidentaTRANSCRIPT

ESTIMARE PRIN INTERVALE DE CONFIDENȚĂ
Conf. Dr. Lucian V. Boiculese

Introducere În cazul realizării experimentelor de un număr repetat de ori se obţine un număr
finit de evenimente. Observaţiile ce se fac asupra populaţiei pot fi totale (dacă se studiază toate evenimentele, sau toţi indivizii - exhaustiv) sau parţiale (dacă se studiază doar un eşantion din total).
Cercetarea unitară a întregii populaţii în multe situaţii este greu de realizat, poate chiar impracticabilă. O situaţie complementară este aceea în care numărul datelor experimentale este mic. Bazându-ne pe aceste informaţii trebuie deduse caracteristici generale asupra fenomenului sau obiectivului de studiu.
Eşantionul este considerat mic dacă volumul său are un număr de elemente până în 30 şi mare dacă numărul de elemente depăşeşte valoarea 30. Acest prag este necesar pentru a aproxima cât mai bine modificările ce apar în tipul distribuţiei datelor şi ca urmare un volum mare al eşantionului va avea implicaţii pozitive în rezultatele finale. Astfel, funcţie de numărul de valori disponibile, se aplică diferite teste, iar precizia estimărilor este cu atât mai bună cu cât avem mai multe date de studiu.
Scopul principal în cadrul culegerii datelor constă în a obţine cu un efort minim (volum minim de date) un volum maxim de informaţii.

Estimarea constă în operaţia de determinare a parametrilor populaţiei pe baza eşantionului studiat. Datorită lipsei de informaţie generată de cercetarea uneori neunitară cât şi datorită dispersiei parametrilor doriţi, se poate deduce cu o anumită probabilitate (de obicei acceptată la valoarea de 95% în domeniul medical), un anumit interval de încredere în care se află parametrul studiat.
Obiectivul final al unui experiment constă, în majoritatea cazurilor, în a măsura valoarea unui parametru. Valoarea măsurată (izolată de altfel) nu poate fi considerată satisfăcătoare sau valoare de referinţă dacă nu se fac şi precizări referitoare la domeniul de variaţie precum şi la probabilitatea corespunzătoare.
În cadrul estimării parametrilor unei populaţii, valoarea calculată este de fapt o variabilă aleatoare legată de eşantionul studiat. Cu cât avem mai multe eşantioane, cu atât avem mai multe valori ale parametrului care urmează a fi calculat.
Rolul inferenţelor statistice constă în a determina din informaţiile din eşantion concluzii pertinente asupra întregii populaţii. Chiar dacă teoretic putem imagina un număr mare de eşantioane extrase, aplicând metodele statisticii, se pot afla limitele de variaţie ale mediei (ca exemplu de indicator analizat) doar dintr-un singur eşantion de studiu.
Media, acest indicator statistic de importanţă majoră, este în centrul temei de estimare sau evaluare. Această estimare ajută nu numai la caracterizarea unei populaţii, ci şi la compararea diferitelor loturi analizate (este important de menţionat că media poate reprezenta şi frecvenţa de apariţie a unui eveniment – conform legi numerelor mari).

Intervalul de încredere pentru media unei variabile aleatoare de tip continuu repartizată normal
Metoda de lucru pleacă generic de la ideea de a studia variabila aleatoare creată
din media eşantioanelor extrase din populaţia ţintă. Teoretic, putem extrage un număr enorm de eşantioane dintr-o populaţie. Aceste eşantioane pot avea dimensiuni diferite, iar media lor respectă un anumit tip de distribuţie.
Există în statistică teorema limită centrală (rezultat fundamental), care afirmă că
independent de tipul de distribuţie al datelor din populaţie, media eşantioanelor extrase creează un lot de date care urmează o repartiţie de tip Gauss-Laplace (cu condiţia să avem selecţie aleatoare simplă).
Graficul următor exprimă vizual ideea demonstrată prin teorema limită centrală.

Populaţia de
studiu
L1
L2
Li
Ln
L7
Eşantion (lot)
extras
Lot Medie
1 M1
2 M2
3 M3
…. …
45 M45
Distribuţia mediilor este
de tip (Gauss Laplace)
Populația este caracterizată de media μ și deviația standard σ. Din populația de studiu extragem aleator eșantioane.
Calculăm media fiecărui eșantion și creăm astfel o nouă populație definită de aceste
medii. Această nouă populație definește distribuția statistică a mediilor cu ajutorul căreia
putem estima intervalul de confidență. Va avea media μ și deviația standard σ/sqrt(n), unde n este volumul eșantionului.

Vom da un exemplu de determinare a distribuţiei mediilor eşantioanelor dintr-o populaţie care nu este repartizată normal, tocmai pentru a observa forma gaussiană urmată de eşantionul mediilor.
Presupunem că avem o populaţie repartizată liniar constant pe intervalul [0, 1]. Vom extrage 100 eşantioane de dimensiune 30. Pentru fiecare din cele 100 de eşantioane se calculează media, apoi se realizează histograma frecvenţelor absolute.
Acestea sunt reprezentate grafic în figurile următoare.
Histograma datelor din populaţia ţintă
121130
117 113121 128
140 147
121 124
0
50
100
150
200
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 More
Histograma mediilor
(eşantion din 30 elemente)
0
10
20
30
0.1
3
0.2
0.2
8
0.3
5
0.4
3
0.5
0.5
8
0.6
5
0.7
3
0.8
0.8
8
0.9
5
Repartiție uniformă Repartiție normală – Gauss Laplace

Teorema limită centrală Indiferent de tipul distribuţiei populaţiei, media eşantioanelor tinde către
distribuţia Gauss Laplace şi este cu atât mai apropiată de aceasta, cu cât volumul eşantionului creşte (un volum mai mare decât 30 implică erori mici). Observaţii 1 – Dacă distribuţia populaţiei este normală, atunci în mod sigur distribuţia mediilor eşantioanelor este normală şi pentru valori mici ale eşantionului (aici trebuie discutat ce înseamnă în statistică set de date mic ca volum). 2 – Media valorilor medii ale eşantioanelor este media populaţie. Aceasta arată că nu există eroare de deplasare. Matematic putem scrie: . 3 – Deviaţia standard a mediilor eşantioanelor este de radical din n ori mai mică decât deviaţia standard a întregii populaţii. Avem astfel: , unde n reprezintă volumul eşantionului DACĂ CUNOAȘTEM TIPUL DISTRIBUȚIEI MEDIILOR ȘI PARAMETRII ACESTEIA, ATUNCI PUTEM CALCULA INTERVALUL DE CONFIDENȚĂ !
),...,( 21 nXXXM
nX

Exemplu de calcul Cazul 1 – Valoarea dispersiei este cunoscută. Considerăm o variabilă aleatoare repartizată normal N(,2) pentru care dorim să
estimăm intervalul de încredere pentru valoarea mediei. Avem un set de date de volum n şi notăm media calculată din datele eşantionului cu , iar media populaţiei (de obicei necunoscută) cu .
Evident, dacă am putea analiza întreaga populaţie, atunci media calculată ar avea valoarea de încredere 100% iar calculul intervalului de variaţie nu ar avea sens, am avea astfel .
X
X
Se poate demonstra (după cum am amintit deja) că dacă avem mai multe eşantioane dintr-o populaţie normală, media de selecţie este o variabilă aleatoare repartizată normal N(,2/n). Pentru a o centra şi normaliza vom aplica formula
(se scade media şi se raportează la dispersie):
Cu alte cuvinte prin această transformare de variabilă obținem o distribuție
normal standardizată – caracterizată de medie μ=0 și deviație standard σ=1
n
Xz
/

Punem condiția ca această variabilă Z să fie cuprinsă într-un interval simetric față de medie cu probabilitatea standard de 95% (deci acceptăm o eroare de 5%):
195,021 ZZZP
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-4 -3 -2 -1 0 1 2 3 4
f(x) – densitatea de probabilitate
21
Intervalul de încredere
Z1 Z2
Pentru o curba gaussiană standardizată intervalul simetric față de medie cu 95% încredere este determinat de valorile: Z2=-Z1=1,96 (se pot calcula). Pentru interval simetric se folosește notația: Z2=Z(1-α/2) respectiv Z1=-Z(1-α/2)
- α este nivelul de semnificație și pentru interval simetric avem: α1= α2= α/2. Nivelul de încredere este 1- α (notat și β). Putem scrie în continuare:
)2/1(/
)2/1(
Z
n
XZ
nZX
nZX
)2/1()2/1(
n
- se numește eroare standard, este deviația standard a distribuției mediilor eșantioanelor. AVEM ASTFEL METODA DE CALCUL A INTERVALULUI DE CONFIDENȚĂ !!!

Microsoft Excel - funcții pentru determinarea intervalului de încredere Avem funcțiile următoare pentru determinarea valorilor distribuției Gauss Laplace: NORM.S.INV(probability) – calculează valoarea abscisei corespunzător probabilității
cerute pentru o repartiție Gauss standardizată (medie=0, dispersie=1). Exemplu: NORM.S.INV(0.3) = -0.524 Pentru standardul de 95% și pentru interval simetric (deci α/2) avem : Z(1-0.05/2)=NORM.S.INV(0.975)=1.9599 ce se poate aproxima cu 1.96
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
-4.0
0
-3.6
0
-3.2
0
-2.8
0
-2.4
0
-2.0
0
-1.6
0
-1.2
0
-0.8
0
-0.4
0
0.00
0.40
0.80
1.20
1.60
2.00
2.40
2.80
3.20
3.60
4.00
Probabilitate: 0.30 Abscisa notată Z (este variabila de
interes)
Ordonata – densitatea de probabilitate
Suprafața reprezintă probabilitatea.
Abscisa corespunzătoare : NORM.S.INV(0.3) = -0.524

Cazul 2 – Valoarea dispersiei este necunoscută / volum mic. Dacă eșantioanele au volum mic (sub 30) sau dacă repartiția datelor nu este de tip
Gauss-Laplace sau dacă nu se cunoaște valoarea dispersiei populației, atunci folosirea distribuției Z în estimarea intervalului de confidență a mediei va genera erori mari.
Se folosește pentru aceste situații distribuția t sau student, ce dă rezultate bune în situațiile critice prezentate mai sus. Dacă volumul eșantionului crește distribuția student tinde către cea normală – deci nu este nici o greșeală folosirea acesteia în situația în care forma normală este aplicabilă.
Distribuția t (student) depinde de parametrul numit grade de libertate ce depinde de volumul eșantionului. Pentru estimarea intervalului de confidență a mediei unei variabile continue acest parametru este egal cu numărul de cazuri minus 1.
Excel T.INV(probability, deg_freedom) – calculează abscisa (deci valoarea t)
corespunzătoare probabilității cerute și a gradelor de libertate ce definesc distribuția). Formula de calcul a intervalului de confidență se păstrează aproximativ , în sensul că
în loc de Z folosim t. Iată în tabelul din dreapta pentru comparare Cele două distribuții Z și t calculate în paralel:
n
StX
n
StX )2/1()2/1(
Comparativ t vs Z prob=0.975 volum invers-t invers-Z
10 2.262157 1.959964 30 2.04523 1.959964 50 2.009575 1.959964
150 1.976013 1.959964 300 1.96793 1.959964

Excel Funcții pentru calculul intervalului de confidență al mediei – variabilă continuă: Pentru calculul intervalului de confidență în Excel avem funcțiile dedicate : CONFIDENCE.T(alpha,standard_dev,size) – care folosește distribuția t pentru determinarea intervalului de confidență. Aceasta calculează precizia deci valoarea : - n este volumul eșantionului Pentru aproximare normală avem: CONFIDENCE.NORM(alpha,standard_dev,size) – care folosește distribuția normalizată (standardizată) de tip Gauss. Se calculează precizia cu formula:
S/sqrt(n)2,n-1)T.INV(1-α
n
St
/
:Excelîn,)2/1(
S/sqrt(n)2)(1-αNORM.S.INV
nZ
/
:Excelîn,)2/1(
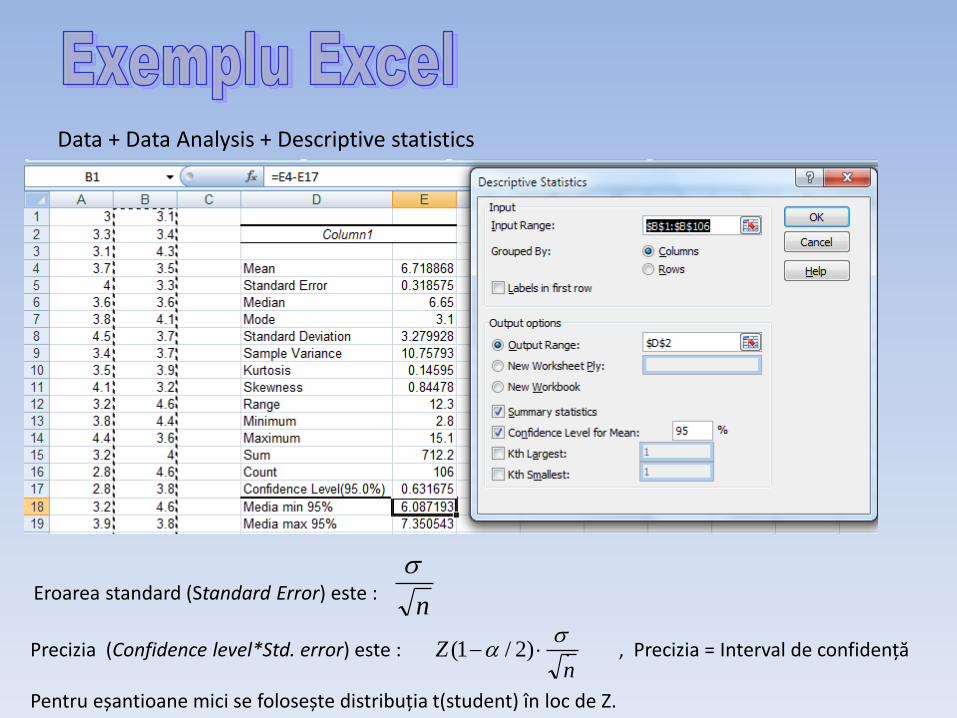
Data + Data Analysis + Descriptive statistics
Eroarea standard (Standard Error) este :
Precizia (Confidence level*Std. error) este : . , Precizia = Interval de confidență Pentru eșantioane mici se folosește distribuția t(student) în loc de Z.
n
nZ
)2/1(
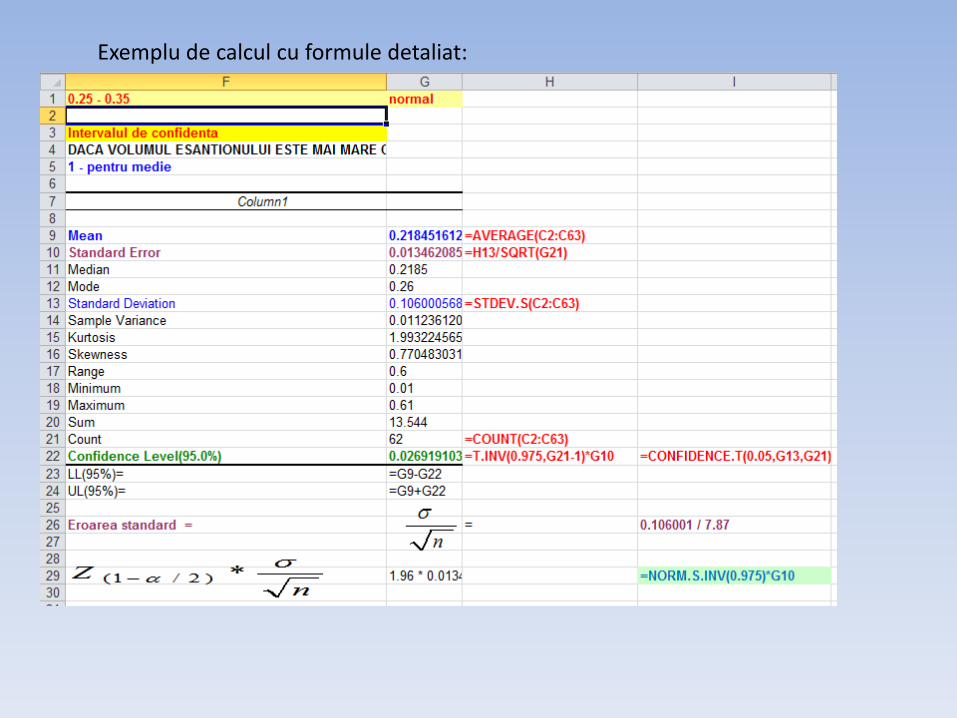
Exemplu de calcul cu formule detaliat:

Exemplu de calcul cu rezultate comparative:

Observație Calculul intervalului de confidență este util și în compararea seturilor de date. Dacă intervalele de confidență nu se suprapun, atunci sigur avem diferențe
semnificative între seturile de date – dacă nivelul de confidență de estimare este standard de 95% atunci semnificație statistică în compararea datelor este mai mică ca 5% adică probabilitatea p calculată este p<0.05 – ceea ce este dese ori de dorit (de exemplu putem compara seturile de date înainte și după tratament)

SPSS Metodă de determinare a intervalului de confidență în SPSS Se lansează: Analyze+Descriptive Statistics+Explore

3. Intervalul de încredere determinat prin metoda neparametrică bootstrap Tehnica bootstrap constă în generarea de subseturi de date chiar din lotul sursă,
folosind alegeri de tip aleatoriu (metoda Monte Carlo). Noile seturi sunt formate din elementele eșantionului sursă, iar dacă selecția este cu înlocuire (elementul ales este reintrodus în sursă) atunci apare posibilitatea ca un element să se găsească de mai multe ori într-un set nou.
Metoda bootstrap aplicată pentru determinarea intervalului de confidenţă pentru
medie poate fi prezentată prin următorii paşi: 1 – se generează conform tehnicii cunoscute n eşantioane. 2 – se calculează media pentru fiecare eşantion generat. 3 – se ordonează mediile calculate crescător. 4 – se determină ordinea din şir a mediilor ce reprezintă limitele intervalului pentru
nivelul de confidenţă stabilit.

Exemplu Presupunem ca generăm 100 eşantioane şi ne interesează intervalul de confidenţă
90% pentru medie. Primii trei paşi prezentaţi se realizează relativ uşor după care determinăm ordinea din cadrul şirului pentru limitele minimă respectiv maximă a intervalului.
Pentru 90% confidenţă rezultă elementele de pe poziția 5% respectiv 95%. Pentru un volum de dimensiune n, calculăm n*5/100 respectiv n*95/100.
În cazul nostru avem chiar pozițiile 5 respectiv 95, astfel din şirul ordonat crescător se citesc limita inferioară adică a 5-a respectiv limita superioară așadar poziția a 95-a.
Excel Metodă: 1 – Se definește setul sursă cu un nume (variabilă): Formulas+Define Name. În acest
fel lucrăm optim (ex. numim sursa esantion). 2 – Se aplică funcția INDEX(array, row_num, [column_num]) pentru a alege aleatoriu
valori din setul denumit mai devreme. Numărul rândului respectiv a coloanei sunt valori întregi. Pentru a avea o alegere
aleatoare avem funcția rand() care generează aleatoriu un număr zecimal în domeniul [0,1).
Ca urmare funcția ce alege aleator se poate scrie astfel: =INDEX(esantion,ROWS(esantion)*RAND()+1,COLUMNS(esantion)*RAND()+1) Obs. Se adaugă 1 deoarece rand() poate genera valoarea 0 – rând sau coloană 0 nu
există.
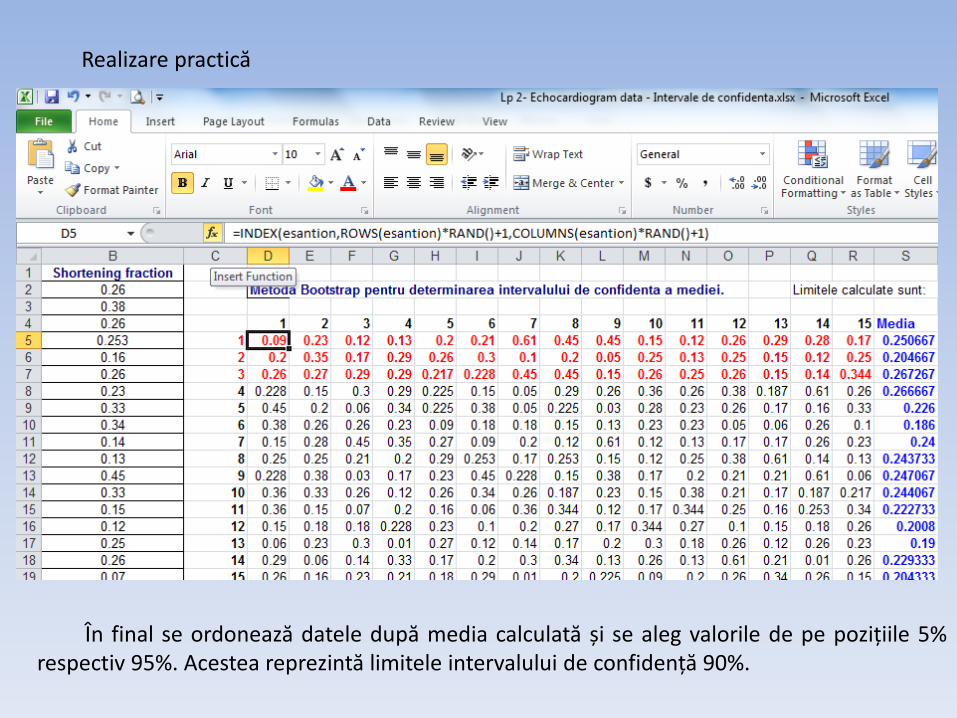
Realizare practică
În final se ordonează datele după media calculată și se aleg valorile de pe pozițiile 5% respectiv 95%. Acestea reprezintă limitele intervalului de confidență 90%.

Intervalul de încredere pentru proporţia unei variabile aleatoare. Suntem în situaţia estimării intervalul de confidenţă pentru o proporţie. Proporţia
poate fi asemănată cu o medie, iar metodele de lucru pot fi transpuse în acest context. Evident, ca în cazurile deja prezentate, nu putem studia în totalitate populaţia şi apelăm la informaţia cuprinsă într-un eşantion. Calculăm proporţia dedusă din lot şi aflăm limitele intervalului de variaţie a mediei.
Problema se repetă şi generic putem considera un set format din mai multe
eşantioane pentru care calculăm şi studiem proporţia de realizare a unui anumit eveniment de interes.
În situaţia în care loturile sunt consistente în informaţie, deci conţin date în număr
suficient pentru a păstra proprietăţile populaţiei, distribuţia mediilor este de tip normal şi putem calcula relativ uşor limitele de confidenţă.
Se pleacă de la formula generală ce exprimă probabilitatea pentru o distribuţie normală.
Notăm: P - probabilitatea, p - proporţia din eşantion, π - proporţia reală a populaţiei, α - nivelul semnificaţiei ce este de 5% de obicei.

121 zZzP
Media proporţiilor este repartizată normal si are dispersia σ ce poate fi aproximată cu formula:
Trebuie să normalizăm variabila aleatoare proporţie, deci trebuie să scădem valoarea p
măsurată din eşantion şi să împărţim la dispersie. Obţinem astfel variabila normalizată: Înlocuind în prima formulă avem: În final deducem: - metoda Wald. Observaţie Determinarea intervalului prin metoda Wald este acceptabilă doar în situaţia în care este
îndeplinită condiţia: n∙p ∙(1-p) ≥ 10. Dacă ţinem cont de faptul că produsul p ∙(1-p), pentru p reprezentând un număr pozitiv
subunitar, este maxim dacă p=0.5, deducem volumul minim al eşantionului de lucru. Avem astfel : n ∙ 0.25 ≥ 10 => n ≥ 40.
n
pp
1
Intervalul de confidență se determină punând condiția:
pZ
2/2/
z
pz
n
ppzp
12/1

Făcând un studiu amănunţit asupra estimării intervalului de confidenţă, se observă că pentru valori ale proporţiei mai mici decât 0.2 respectiv mai mari ca 0.8 eroarea se măreşte considerabil. Astfel s-au propus şi determinat noi metode de calcul a limitelor intervalului de confidenţă care funcţionează corect pentru eşantioane mici de până la 20 de cazuri. Rezultate mai bune pentru astfel de situaţii s-au obţinut folosind formulele de calcul: Wilson, Agresti-Coull, sau verosimilitatea maximă a raportului.
Intervalul proporției p=n1/n poate fi astfel calculat: Wilson: Agresti-Coull: , unde
22/1
2/1
~1~~
zn
ppzp
2
2
1
2/1
2/12
1
~
zn
zn
p

Interval de confidență pentru raportul cotelor (ODD RATIO) Cota este raportul dintre probabilitatea ca un eveniment să se realizeze și probabilitatea ca acel eveniment să nu se realizeze: Este un număr mai mare ca 0 ! Raportul cotelor = Cota pentru grupul expuși factorului: Cota pentru grupul neexpuși factorului: Astfel raportul cotelor (ODD RATIO):
)(1
)(
)(
)(
AP
AP
AP
APCA
),0[ AC
2
1
grupulpentruC
grupulpentruC
A
A
AFECȚIUNE
+ - total
FACTOR
+ a b a+b
- c d c+d
total a+c b+d a+c+b+d b
a
bab
baaCAF
)/(
)/(
d
c
dcd
dccCAF
)/(
)/(
cb
daOR

Trebuie să cunoaștem tipul de distribuție a raportului cotelor pentru a putea determina intervalul de confidență. Formula de calcul este standard:
VALUARE PUNCTUALĂ ± NIVEL DE CONFIDENȚĂ * EROARE STANDARD Este demonstrat că logaritmul natural din raportul cotelor are o distribuție normală. Ca urmare se va logaritma , se va calcula intervalul de confidență apoi se va exponenția pentru a reveni la raportul cotelor. Eroarea standard pentru LN(OR) este : Pentru LN(OR) avem intervalul de confidență: În final: OR(limita inf.) este: OR(limita sup.) este:
dcbaES ORLN
1111)(
dcba
zORLN1111
)( 2/1
dcbazORLN
1111)(exp 2/1
dcbazORLN
1111)(exp 2/1

Interval de confidență pentru riscul relativ (RISK RATIO) Riscul este probabilitatea ca un eveniment să se realizeze. Este un număr mai mare ca 0 și mai mic ca 1: Raportul riscurilor = Riscul pentru grupul expuși factorului: Riscul pentru grupul neexpuși factorului: Astfel raportul cotelor (RISK RATIO):
)(APRA
]1,0[AR
2
1
grupulpentruR
grupulpentruR
A
A
AFECȚIUNE
+ - total
FACTOR
+ a b a+b
- c d c+d
total a+c b+d a+c+b+d ba
aRAF
dc
cRAF
)(
)(
bac
dcaRR

Este demonstrat că logaritmul natural din raportul riscurilor are o distribuție normală. Ca urmare se va logaritma , se va calcula intervalul de confidență apoi se va
exponenția pentru a reveni la raportul riscurilor. Eroarea standard pentru LN(RR) este : Se aplică același algoritm de estimare ca în cazul OR doar eroarea standard diferă. În final obținem: RR(limita inf.) este: RR(limita sup.) este: Observație Intervalul de confidență atât pentru RR cât și pentru OR este simetric în forma
logaritmică ! În forma normală acest interval nu este simetric.
)()()(
bcc
d
baa
bES RRLN
)()()(exp 2/1
bcc
d
baa
bzRRLN
)()()(exp 2/1
bcc
d
baa
bzRRLN

Interpretare Dacă intervalul de confidență pentru RR sau OR cuprinde valoarea 1 înseamnă că
nu există asociere între cele două variabile (afecțiune și factor risc). Dacă limita inferioară a RR sau OR pentru interval de confidență (cu 0.95
încredere) este mai mare ca 1 atunci efectul expunerii este negativ ducând la o creștere a probabilității de îmbolnăvire.
Dacă limita superioară a RR sau OR pentru interval de confidență (cu 0.95
încredere) este mai mică ca 1 atunci efectul expunerii este pozitiv (benefic) ducând la o scădere a probabilității de îmbolnăvire.
