arhitectura sistemelor paralele - catedra de fizica...
TRANSCRIPT

Arhitectura sistemelor paralele
● Curs: George Alexandru NEMNEŞ [email protected]
Tel. 021 457 5141
● Seminar/Laborator:
Adela NICOLAEV [email protected]
George Alexandru NEMNEŞ
Tudor Luca MITRAN [email protected]
Lucian ION [email protected]

Conţinut
● Introducere – noţiuni fundamentale● Crearea/configurarea unui cluster de calcul
paralel● Tehnici de programare paralelă
– Message Passing Interface (MPI)
– MPI + C – tehnici de paralelizare
– Exemple

Abac chinezesc (2500 î.e.n.)
Carul care arata sudul (1115 î.e.n.)
Mecanismul Antikythera (125 î.e.n.)
Calculator mecanic, Blaise Pascal (1642)
Masina diferentială i Masina analitică ș
concepute de Charles Babbage
(1822)
Conceptul de masina de calcul universala, Alan Turing (1936)
INTRODUCERE - Exemple istorice de sisteme de calcul
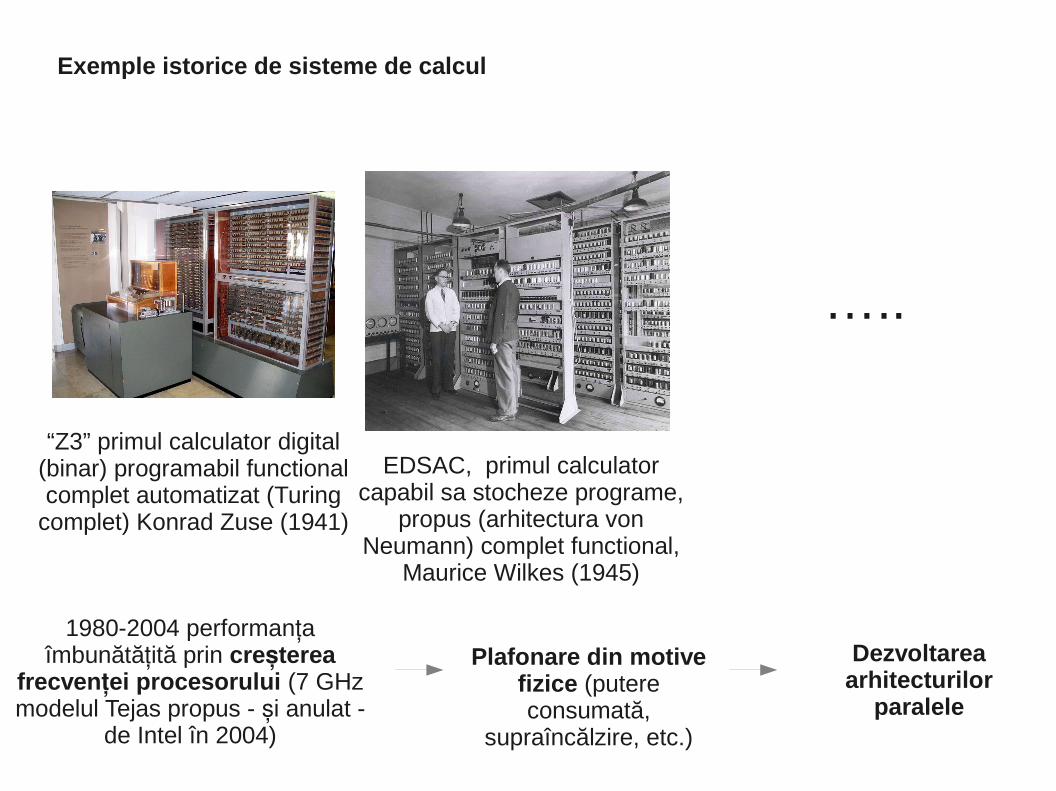
“Z3” primul calculator digital (binar) programabil functional complet automatizat (Turing
complet) Konrad Zuse (1941)
EDSAC, primul calculator capabil sa stocheze programe,
propus (arhitectura von Neumann) complet functional,
Maurice Wilkes (1945)
…..
1980-2004 performan a țîmbunătă ită prin ț cre terea ș
frecven ei procesorului ț (7 GHz modelul Tejas propus - i anulat - ș
de Intel în 2004)
Plafonare din motive fizice (putere consumată,
supraîncălzire, etc.)
Dezvoltarea arhitecturilor
paralele
Exemple istorice de sisteme de calcul

Programare paralelă
Scop:
- rezolvarea numerică a unor probleme care solicită putere foarte mare de calcul, spaţiu RAM şi de stocare de date foarte mari.
Câteva exemple “clasice”:● Predicţii meteorologice, bazate pe modele matematice complexe● Simularea efectelor accidentelor în industria constructoare de automobile● Design în industria aeronautică (metoda elementelor finite)● Design de noi medicamente în industria farmaceutică● Grafică computerizată pentru industria filmului şi marketing (advertising)● Simulări ştiinţifice în fizică, chimie şi biologie
- în unele cazuri dintre cele menţionate simularea numerică este practic singura calepentru obţinerea rezultatelor dorite (predicţia vremii, analiza dinamicii plăcilor tectonice, simulări ştinţifice);
- în altele simularea numerică produce rezultate precise cu un efort financiar multmai mic (industria auto şi aeronautică, probleme complicate în fizica particulelorelementare, etc.)
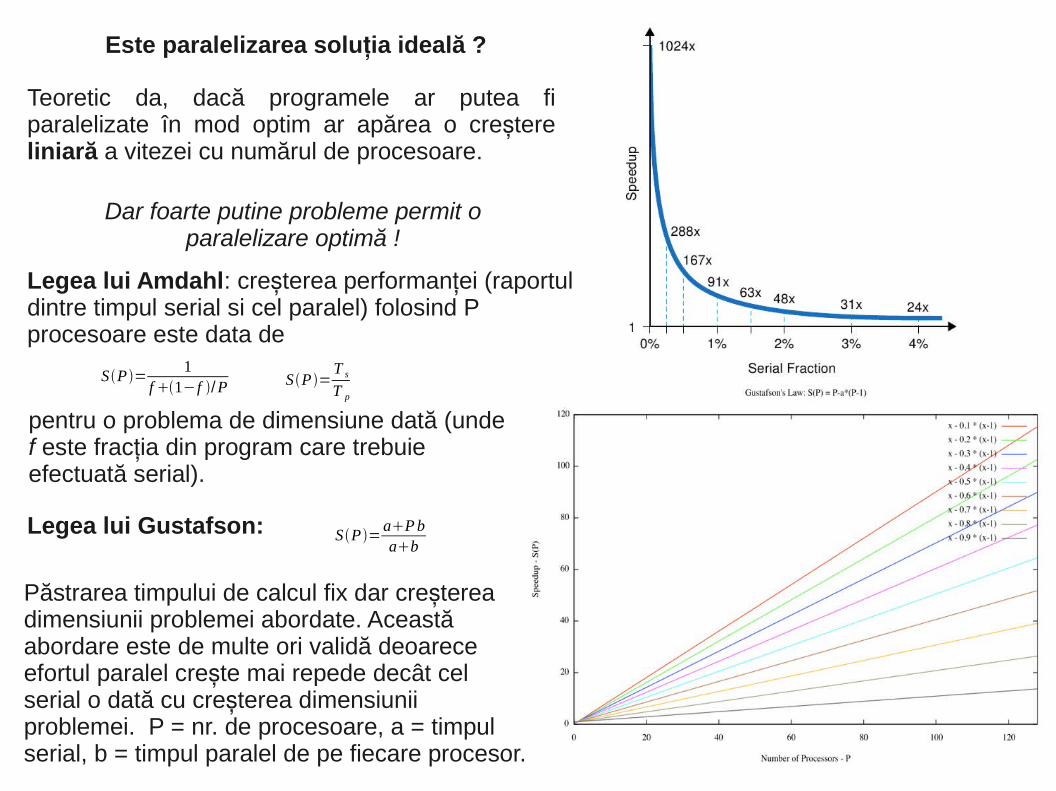
Este paralelizarea solu ia ideală ?ț
Teoretic da, dacă programele ar putea fi paralelizate în mod optim ar apărea o cre tere șliniară a vitezei cu numărul de procesoare.
Dar foarte putine probleme permit o paralelizare optimă !
Legea lui Amdahl: cre terea performan ei (raportul ș țdintre timpul serial si cel paralel) folosind P procesoare este data de
SP =1
f1− f /P
pentru o problema de dimensiune dată (unde f este frac ia din program care trebuie țefectuată serial).
Legea lui Gustafson: SP =aPbab
SP =T s
T p
Păstrarea timpului de calcul fix dar cre terea șdimensiunii problemei abordate. Această abordare este de multe ori validă deoarece efortul paralel cre te mai repede decât cel șserial o dată cu cre terea dimensiunii șproblemei. P = nr. de procesoare, a = timpul serial, b = timpul paralel de pe fiecare procesor.

Exemple de sisteme capabile de calcul paralel
Supercomputer Tianhe-2: 3,120,000 miezuri,
1375 TiB RAM, consum 33.8 Pflops,17.6 MW,
$390 mil.
Creierul uman: 100 miliarde neuroni, 150,000-180,000 km de
fibre acoperite cu mielină, 15x1013 sinapse, 20W
CPU (Intel Xeon E7): 10 miezuri, 2.4 GHz,
130W, $5000
GPU (NVIDIA Titan): 2688 miezuri, 6 GB
RAM, 1.5 Tflops, 250W, $1000
FPGA (Field Programmable Gate Array): circuite logice reconfigurabile, cai de
procesare paralele
Coprocesoare CPU (Intel Xeon Phi 7100):
61 miezuri, 1.2 GHz, 16 GB RAM, 1.2 Tflops,
300W, $4000
Retea neuronala implementată
hardware (CogniMem CM1K):
4X1024 neuroni artificiali, ~0.15 TFlops, $3000
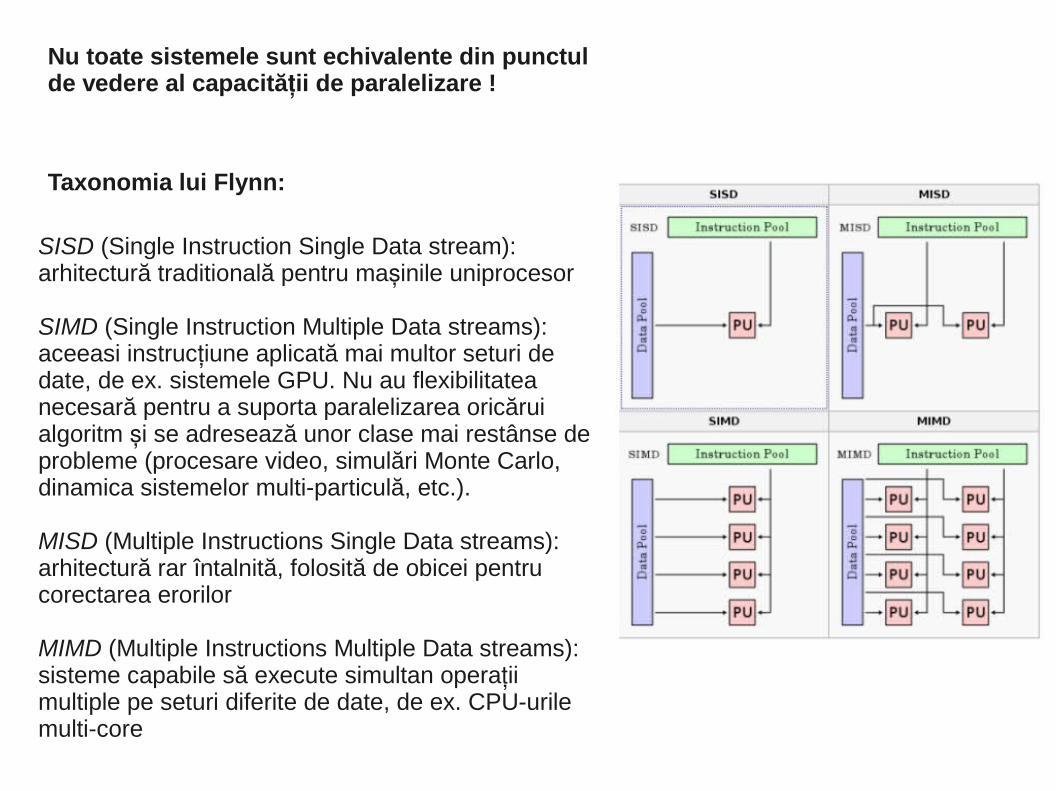
Nu toate sistemele sunt echivalente din punctul de vedere al capacită ii de paralelizare !ț
Taxonomia lui Flynn:
SISD (Single Instruction Single Data stream): arhitectură traditională pentru ma inile uniprocesorș
SIMD (Single Instruction Multiple Data streams): aceeasi instruc iune aplicată mai multor seturi de țdate, de ex. sistemele GPU. Nu au flexibilitatea necesară pentru a suporta paralelizarea oricărui algoritm i se adresează unor clase mai restânse de șprobleme (procesare video, simulări Monte Carlo, dinamica sistemelor multi-particulă, etc.).
MISD (Multiple Instructions Single Data streams): arhitectură rar întalnită, folosită de obicei pentru corectarea erorilor
MIMD (Multiple Instructions Multiple Data streams): sisteme capabile să execute simultan opera ii țmultiple pe seturi diferite de date, de ex. CPU-urile multi-core

Hardware
Context:
- Toţi marii producători comercializează procesoare cu mai multe unităţi eficiente de calcul(cores) împachetate într-un singur chip; practic şi un PC este în acest moment un mic sistem paralel;
- Soluţii tehnologice inovative, care permit integrarea unui număr foarte mare (~100 K) deunităţi de calcul, cunoscute sub denumirea generică
HPC – High Performance Computing
- Dezvoltarea tehnologiilor IT de comunicaţii (Ethernet gigabyte, Infiniband, comunicaţiipe fibră optică) face posibil transferul eficient de date între unităţi de calcul distincte.

Un supercomputer este un computer special complex, compus din mai multe procesoare care accesează aceea i memorie centrală i care func ionează concomitent i coordonat, în ș ș ț școopera ie strânsă, astfel încât supercomputerul poate atinge o mare performan ă totală de ț țcalcul. Modul de calcul al supercomputerelor se nume te "calcul paralel". Numărul de procesoare șinterconectate ale unui supercomputer depă e te la anumite modele chiar i 100.000. Pentru ș ș șcompara ie, un computer normal, numit de tip "scalar", con ine un singur procesor central.ț ț
http://ro.wikipedia.org/wiki/Supercomputer
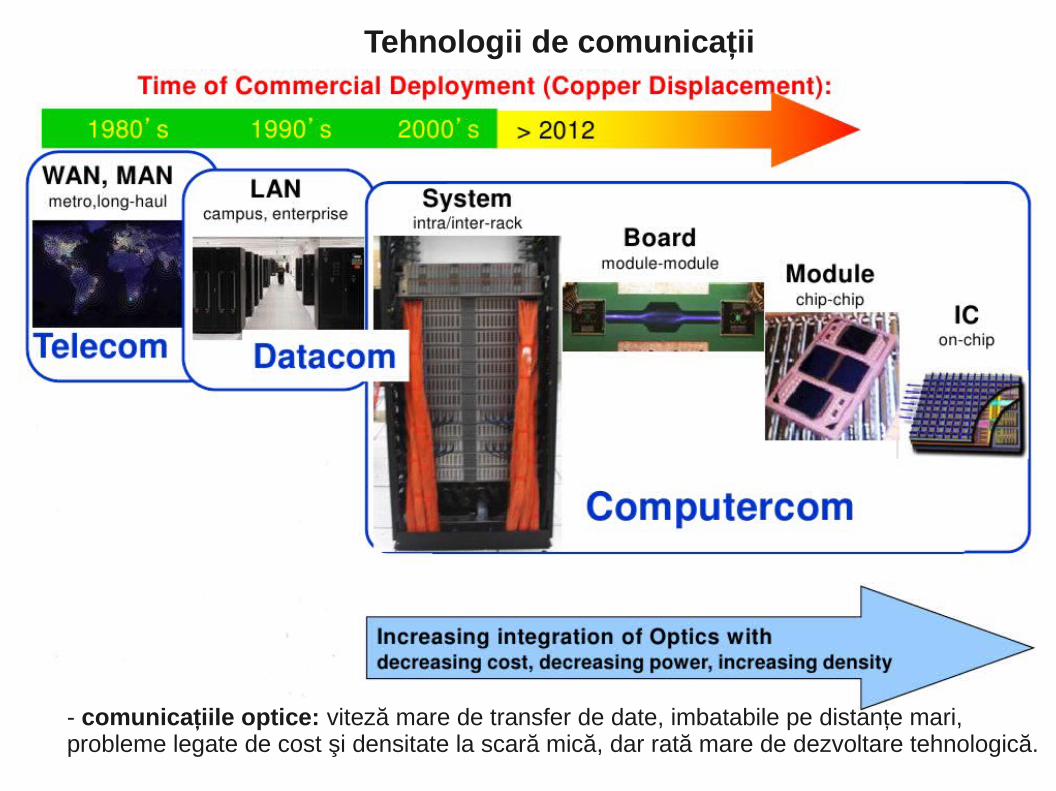
- comunicaţiile optice: viteză mare de transfer de date, imbatabile pe distanţe mari, probleme legate de cost şi densitate la scară mică, dar rată mare de dezvoltare tehnologică.
Tehnologii de comunicaţii
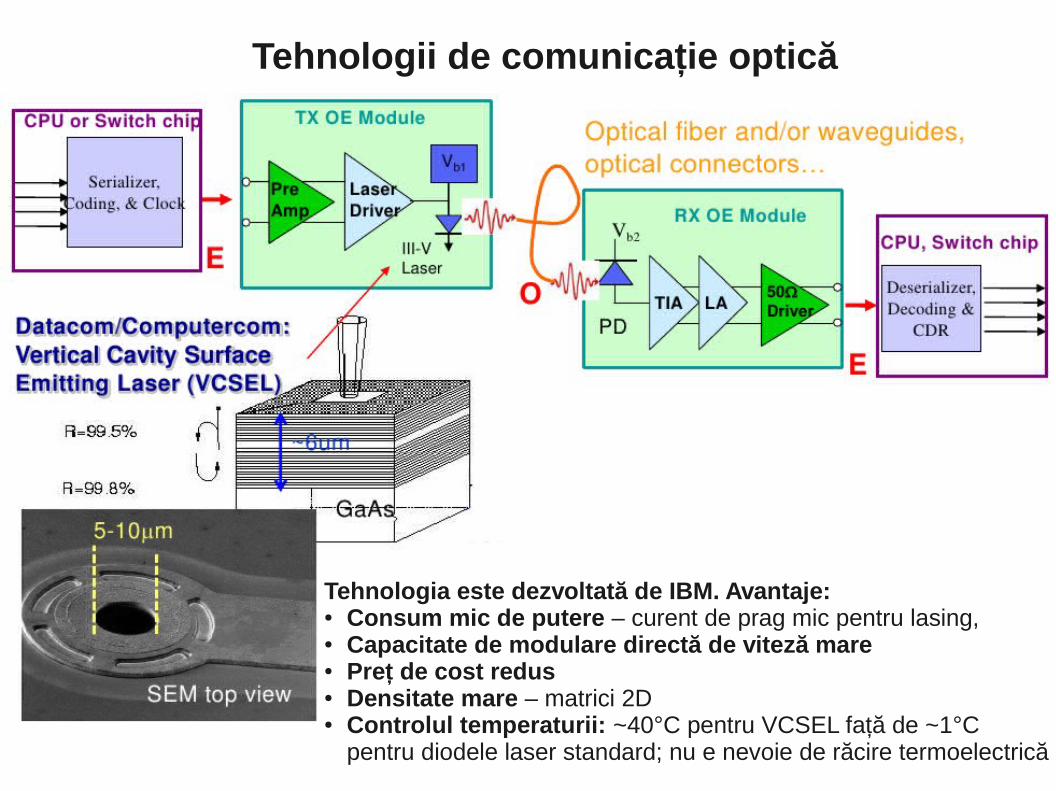
Tehnologia este dezvoltată de IBM. Avantaje:● Consum mic de putere – curent de prag mic pentru lasing, ● Capacitate de modulare directă de viteză mare● Preţ de cost redus● Densitate mare – matrici 2D● Controlul temperaturii: ~40°C pentru VCSEL faţă de ~1°C
pentru diodele laser standard; nu e nevoie de răcire termoelectrică
Tehnologii de comunicaţie optică

Row 1 Row 2 Row 3 Row 40
2
4
6
8
10
12
Column 1Column 2Column 3
- Comunicaţie integral optică! (tehnologie VCSEL)

Raport Intel: “... în 2015 un procesor tipic va consta din zeci-sute de miezuri. O parte vor fidestinate unor sarcini specifice (criptare/decriptare de date, transmisie de date, grafică),dar majoritatea vor fi disponibile aplicaţiilor utilizatorilor, oferind un potenţial uriaş caperformanţă” 1
Programare paralelă – concepte de bază
- design-ul unui algoritm paralel presupune divizarea operaţiilor de calcul dintr-o aplicaţie în părţi numite sarcini (tasks) care pot fi rulate în paralel;
- dimensiunea unei sarcini (în termeni de număr de instrucţiuni) se numeşte granularitate. Definirea sarcinilor unei aplicaţii şi a granularităţii lor revine programatorului, reprezintă principalul effort în dezvoltarea unui program şi este dificil de automatizat. - potenţialul de paralelizare – este o proprietate inerentă a unui algoritm, care determină înUltimă instanţă definirea sarcinilor.
- sarcinile unei aplicaţii, codate într-un limbaj de programare, sunt atribuite unor procese sau fire de execuţie (threads) lansate pe unităţile fizice de calcul. Atribuirea sarcinilor către procese se numeşte planificare (scheduling) şi defineşte ordinea lor de execuţie.
- atribuirea şi lansarea proceselor pe unităţile de calcul fizice (mapping) revine sistemului de operare dar pot fi controlate de programator.
- programele paralele au nevoie de sincronizare (coordonarea proceselor pentru a fi corectexecutate)
1 D. Kuck. Platform 2015 Software-Enabling Innovation in Parallelism for the Next Decade. Intel White Paper, Technology@Intel Magazine, 2005

Programare paralelă – concepte de bază
- Clasificare a sistemelor de calcul paralel după modul de organizare al memoriei RAM
● Sisteme cu memorie partajată (shared memory) – cu care este de obicei asociată noţiunea de fir de execuţie (thread). RAM-ul este global disponibil tuturor procesoarelorsau miezurilor de calcul.
● Sisteme cu memorie distribuită (distributed memory) – cu care este de obicei asociată noţiunea de proces. RAM-ul este accesibil doar unui singur procesor
Probleme de rezolvat
- la nivelul sistemului de calcul
● Cum sunt distribuite procesele?● Middleware -strat software între sistemul de operare şi aplicaţii într-un sistem de
calcul distribuit (soft-urile de tip GRID – Condor, TORQUE, etc.)
● Cum se realizează planificarea şi comunicarea între procese?● Pentru arhitecturi cu spaţiu de adrese distribuite – Message Passing Interface
(MPI), de departe cea mai populară soluţie de programare în acest moment.Implementări open-source populare: MPICH2, OpenMPI.
Clusterul de calcul paralel de la Departamentul de Electricitate, Fizica solidului şi Biofizică al Facultăţii de Fizică
● Sistem de operare: Linux Debian “Wheezy”, 64-bit
● Server NFS: parte a kernel-ului Linux, compilat ca un modul al kernel-ului în distribuţiile DebianNFS (Network File System) este un protocol care permite accesul la distanţă la un sistem de fişiere (filesystem) prin reţea. Toate sistemele de tip UNIX implementează acest protocol.
NFS HowTo minimal:- pe server, pentru instalare, se rulează ca superuser:
root@poseidon:~/#apt-get install nfs-kernel-server nfs-common portmap
- pe client, pentru instalare, se rulează ca superuser:
root@hermes:~/#apt-get install nfs-common portmap
Pentru o documentare exhaustivă, a se vedea: http://nfs.sourceforge.net/nfs-howto/ar01s02.html#whatis_nfs

NFS HowTo minimal
- Exemplu: fişierul de configurare /etc/default/nfs-kernel-server (defineşte comportamentulserverului. ATENŢIE: serverul NFS utilizează UID-ul unui user la definirea tipului de accesla fişiere şi nu numele lui!!! Dacă e nevoie de info suplimentar asupra acestui subiect...)
# Number of servers to start upRPCNFSDCOUNT=8
# Runtime priority of server (see nice(1))RPCNFSDPRIORITY=0
# Options for rpc.mountd.# If you have a port-based firewall, you might want to set up a fixed port here using the --port option. # For more information, see rpc.mountd(8) or http://wiki.debian.org/SecuringNFS. To disable NFSv4 # on the server, specify '--no-nfs-version 4' hereRPCMOUNTDOPTS="--manage-gids --port 2048"
# Do you want to start the svcgssd daemon? It is only required for Kerberos exports. Valid # alternatives are "yes" and "no"; the default is "no".NEED_SVCGSSD=
# Options for rpc.svcgssd.RPCSVCGSSDOPTS=

- Exemplu: fişierul de configurare /etc/default/nfs-common (conţine info despre porturile de comunicare client-server, etc.)
# If you do not set values for the NEED_ options, they will be attempted# autodetected; this should be sufficient for most people. Valid alternatives# for the NEED_ options are "yes" and "no".
# Do you want to start the statd daemon? It is not needed for NFSv4.NEED_STATD=
# Options for rpc.statd.# Should rpc.statd listen on a specific port? This is especially useful# when you have a port-based firewall. To use a fixed port, set this# this variable to a statd argument like: "--port 4000 --outgoing-port 4001".# For more information, see rpc.statd(8) or http://wiki.debian.org/SecuringNFSSTATDOPTS="--port 2046 --outgoing-port 2047"
# Do you want to start the idmapd daemon? It is only needed for NFSv4.NEED_IDMAPD=
# Do you want to start the gssd daemon? It is required for Kerberos mounts.NEED_GSSD=
NFS HowTo minimal

NFS HowTo minimal- sistemul de fisiere exportat este definit pe server de conţinutul fişierului /etc/exports
Acest fişier conţine o listă a directoarelor disponibile pentru acces în reţea (exportate).Sintaxa generală a unei clauze de export este:
/director/de/exportat destinaț ia1(optiunea1,opț iunea2,...) destinaț ia2(...) ...
- Exemplu (man exports(5) pentru toate opţiunile) - să presupunem că programele şi bibliotecile de funcţii cele mai populare printre utilizatorii clusterului sunt stocateîn directorul /usr/local/HPC, care trebuie deci exportat pentru a se asigura accesulla ele într-un mod uniform:
/usr/local/HPC 192.168.7.0/24(rw,root_squash,subtree_check)
Clauza de mai sus determină exportarea directorului /usr/local/HPC către toate maşinile din subreţeaua de clasă C 192.168.7.0 . ATENŢIE: nu se lasă spaţiu între destinaţie şi parantezacare defineşte opţiunile de export!!!Opţiunea rw – permite acces la modul citire/scriereOpţiunea sync – serverul acceptă o nouă cerere NFS numai după completarea operaţiei de acces la disc curenteOpţiunea root_squash – serverul refuză accesul la sistemul de fişiere exportat la nivel de superuser (root)Opţiunea subtree_check – serverul verifică dacă fişierul accesat este în arborele de directoareexportate (directorul exportat sau subdirectoare ale sale).
Destinaţia poate fi identificată fie printr-un nume DNS, fie prin adresa IP. O întreagă subreţeaPoate fi indicată prin nume (*.exemplu.org) sau prin interval de IP-uri (192.168.0.0/24 sau192.168.0.0/255.255.255.0)

NFS HowTo minimal
- Pe client: sistemul de fişiere exportat poate fi montat în structura sistemului de fişiere local manual (ca superuser, presupunând că serverul NFS rulează pe maşina cu IP-ul 192.168.7.14):
root@hermes~# mount -t nfs -o rw,nosuid 192.168.7.14:/usr/local/HPC /usr/local/HPC
- Pentru a face permanentă opţiunea de montare la repornirea sistemului client local se adaugă în fişierul de configurare a ierarhiei locale /etc/fstab linia:
192.168.7.14:/usr/local/HPC /usr/local/HPC nfs rw,nosuid 0 0
La pornirea sistemului de operare local, linia precedentă are acelaşi efect ca la montarea manuală descrisă mai sus.
Directorul /usr/local/HPC de pe maşina 192.168.7.14 este montat în sistemul de fişiere localsub /usr/local/HPC (putea fi un director cu un alt nume). Directorul destinaţie trebuie să existe.Opţiunea nosuid este una de protecţie, menită să şteargă biţii setuid şi setgid din programelestocate pe server.

SSH HowTo minimal
- SSH (Secure Shell) este un protocol pentru acces securizat la nivel de user (login) saupentru alte servicii de reţea (FTP, NFS, etc.) printr-o reţea nesigură. OpenSSH este cea maicunoscută şi utilizată implementare a protocolului.SSH funcţionează prin schimbarea şi verificarea informaţiilor între client şi server, folosind “chei” publice şi private pentru a identifica în mod corect maşini de calcul şi utilizatori. După stabilirea conexiunii comunicaţia client server este criptată cu ajutorul cheilor publică/privată. La nici un moment de timp, inclusiv la stabilirea conexiunii, cheile de criptarenu sunt transmise prin reţea, ele fiind transferate în prealabil între server şi client.
ssh_config : fişierul de configurare al programului clientsshd_config : fişierul de configurare al serverului
- se instalează programele server şi client pe fiecare dintre maşini:
[email protected]# apt-get install openssh-server [email protected]# apt-get install openssh-server openssh-client
Fişierele de configurare principale (masiv comentate, de o manieră absolut explicită, care nucere explicaţii suplimentare) sunt plasate în directorul /etc/ssh:
Să presupunem că se doreşte stabilirea comunicaţiei SSH bidirecţionale între maşinileA: 192.168.7.30B: 192.168.7.31ambele rulând Debian Wheezy.

SSH HowTo minimal
- Directorul /etc/ssh conţine perechile de chei publică/privată care identifică serverul(vezi output-ul comenzii ls -l /etc/ssh)
[email protected]$ ssh-keygen -t [email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.7.31
după care se cere parola. Dacă numele de utilizator este acelaşi pe cele două maşini, este suficient:
[email protected]$ ssh 192.168.7.31
- fără parolă, cu chei distribuite:
După lansarea serverului în execuţie, conexiunea se poate stabili în două moduri:
- cu parolă
ssh_host_dsa_keyssh_host_dsa_key.pubssh_host_rsa_keyssh_host_rsa_key.pub

SSH HowTo minimal
[email protected]$ ssh-keygen -t [email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.7.31
A doua comandă copiază cheia publică /home/student/.ssh/id_rsa.pub de pe maşina 192.168.7.30 locală pe care a fost generată, pe maşina la distanţă 192.168.7.31, adăugând-o fişierului /home/student/.ssh/authorized_keys de pe aceasta. Repetând aceeaşi manevră pe maşina B:
- fără parolă, cu chei distribuite:
Prima dintre comenzile de mai sus creează în directorul /home/student/.ssh perecheade chei publică/privată
id_rsa.pubid_rsa
[email protected]$ ssh-keygen -t [email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.7.30
se obţine accesul securizat prin tunel SSH între cele două maşini, A şi B, bidirecţional (în ambele sensuri, de la A la B sau de la B la A).

TORQUE HowTo minimal
- TORQUE este un middleware open-source produs de Adaptive Computing. Rolul săueste acela de a distribui procesele într-un calcul paralel printre nodurile unui cluster decalcul, menţinând uniformă încărcarea resurselor de calcul disponibile. Un cluster TORQUE conţine un nod (head node) care rulează server-ul pbs_server şi daemon-ul care se ocupă cu planificarea resurselor (scheduler-ul) şi mai multe noduri de calcul, care rulează daemon-ul pbs_mom.
Utilizatorii lansează job-uri către server cu ajutorul comenzii qsub. La primirea unui job noupbs_server informează scheduler-ul pbs_sched, care caută noduri de calcul disponibile pentru lansarea noului proces şi întoarce informaţia către pbs_server. Acesta lansează procesul pe primul nod de calcul din lista indicată de pbs_sched, (nodul de execuţie), numit în limbajul TORQUE Mother Superior; celelalte noduri care participă la job se numesc Sister Moms.
Să presupunem că se doreşte configurarea unui cluster TORQUE cu 4 noduri (pentru simplitatea prezentării)
192.168.7.3 ws0 192.168.7.5 ws2192.168.7.4 ws1 192.168.7.5 ws3
toate rulând Debian Wheezy. Maşina ws0 având IP-ul 192.168.7.3 va rula server-ul (head node), iar ws1-3 vor fi noduri de calcul.

TORQUE HowTo minimal
- 1. Instalarea şi configurarea serverului:
[email protected]~# apt-get install torque-server torque-common libtorque2 \ torque-scheduler [email protected]~# pbs_server -t [email protected]~# echo “ ws0” > /etc/torque/server_name; qterm -t [email protected]~# pbs_server
[email protected]~# qmgr -c 'p s'
A doua comandă creează fişierul serverdb în /var/spool/torque/server_priv, şi-l iniţializeazăpentru o configurare minimală a serverului pbs_server. Comanda qterm opreşte serverul,care este apoi repornit cu noua configurare. Pentru a verifica configurarea:
care produce un output de tipul:
# Set server attributes.set server acl_hosts = ws0set server log_events = 511set server mail_from = admset server node_check_rate = 150set server tcp_timeout = 6

TORQUE HowTo minimal- 1. Instalarea şi configurarea serverului: comanda qmgr este interfaţa de administrarea serverului. Sintaxa generală:
qmgr [-a] [-c command] [-e] [-n] [-z] [server...]
Opț iune Nume Descriere---------------------------------------------------------------------------- -a --- Iese/termină la orice eroare de sintaxă sau la orice cerere
respinsă de server. -c command Execută comanda command şi iese. -e --- Trimite ecoul tuturor comenzilor la interfaț a de ieşire standard. -n --- Nu este executată nici o comandă, se efectuează doar verificarea
sintaxei. -z --- Nici un mesaj de eroare nu este transmis la interfaț a standard de
erori.
[email protected]~# qmgr> create queue batch> set queue batch queue_type = Execution> set queue batch resources_default.nodes = 1> set queue batch resources_default.walltime = 01:00:00> set queue batch enabled = True> set queue batch started = True
- 2. Finalizarea configurării iniţiale:

TORQUE HowTo minimal
[email protected]~# qmgr> create queue batch> set queue batch queue_type = Execution> set queue batch resources_default.nodes = 1> set queue batch resources_default.walltime = 01:00:00> set queue batch enabled = True> set queue batch started = True
- 2. Finalizarea configurării iniţiale: 2
Explicaţii:- prima comandă creează o “coadă” de job-uri, numită “batch”- a doua comandă precizează tipul nou-createi cozi – este una de execuţie- implicit (dacă utilizatorii nu solicită altfel) acestei cozi i se alocă 1 nod- timpul total implicit de execuţie al unui job din această coadă este de o oră (dacă utili-zatorii nu specifică altfel, orice job este terminat automat după o oră)- coada batch este activată şi apoi deschisă. Se reporneşte serverul cu noua configurare:
2 http://docs.adaptivecomputing.com/torque/help.htm#topics/1-installConfig/testingServerConfig.htm
[email protected]~# qterm -t [email protected]~# pbs_server

TORQUE HowTo minimal
[email protected]~# qmgr> # Set server attributes.set server scheduling = Trueset server acl_hosts = ws0set server managers = user1@ws0set server operators = user1@ws0set server default_queue = batchset server log_events = 511set server mail_from = admset server node_check_rate = 150set server tcp_timeout = 300set server job_stat_rate = 45set server poll_jobs = Trueset server mom_job_sync = Trueset server keep_completed = 300set server next_job_number = 0
- 3. Alte opţiuni de configurare utile: 2
2 http://docs.adaptivecomputing.com/torque/help.htm#topics/1-installConfig/testingServerConfig.htm

TORQUE HowTo minimal
node-name[:ts] [np=] [gpus=] [properties]
node-name este numele DNS al maşinii, complet calificat sau scurtat. Opț iunea [:ts] marchează nodul ca “ timeshared” ; nodul e listat de server
în raportul de stare dar nu i se alocă procese. Opț iunea [np=] specifică numărul de procesoare virtuale pe nod. Opț iunea [gpus=] specifică numărul de GPU pe nod. Remarcă: numărul de procesoare pe nod poate fi detectat automat de server
activând opț iunea auto_node_np=True cu comanda: qmgr -c set server auto_node_np = True
În acest caz valoarea din TORQUE_HOME/server_priv/nodes este neglijată. Opț iunea [properties] este un string arbitrar, folosit pentru
caracterizarea nodului.
- 4. Specificarea nodurilor de calcul - pbs_server trebuie să recunoască maşinile dinreţea care sunt configurate ca fiind nodurile sale de calcul. Fiecare nod e specificat pe olinie în fişierul $TORQUE_HOME/server_priv/nodes (TORQUE_HOME este o variabilăde mediu definită în fişierul de configurare. Implicit TORQUE_HOME=/var/spool/torque.)Structura liniei este:

TORQUE HowTo minimal
# Nodurile ws1-3 sunt noduri de calcul#ws1 np=8 RAM32GB cluster01 rack1# Nodul ws2 trebuie înlocuitws2:ts Defect_DeInlocuitws3 np=4 RAM16GB cluster01 rack1ws4 np=16 rack1
- 4. Specificarea nodurilor de calcul – exemplu de fişier $TORQUE_HOME/server_priv/nodes
- 5. Conţinutul fişierului /etc/hosts – pentru rezolvarea atributelor DNS; poate fi redistribuitpe toate nodurile de calcul
127.0.0.1 localhost192.168.7.3 ws0192.168.7.4 ws1192.168.7.5 ws2192.168.7.6 ws3

TORQUE HowTo minimal
root@ws1~# apt-get install torque-mom torque-common torque-client-x11 \libtorque2 libtorque2-dev
- 6. Instalarea/configurarea nodurilor de calcul – toate etapele de la acest punct înainte trebuie repetate pe fiecare nod
- 7. Conţinutul fişierului /etc/hosts – pentru rezolvarea atributelor DNS; poate fi redistribuitpe toate nodurile de calcul
127.0.0.1 localhost192.168.7.3 ws0192.168.7.4 ws1192.168.7.5 ws2192.168.7.6 ws3
- 8. Conţinutul fişierului /etc/torque/server_name
ws0

TORQUE HowTo minimal
$pbsserver ws0 # numele maşinii care rulează pbs_server$logevent 225 # bitmap care defineşte evenimentele de raportat
- 9. Se creează/editează fişierul de configurare a daemon-ului pbs_mom, respectiv/var/spool/torque/mom_priv/config
- 10. Se reporneşte daemon-ul pbs_mom cu noua configurare
root@ws1~# /etc/init.d/torque-mom restart
- 11. Se poate acum testa configurarea şi funcţionarea clusterului TORQUE- pe server, sunt cozile corect configurate?
root@ws0~# qstat -q
- pe server, sunt nodurile de calcul active şi raportează starea corect?
root@ws0~# pbsnodes -a
- poate fi rulat un job? ATENŢIE: A NU SE RULA CA ROOT (SUPERUSER)!
root@ws0~# su – studentstudent@ws0~$ echo "sleep 30" | qsub
TORQUE HowTo minimal
student@ws0~$ qstatJob id Name User Time Use S Queue------ ----- ---- -------- -- -----0.ws0 STDIN student 0 Q batch
- 12. Se verifică starea procesului
Lansarea job-urilorProcesele pot fi lansate de pe oricare dintre noduri, cu ajutorul comenzii qsub exemplu.sh, unde exemplu.sh conţine (acesta este un exemplu!)
#!/bin/sh## Acesta este conț inutul fişierului exemplu.sh## Configurarea mediului de lucru pentru job:#PBS -N ExampleJob#PBS -l nodes=1,walltime=00:01:00#PBS -q batch#PBS -M [email protected]#PBS -m abe# Afişează ora şi datadate# Aşteaptă 10 sec.sleep 10# Afişează din nou ora şi datadate

TORQUE HowTo minimalLansarea job-urilor – Comentarii finale- scriptul transmis cu qsub nu trebuie neapărat să fie executabil.- liniile care încep cu # sunt comentarii- liniile care încep cu #PBS sunt directive pbs, nu comentarii! Ele trebuie să apară TOATEla început, înainte de prima comandă care nu e o directivă pbs; cele care apar după ocomandă non-pbs sunt ignorate!- semnificaţia liniilor din exemplu.sh de pe slide-ul anterior:
#!/bin/sh script shell# comentariu# Acesta este conț inutul fişierului exemplu.sh comentariu# comentariu# Configurarea mediului de lucru pentru job: comentariu#PBS -N ExampleJob numele job-ului de lansat#PBS -l nodes=1,walltime=00:01:00 resurse alocate: 1 nod, timp de calcul max 1 min#PBS -q batch job-ul va fi ataşat cozii de execuț ie batch#PBS -M [email protected] adresa de e-mail unde vor fi trimise mesaje#PBS -m abe vor fi trimise e-mail-uri la lansare în execuț ie
(b), la terminare (e) şi în caz că job-ul va fi abandonat (a)
# Afişează ora şi data comentariudate job (comandă non-pbs de executat)# Aşteaptă 10 sec. comentariusleep 10 job (comandă non-pbs de executat)# Afişează din nou ora şi data comentariudate job (comandă non-pbs de executat)